目录
[1. 数组名的理解](#1. 数组名的理解)
[2. 使用指针访问数组](#2. 使用指针访问数组)
[3. ⼀维数组传参的本质](#3. ⼀维数组传参的本质)
[4. 冒泡排序](#4. 冒泡排序)
[5. 二级指针](#5. 二级指针)
[6. 指针数组](#6. 指针数组)
[7. 指针数组模拟二维数组](#7. 指针数组模拟二维数组)
1. 数组名的理解
有下面一段代码:
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];//取出第一个元素的地址,放到p里面。
return 0;
}上面代码就是&arr0取出首元素的地址,其实数组名就是首元素的地址,下面做个测试。
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}代码运行结果:

从代码的运行结果可以看出,数组名和数组首元素的地址打印出的结果一摸一样,这样就可以证明数组名就是数组首元素的地址。
既然数组名就是数组首元素的地址,那么下面的代码应该怎么理解?
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}运行代码:
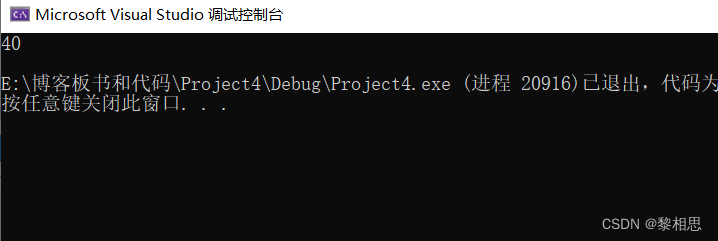
既然arr是数组首元素的地址,是地址的话就应该是4或者8个字节,那么为什么这里会输出40呢?
其实数组名就表示数组首元素的地址,这个说话是正确的,但是有两个例外:
1.**sizeof(数组名),**sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
2.&数组名,这⾥的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的)。
除此之外,所以的数组名都表示数组首元素的地址。
我们知道sizeof(数组名)中的数组名表示整个数组,上面也举了例子,那么&数组名和数组名有啥区别,也就是说整个数组的地址和数组首元素的地址有啥区别。
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);
return 0;
}运行代码:
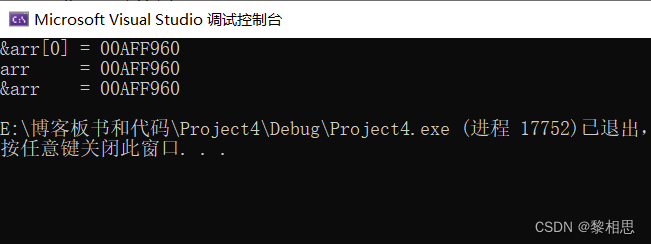
三个地址的结果居然一摸一样。
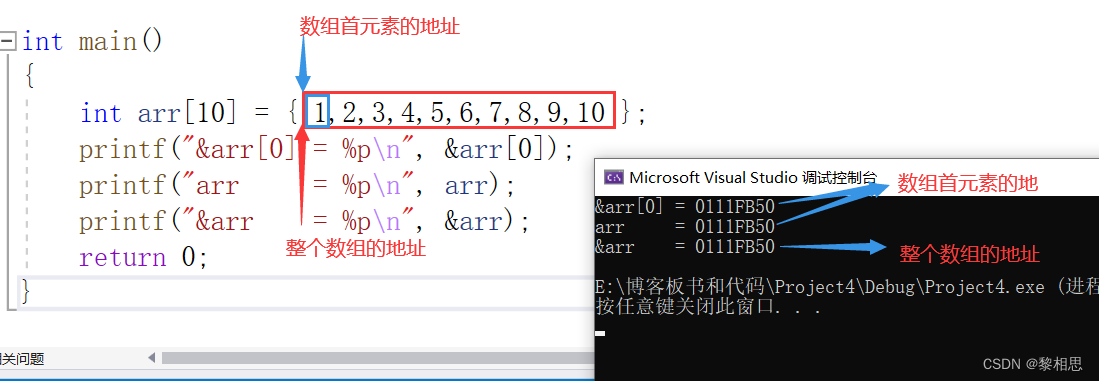
数组首元素的地址和整个数组它们的地址是一样的,就说明它们的起始位置是一样的,那么arr和&arr的地址一样,本质上有啥区别呢?
