JOINs
flink sql主要有四种连接方式,分别是Regular Joins、Interval Joins、Temporal Joins、lookup join
1、Regular Joins(常规连接 )
这种连接方式和hive sql中的join是一样的,包括inner join,left join,right join,full join
sql
1、指定数据源建立students表
CREATE TABLE students (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置为最新生成的数据
'format' = 'csv' -- 指定数据的格式
);
2、kafka生产students表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班
3、创建关联表scores
CREATE TABLE scores (
sid STRING,
cid STRING, --学科id
score INT
) WITH (
'connector' = 'kafka',
'topic' = 'scores', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
4、kafka生产scores数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,56
1500100002,1000001,139
1500100002,1000002,102
1500100004,1000001,42
1500100004,1000002,142
-- inner jion 两边数据都不为null的才会关联
select
a.id,a.name,b.sid,b.score
from
students as a
inner join
scores as b
on a.id=b.sid;
-- left join/right join 保证左边/右边数据的完整性
select
a.id,a.name,b.sid,b.score
from
students as a
right join
scores as b
on a.id=b.sid;
-- full join 保证两边数据的完整性
select
a.id,a.name,b.sid,b.score
from
students as a
full join
scores as b
on a.id=b.sid;
-- 注意:
-- 常规连接,会将两个表的数据一直保存在状态中,时间长了,状态会越来越大,导致任务执行失败,通常在批处理中使用,因为批处理没有状态这个概念。
为了避免状态过大可能会导致的任务失败问题,我们可以设置状态有效期
-- 状态有效期,状态在flink中保存的时间,但是如果sql中除了关联操作还有聚合这样也需要将数据保存在状态中的操作,状态有效期设置的太短可能会让聚合这样的操作失败,设置的太长延迟也会增加。所以,状态保留多久需要根据实际业务分析
SET 'table.exec.state.ttl' = '20000';
设置该参数后,那么只有在20秒内到达的数据才会被保存到状态中进行关联。inner join结果:

left join 结果:
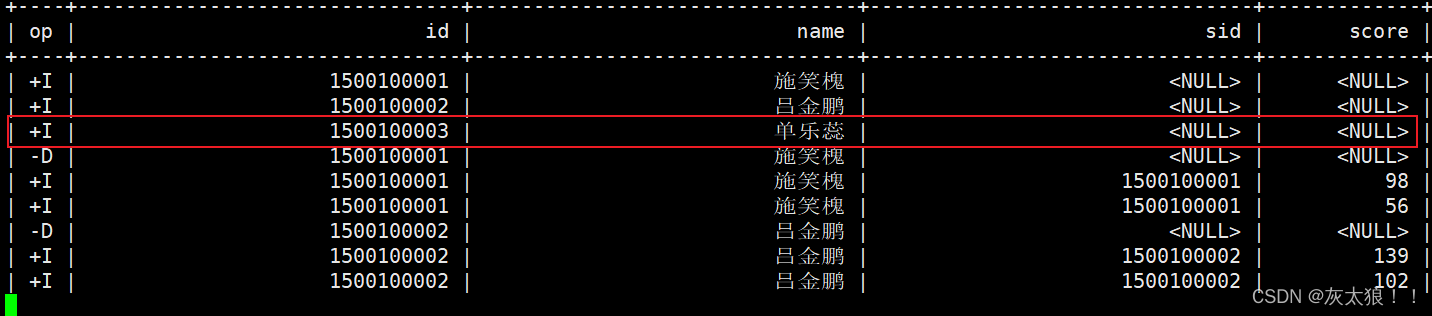
right join结果:

full join结果:
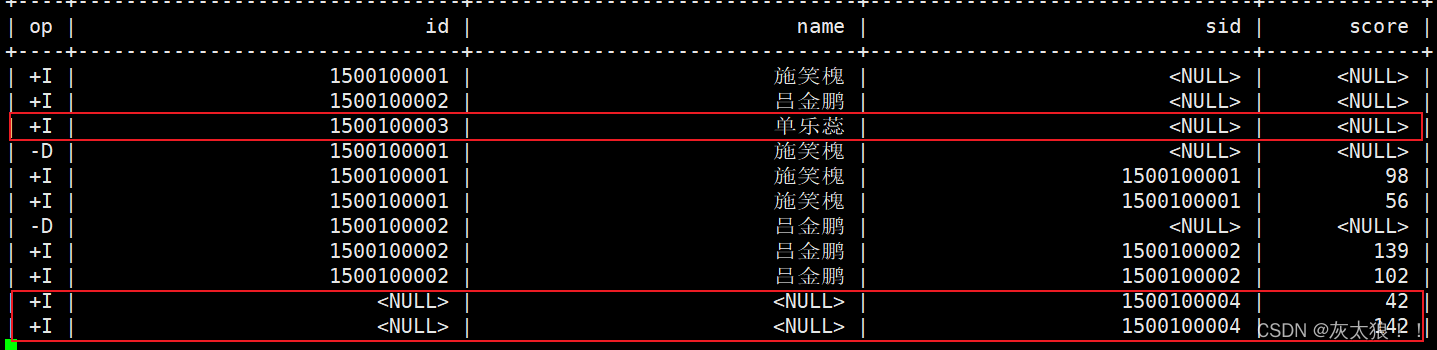
2、Interval Joins(间隔连接)
Interval Joins:在一段时间内关联
对于流式查询,与常规连接相比,间隔连接仅支持具有时间属性的追加表。由于时间属性是拟单调递增的,因此 Flink 可以从其状态中删除旧值,而不会影响结果的正确性。
这种方式可以变相弥补Regular Joins中时间长了状态过大的问题。
sql
CREATE TABLE students_proctime (
id STRING,
name STRING,
age INT,
sex STRING,
clazz STRING,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'students', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,施笑槐,22,女,文科六班
1500100002,吕金鹏,24,男,文科六班
1500100003,单乐蕊,22,女,理科六班
CREATE TABLE scores_proctime (
sid STRING,
cid STRING,
score INT,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'scores', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,56
1500100002,1000001,139
1500100002,1000002,102
1500100004,1000001,42
1500100004,1000002,142
select a.id,a.name,b.sid,b.score from
students_proctime a, scores_proctime b
where a.id=b.sid
-- a表的时间需要在b表时间10秒内或b表的时间需要在a表时间10秒内
and (
a.proctime BETWEEN b.proctime - INTERVAL '10' SECOND AND b.proctime
or b.proctime BETWEEN a.proctime - INTERVAL '10' SECOND AND a.proctime
);
3、Temporal Joins(时态连接)
这种关联方式是专门用来关联时态表的。
- Temporal Joins(时态连接)是在流式计算或数据处理中,对两个或多个随时间变化的表(也称为动态表或时态表)进行连接的操作。这些表包含随时间变化的数据,并且行与一个或多个时态周期相关联。
在我们生活中最常见的时态表就是汇率表,汇率随着时间变化而变化。
案例:
例如,假设我们有一张订单表,每张订单的价格都采用不同的货币。为了正确地将此表标准化为单一货币(如美元),每张订单都需要与下订单时相应的货币兑换率相结合。
sql
1、创建订单表
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING, --币种
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
'topic' = 'orders', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
2、订单表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic orders
o_001,1,EUR,2024-06-06 12:00:00
o_002,100,EUR,2024-06-06 12:00:07
o_003,200,EUR,2024-06-06 12:00:16
o_004,10,EUR,2024-06-06 12:00:21
o_005,20,EUR,2024-06-06 12:00:25
3、创建汇率表
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time,
PRIMARY KEY(currency) NOT ENFORCED -- 主键,区分不同的汇率
) WITH (
'connector' = 'kafka',
'topic' = 'currency_rates1', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'earliest-offset', -- 指定读取数据的位置
'format' = 'canal-json' -- 指定数据的格式
);
4、向汇率表中添加数据
insert into currency_rates
values
('EUR',0.12,TIMESTAMP'2024-06-06 12:00:00'),
('EUR',0.11,TIMESTAMP'2024-06-06 12:00:09'),
('EUR',0.15,TIMESTAMP'2024-06-06 12:00:17'),
('EUR',0.14,TIMESTAMP'2024-06-06 12:00:23');
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic currency_rates
-- 使用常规关联方式关联时态表只能关联到最新的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates as b
on a.currency=b.currency;
-- 时态表join
-- FOR SYSTEM_TIME AS OF a.order_time: 使用a表的时间到b表中查询对应时间段的数据
select
a.price,a.order_time,b.conversion_rate,b.update_time
from
orders as a
join
currency_rates FOR SYSTEM_TIME AS OF a.order_time as b
on a.currency=b.currency;常规join结果:

时态join结果:
4、lookup join(查找连接)
Lookup Join,也称为维表 Join,通常用于从外部系统查询的数据表。连接要求一个表具有处理时间属性,另一个表由查找源连接器支持。
具体来说:
lookup join用于流表(动态表)关联维度表
流表:动态表
维度表:不怎么变化的变,维度表的数据一般可以放在hdfs或者mysql等外部数据源
扩展:流表、事实表、维度表
sql
-- 流表(动态表)
1、流表的数据来源通常是实时数据流,这些数据流可以来自各种数据源,如 Kafka、RabbitMQ、Kinesis 等。Flink可以通过数据源连接器(Source Connectors)将这些实时数据流接入到 Flink 系统中
2、与传统数据库中的表不同,流表的行是动态生成的,随着数据流的持续产生而不断增加
-- 维度表
1、主要提供数据的分析角度,包含了描述业务环境的属性信息,如时间、地理、产品等。
2、维度表:通常比较宽(包含多个属性列),但行数相对较少,因为维度表中的每一行通常代表一个具体的业务实体或类别,如一个商品、一个客户、一个日期等。
3、维度表与事实表之间通过外键相关联,共同构成了星型模型或雪花模型。事实表中的外键用于与维度表中的主键相匹配,从而提供数据的上下文和分类信息。
4、维度表存储的是对数据的描述性信息,这些信息通常不随时间变化,或者变化不频繁。例如,商品的品牌、型号、颜色等属性一旦确定后很少会发生变化。但在某些情况下,如新产品上市或促销活动,可能需要更新维度表以添加新的维度成员。
-- 事实表
1、存储了实际的数据度量值,如销售额、订单数量等。事实表是数据分析的核心,包含了所有用于分析的数据指标。
2、通常比较窄(包含较少的列),但行数非常多,因为事实表中的每一行通常代表一个具体的事件或交易,如一个订单、一次点击等。
3、事实表存储的是度量数据(即指标),这些数据会随时间变化,并且经常需要被汇总和分析。例如,销售额、订单数量、点击量等指标会随着业务活动的进行而不断更新。
4、事实表的数据更新频率通常较高,因为事实数据会随着业务活动的进行而不断产生。例如,每当有新的订单产生时,都需要在事实表中插入一条新的记录。
sql
1、创建分数表
CREATE TABLE scores (
sid INT,
cid STRING,
score INT,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'scores', -- 指定topic
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- 指定kafka集群列表
'properties.group.id' = 'testGroup', -- 指定消费者组
'scan.startup.mode' = 'latest-offset', -- 指定读取数据的位置
'format' = 'csv' -- 指定数据的格式
);
2、生产分数表数据
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000003,137
3、建立学生表,我们将学生表当作维度表放在mysql中
CREATE TABLE students_test (
id INT,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata29',
'table-name' = 'students_test',
'username' ='root',
'password' = '123456',
'lookup.cache.max-rows' = '1000', -- 最大缓存行数
'lookup.cache.ttl' ='10000' -- 缓存过期时间
);
学生表数据
1500100001,施笑槐,22,女,文科六班
-- 使用常规关联方式
-- 维表的数据只在任务启动的时候读取一次,后面不再实时读取,
-- 只能关联到任务启动时读取的数据
-- 一旦mysql中的学生表更新数据,但是关联的学生表数据却是任务启动时从mysql读取的,这就有错误了,lookup join可以解决该问题。
select a.sid,a.score,b.id,b.name from
scores as a
left join
students_test as b
on a.sid=b.id;
-- lookup join
-- 当流表每来一条数据时,使用关联字段到维表的数据源中查询
-- 优点:实时更新数据源,准确性高
-- 缺点:每一次都需要查询数据库,性能会降低
select a.sid,a.score,b.id,b.name from
scores as a
left join
students_test FOR SYSTEM_TIME AS OF a.proctime as b
on a.sid=b.id;此时我们修改更新mysql中的学生表数据
修改之前

修改后:

常规关联结果:

look up关联结果:
