朴素贝叶斯分类器是一种基于概率统计的简单但强大的机器学习算法。它假设特征之间是相互独立的("朴素"),尽管在现实世界中这通常不成立,但在许多情况下这种简化假设仍能提供良好的性能。
- 基本原理:朴素贝叶斯分类器利用贝叶斯定理,计算给定输入特征条件下属于某个类别的概率,并选择具有最高概率的那个类别作为预测结果。
- 计算公式:对于特征向量 ( x ) 和类别 ( C ),朴素贝叶斯估计为 ( P(C|X) = \frac{P(X|C) * P©}{P(X)} ),其中 ( P(X|C) ) 是在类别 ( C ) 下特征出现的概率,( P© ) 是类别出现的概率,而 ( P(X) ) 是特征集的整体概率,通常用先验知识或训练数据估计。
它的优点包括:
- 计算效率高:由于其"朴素"假设(即特征之间相互独立),在训练阶段计算每个类别的条件概率相对容易,这使得在大数据集上处理时速度非常快。
- 鲁棒性:对于缺失数据处理较为友好,只要数据满足一定的独立性,即使有部分特征缺失,也能给出预测。
- 可解释性强:模型基于简单的概率公式,结果易于理解,可以直观地解释某个实例属于哪个类别。
- 并行计算友好:分类过程可以很容易地并行化,适合分布式系统。
- 对新数据适应性强:一旦训练完成,新的观测值可以快速分类,没有存储和计算所有历史数据的限制。
- 对小样本数据有效:即使样本量不大,朴素贝叶斯分类器也能提供不错的结果,特别适用于文本分类和垃圾邮件过滤等任务。
在数据分析中,类别属性(也称为分类变量或名义变量)是表示非数值的数据,如性别、颜色、职业等。对这些类别属性进行编码是为了将它们转换为数值形式,以便计算机能够理解和处理。这种编码过程有以下几个重要作用:
- 数值化处理:许多机器学习和统计分析算法(如线性回归、决策树等)期望输入是数值型的。类别编码使算法可以对不同类别赋予一个连续的数值,便于计算。
- 模型训练:编码后的类别数据可以作为输入特征,让模型学习不同类别之间的关系,有助于提高预测的准确性和模型的解释性。
- 减少偏差:有些编码方法(如独热编码)可以防止模型过度拟合某个特定的类别顺序,确保模型对数据的处理更加公平。
- 可比较性:编码使得不同类别之间的大小或重要性可以被量化,方便进行比较和排序。
常见的类别编码方法包括:
- 标签编码(Label Encoding):为每个类别分配一个唯一的整数。
- 独热编码(One-Hot Encoding):创建一个新的二进制特征列,对每个类别设置一个列,其余为0。
- 有序编码(Ordinal Encoding):当类别有明确的等级关系时,给类别赋值基于其顺序。
- 二进制编码(Binary Encoding):用二进制数字表示类别,但这种方法可能增加模型复杂度。
1、读取数据
python
#导入数据
import pandas as pd
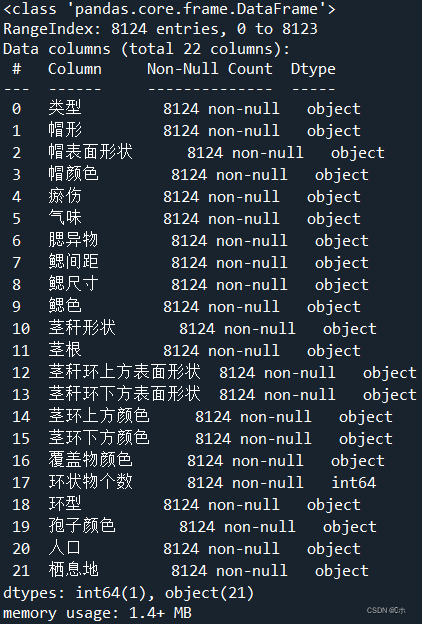
data = pd.read_excel('mushrooms.xls')导入数据概述:
2、将各属性值进行编号
python
#将各属性值进行编号
columns = data.columns[1:]
for i in columns:
data[i] = pd.factorize(data[i])[0]
#将 类型 转化为0,1
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