前面我们说过指针类型决定了指针的差异,整型指针加1跳过4个字节,字符指针加1跳过1个字节。
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}运行代码:
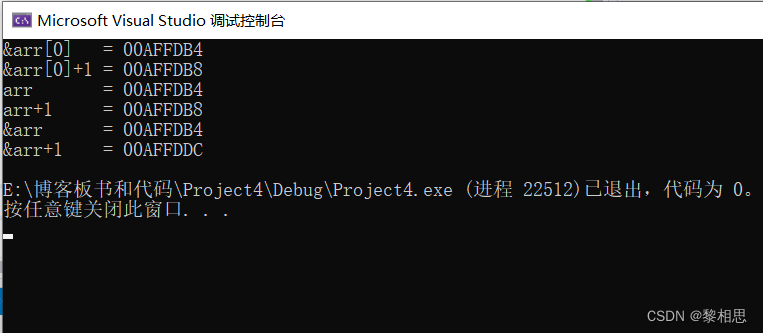

2. 使用指针访问数组
cpp
#include <stdio.h>
int main()
{
int arr[10] = { '\0' };
//输入
for (int i = 0; i < 10; i++)
{
scanf("%d", &arr[i]);
}
//输出
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}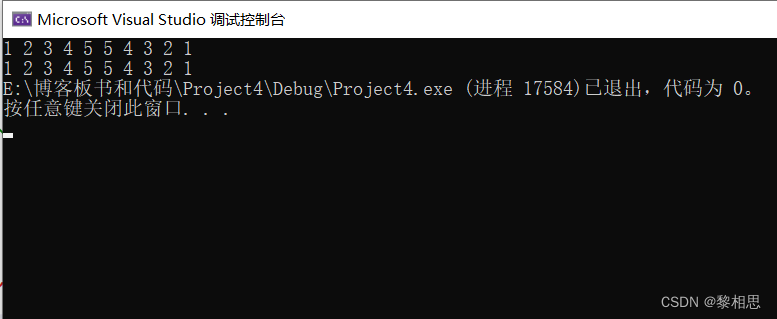 上面这种代码是使用下标的方式来访问数组,那我们也可以使用指针的方式来访问数组。
上面这种代码是使用下标的方式来访问数组,那我们也可以使用指针的方式来访问数组。
cpp
#include <stdio.h>
int main()
{
int arr[10] = { '\0' };
//输入
for (int i = 0; i < 10; i++)
{
scanf("%d", arr+i);
//scanf函数需要的是地址,arr表示首元素的地址,加i来遍历我的数组
}
//输出
for (int i = 0; i < 10; i++)
{
printf("%d ", *(arr + i));
//arr表示首元素的地址,arr+i来遍历数组,*解引用就拿到地址中的值
}
return 0;
