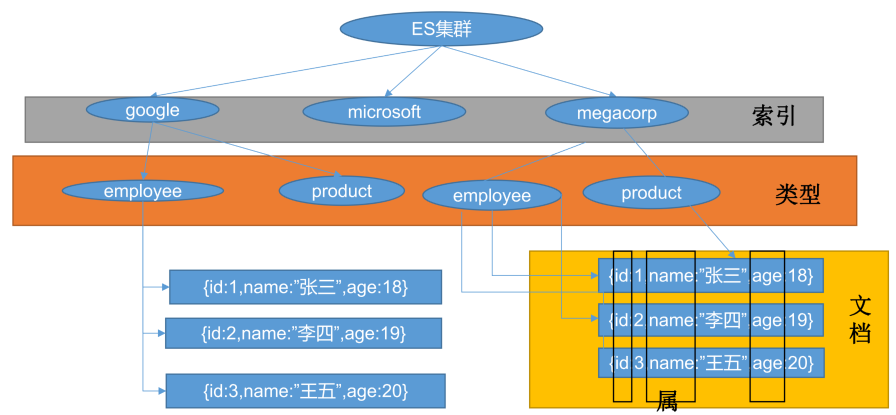
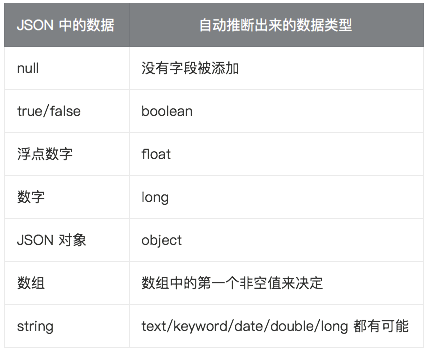
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而 ES 中不需要定义 Mapping 映射〈即关系型数据库的表、字段等),在文档写入 ES 时,会根据文档字段自动识别类型,这种机制称之为动态映射
动态映射规则如下:
type概念移除
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但 ES 中不是这样的,在 ES 中不同 type 下名称相同的 filed 最终在 Lucene 中的处理方式是一样的
两个不同 type 下的两个 user_name,在 ES 同一个索引下其实被认为是同一个 filed,你必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段名称就会在处理中出现冲突的情况,导致Lucene 处理效率下降。去掉 type 就是为了提高 ES 处理数据的效率
Elasticsearch 7.x URL中的 type 参数为可选。比如,索引一个文档不再要求提供文档类型