label = le.fit_transform(data['类型'])
data['类型'] = label对属性编号:(局部数据)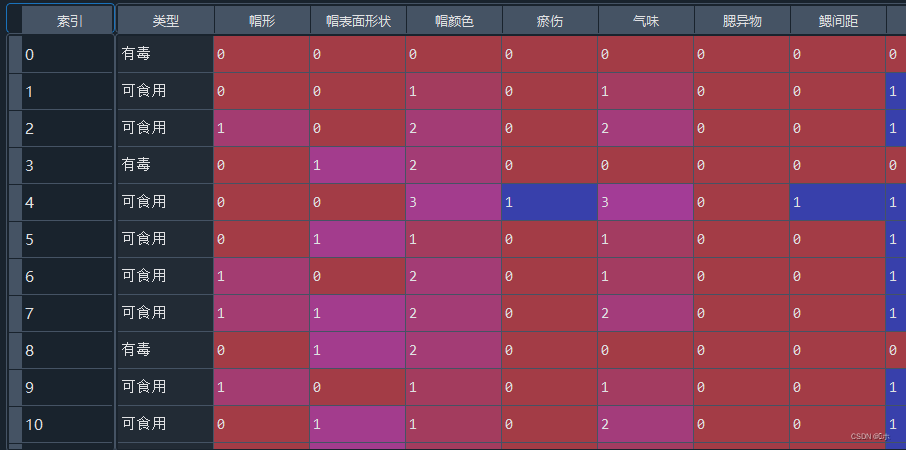
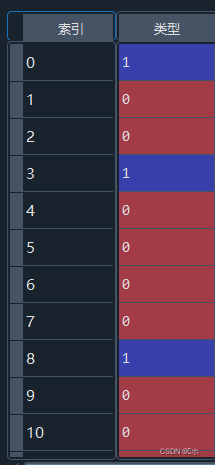
将类型转换为01:(局部数据)
3、划分数据集、训练集
python
#划分数据集、训练集
from sklearn import model_selection
x_train, x_test, y_train, y_test = model_selection.train_test_split(data[columns], data['类型'],test_size=0.3,random_state=1)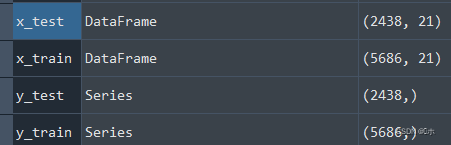
4、训练模型
python
#训练模型
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(x_train,y_train)
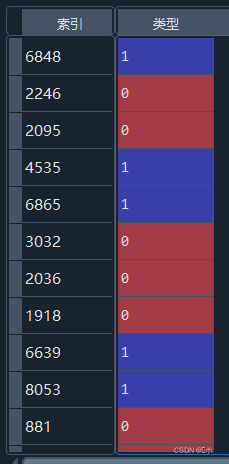
mnb_pred = mnb.predict(x_test)训练的划分结果(部分):
5、输出混淆矩阵
python
#混淆矩阵
cm = pd.crosstab(mnb_pred, y_test)
6、输出模型准确率;精确度、召回率和F1分数等信息
python
#输出模型准确率;精确度、召回率和F1分数等信息
from sklearn import metrics
print('模型的准确率为:',metrics.accuracy_score(y_test, mnb_pred))
print('模型评估报告\n',metrics.classification_report(y_test, mnb_pred))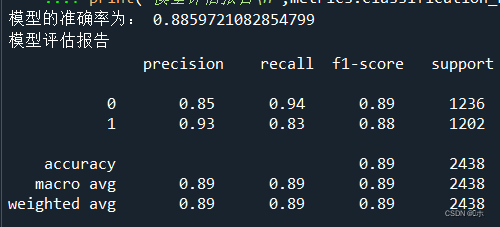
7、计算AUC得分
python
#预测概率
y_predict_proba = mnb.predict_proba(x_test)
#返回值是一个元组,分别是,精准率,召回率,阈值
from sklearn.metrics import roc_curve
fpr, tpr, thretholds = roc_curve(y_test, y_predict_proba[:,1])
#计算AUC得分
from sklearn.metrics import auc
AUC = auc(fpr,tpr)
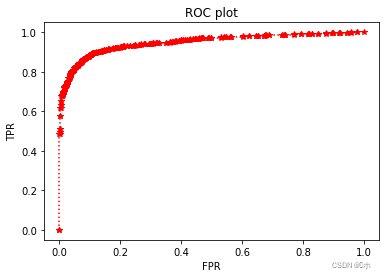
8、绘制ROC图
python
#绘制ROC图
import matplotlib
import matplotlib.pyplot as plt
matplotlib.rc('axes', facecolor = 'white')
matplotlib.rc('figure', figsize = (6, 4))
matplotlib.rc('axes', grid = False)
plt.plot(fpr,tpr,'*:r')
plt.title('ROC plot')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.savefig('ROC plot.png')