}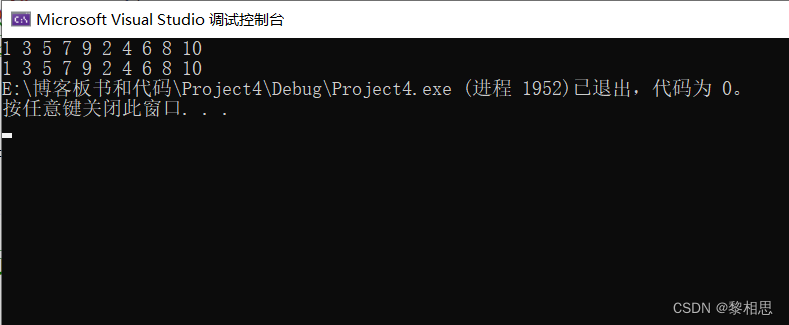
由此可以看出,使用指针也是可以的。

将*(arr+i)换成arri也是能够正常打印的,所以本质上pi 是等价于 *(p+i)。
同理arri应该等价于*(arr+i),数组元素的访问在编译器处理的时候,也是转换成首元素的地址+偏移 量求出元素的地址,然后解引用来访问的。
我们知道加法是支持交换的,a+b就等价于b+a,那么*(arr+i)也可以写成*(i+arr)。
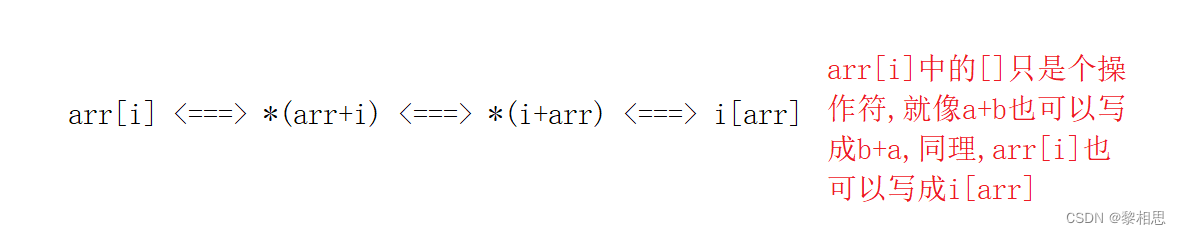
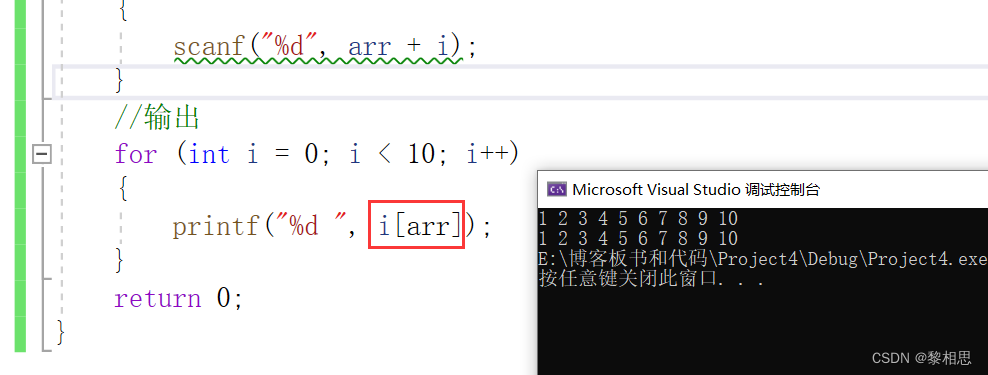 iarr和arri等价,本质上没什么区别,在编译器底层也是转换成指针,但是可读性不高。
iarr和arri等价,本质上没什么区别,在编译器底层也是转换成指针,但是可读性不高。
总结:
1.数组就是数组,是一块连续的空间,是可以存放一个或者多个数据的。
2.指针变量是一个变量,是可以存放地址的变量。
3.数组和指针不是一回事,但是可以使用指针来访问数组。
为什么可以使用指针来访问数组呢?
1.数组在内存中是连续存放的。
2.指针的加减可以很方便的遍历数组,取出数组的内容(指针的运算)。
3. ⼀维数组传参的本质
求数组的元素个数。
cpp
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("%d\n", sz);
return 0;
}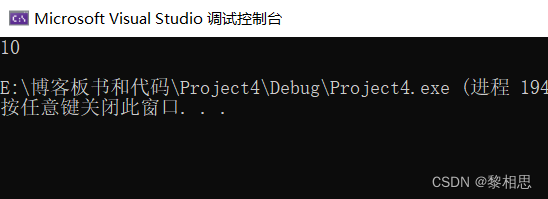
那如果我想写一个函数来计算数组元素个数呢?

这样写就是在函数内部求数组元素个数啊,可为什么是1呢?
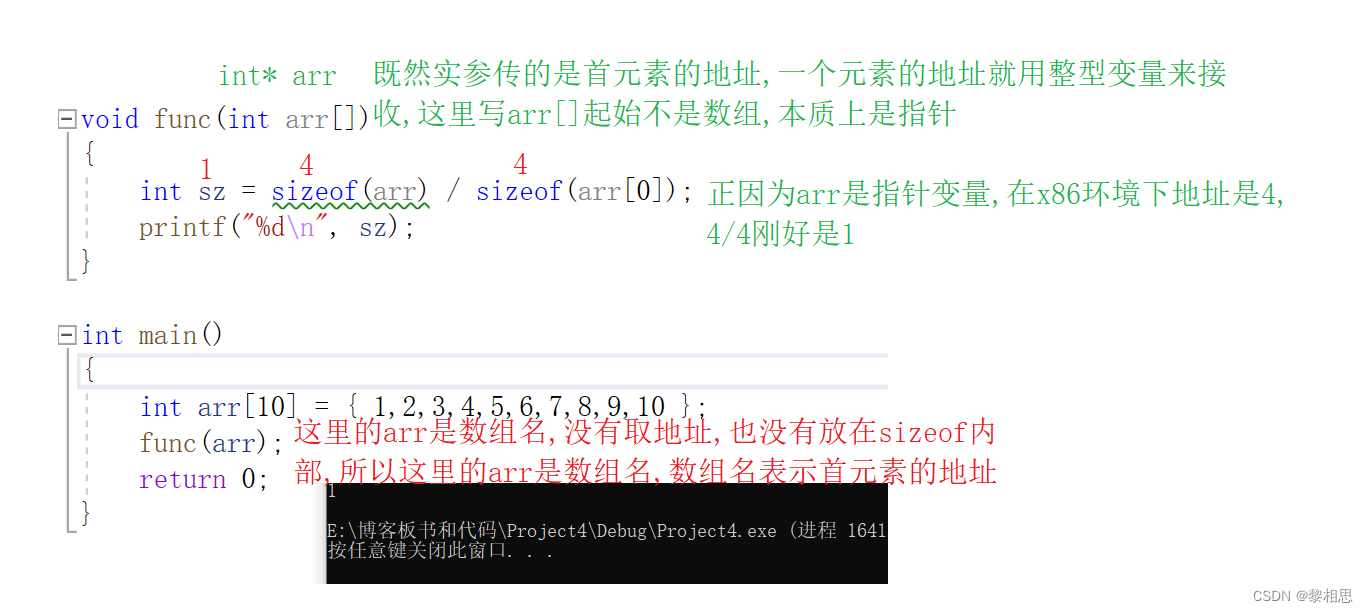 数组传参的时候,形参可以写成数组,也可以写成指针,数组传参的本质是传递的首元素的地址,所以形参即使写成数组的形式,本质上也是一个指针变量。
数组传参的时候,形参可以写成数组,也可以写成指针,数组传参的本质是传递的首元素的地址,所以形参即使写成数组的形式,本质上也是一个指针变量。
显然,在函数内部求数组元素的格式是不行的,那么函数参数就需要多加一个参数。
cpp
#include <stdio.h>
void func(int* arr,int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", *(arr + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
func(arr,sz);
return 0;
}我们需要将数组元素个数计算出来然后传给函数形参。
4. 冒泡排序
冒泡排序的核心思想就是:两两相邻的元素进行比较。
cpp
#include <stdio.h>
void BubbleSorting(int* arr, int sz)
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - i - 1; j++)
{
if ((*(arr + j) > *(arr + j+1)))
{
int tem = *(arr + j);
*(arr + j) = *(arr + j + 1);
*(arr + j + 1) = tem;
}
}
}
}
int main()
{
int arr[10] = { '\0' };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
scanf("%d", arr + i);
BubbleSorting(arr, sz);
for (int i = 0; i < sz; i++)
printf("%d ", *(arr + i));
return 0;
}
上面的代码虽然可以完成我们的需求,但是还是不够好,加入是1,2,3,4,5,6,7,8,9,10这样的数字呢?明显就是升序啊,而上面的代码还会一一去比较大小,这样就是在浪费时间,当我内置的循环第一次结束的时候而一对数字都没有交换的话就说明数组本来就是升序,这个时候就不需要进行第二轮的比较了。
优化后:
cpp
#include <stdio.h>
void BubbleSorting(int* arr, int sz)
{
for (int i = 0; i < sz - 1; i++)
{
int flag = 0;//假设是有序的
for (int j = 0; j < sz - i - 1; j++)
{
if ((*(arr + j) > *(arr + j + 1)))
{
flag = 1;//不是有序的
int tem = *(arr + j);
*(arr + j) = *(arr + j + 1);
*(arr + j + 1) = tem;
}
}
if (!flag)
break;
}
}
int main()
{
int arr[10] = { '\0' };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
scanf("%d", arr + i);
BubbleSorting(arr, sz);
for (int i = 0; i < sz; i++)
printf("%d ", *(arr + i));
return 0;
}为了看出效果,我们可以拿优化前和优化后的代码做个对比。
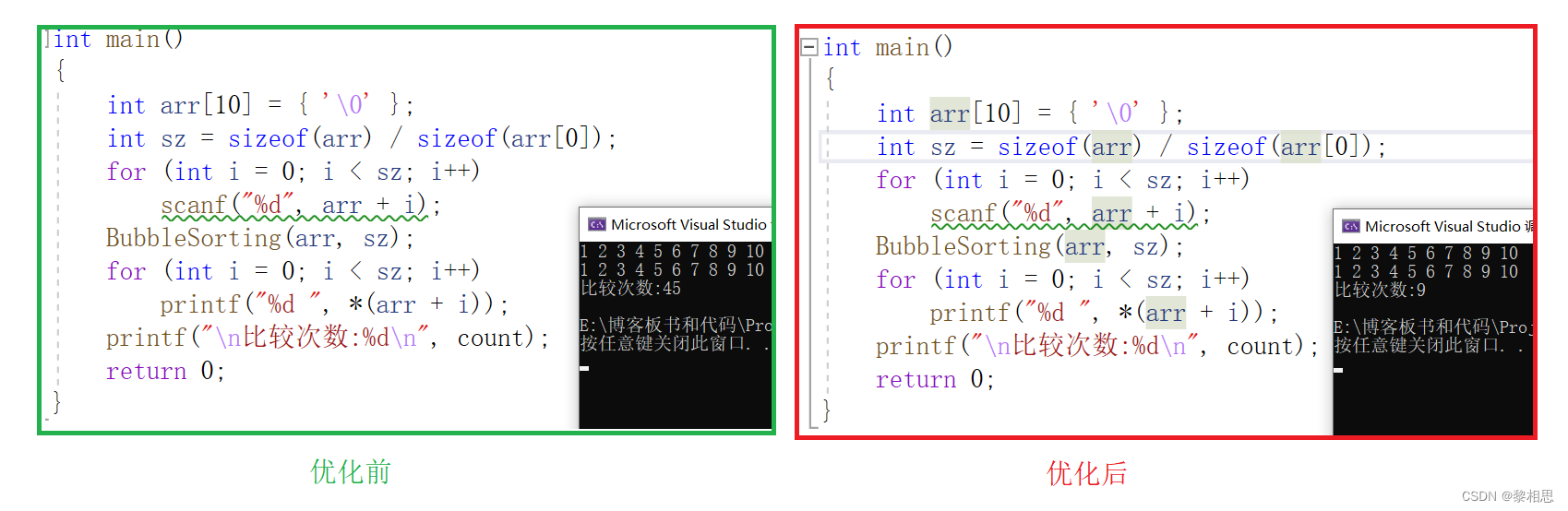 对于这种以及是升序的代码,优化前需要比较45次,而优化后只需要比较9次。
对于这种以及是升序的代码,优化前需要比较45次,而优化后只需要比较9次。
5. 二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址就存放在⼆级指针 。
cpp
int main()
{
int a = 10;
int* p = &a;//p是一级指针
int** pa = &p;//pa是二级指针
return 0;
}
那么二级指针该怎么用呢?
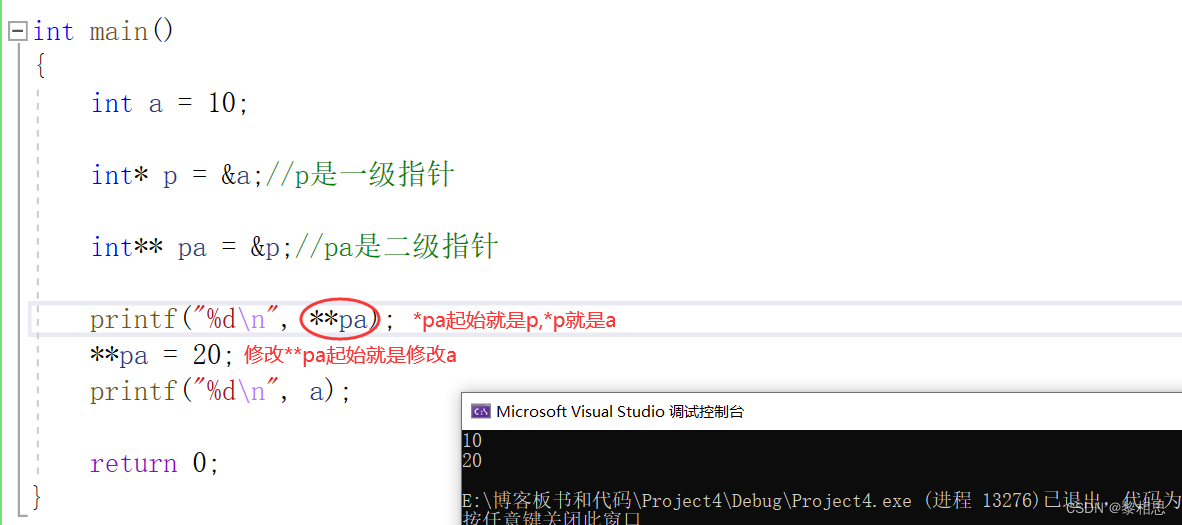
当有一天我需要将指针变量的地址存起来的时候就可以使用二级指针,二级指针和二维数组没有对应的关系。
6. 指针数组
指针数组是指针还是数组呢?
如果实在不理解,我们可以换个方式。
cpp
char ch[10];//字符数组 -- 存放字符的数组
int arr[10];//整型数组 -- 存放整型的数组那么指针数组就是存放指针的数组,数组的每个元素其实都是指针类型。
那么我们可以来写一下指针数组。
cpp
char* ch[5];//存放字符指针的数组,每个元素是char*类型,一个5个元素
int* arr[5];//存放整型指针的数组,每个元素是int*类型,一个5个元素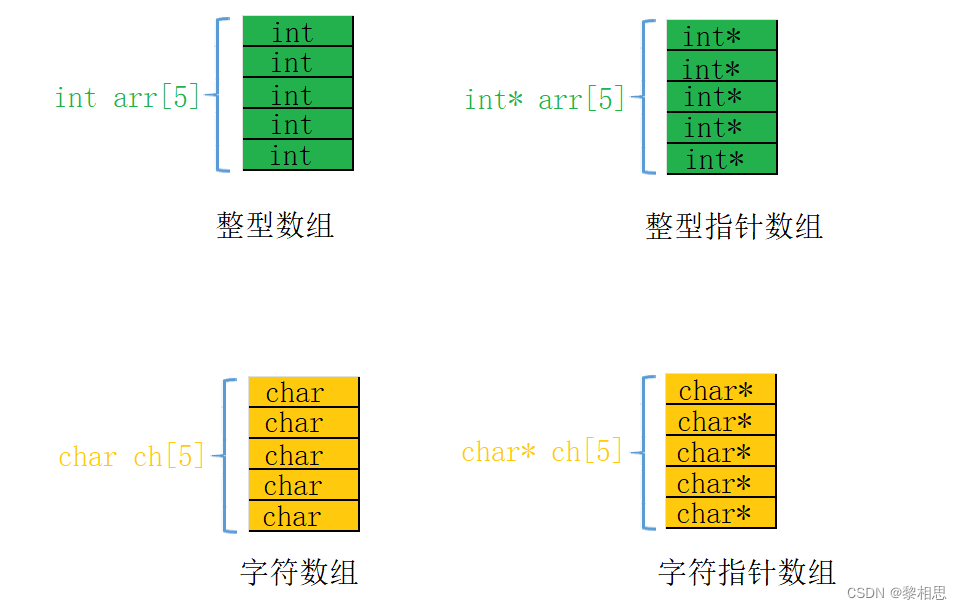
写个代码来理解一下吧。
cpp
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
int c = 30;
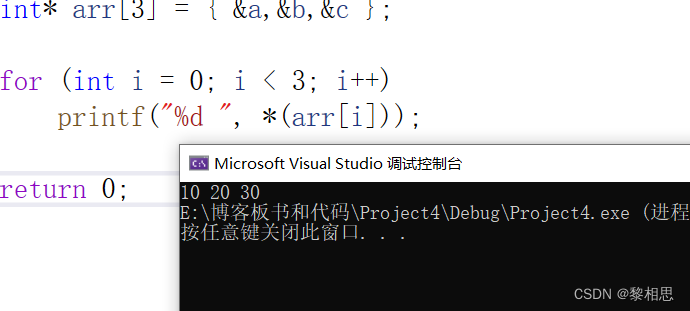
int* arr[3] = { &a,&b,&c };
for (int i = 0; i < 3; i++)
printf("%d ", *(arr[i]));
return 0;
}
我们怎么放进去的就怎么拿出来,但是这种写法比较死板。
7. 指针数组模拟二维数组
cpp
#include <stdio.h>
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
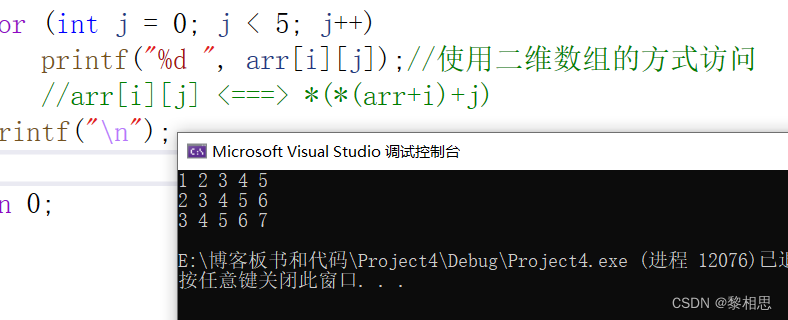
int* arr[] = { arr1,arr2,arr3 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 5; j++)
printf("%d ", arr[i][j]);//使用二维数组的方式访问
//arr[i][j] <===> *(*(arr+i)+j)
printf("\n");
}
return 0;
}
用指针数组也可以模拟实现二维数组。
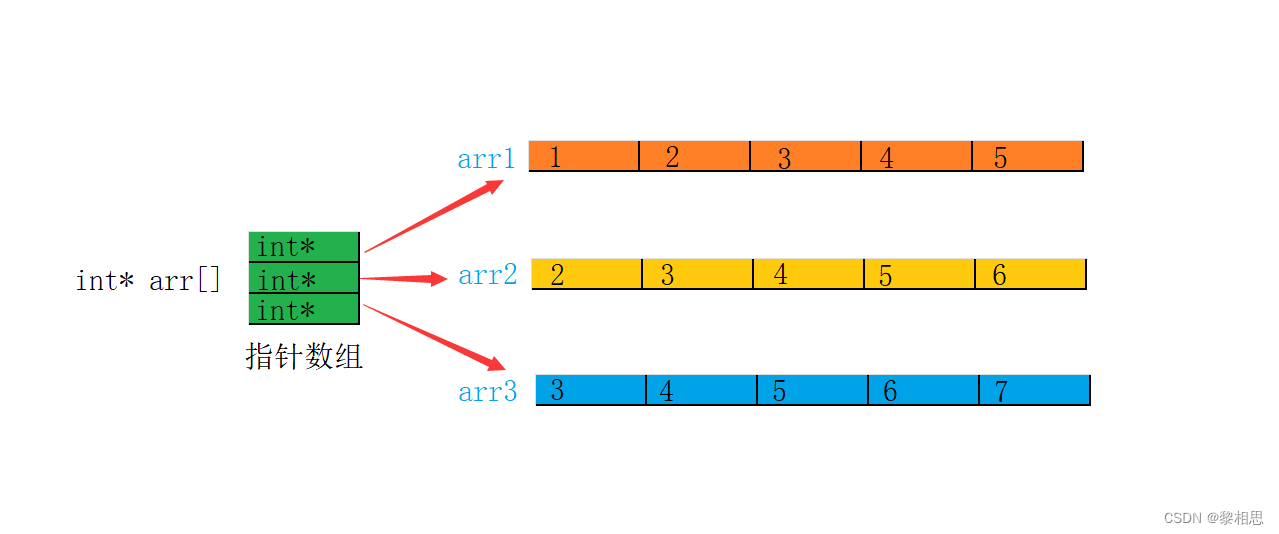 arri是访问arr数组的元素,arri找到的数组元素指向了整型⼀维数组,arrij就是整型⼀维数组中的元素。
arri是访问arr数组的元素,arri找到的数组元素指向了整型⼀维数组,arrij就是整型⼀维数组中的元素。
上述的代码模拟出⼆维数组的效果,实际上并非完全是⼆维数组,因为每一行并非是连续的。