目录
[第一章 DSL查询](#第一章 DSL查询)
[1.1 基本语法](#1.1 基本语法)
[1.2 叶子查询](#1.2 叶子查询)
[1.3 复合查询](#1.3 复合查询)
[1.4 排序](#1.4 排序)
[1.5 分页](#1.5 分页)
[1.6 高亮](#1.6 高亮)
[1.7 总结](#1.7 总结)
[第二章 RestClient查询](#第二章 RestClient查询)
[2.1 快速入门](#2.1 快速入门)
[2.2 叶子查询](#2.2 叶子查询)
[2.3 复合查询](#2.3 复合查询)
[2.4 排序和分页](#2.4 排序和分页)
[2.5 高亮](#2.5 高亮)
[第三章 数据聚合](#第三章 数据聚合)
[3.1 DSL实现聚合](#3.1 DSL实现聚合)
[3.2 RestClient实现聚合](#3.2 RestClient实现聚合)
第一章 DSL查询
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句来定义查询条件,其JavaAPI就是在组织DSL条件。
1.1 基本语法
GET /{索引库名}/_search
{
"query": {
"查询类型": {
// .. 查询条件
}
}
}说明:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改
例如,我们以最简单的无条件查询为例,无条件查询的类型是:match_all,因此其查询语句如下:
GET /items/_search
{
"query": {
"match_all": {
}
}
}由于match_all无条件,所以条件位置不写即可。
执行结果如下:
 你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
你会发现虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
1.2 叶子查询
-
叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
叶子查询的类型也可以做进一步细分,详情大家可以查看官方文档:
如图:

全文检索查询
全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。
全文检索的种类也很多,详情可以参考官方文档:
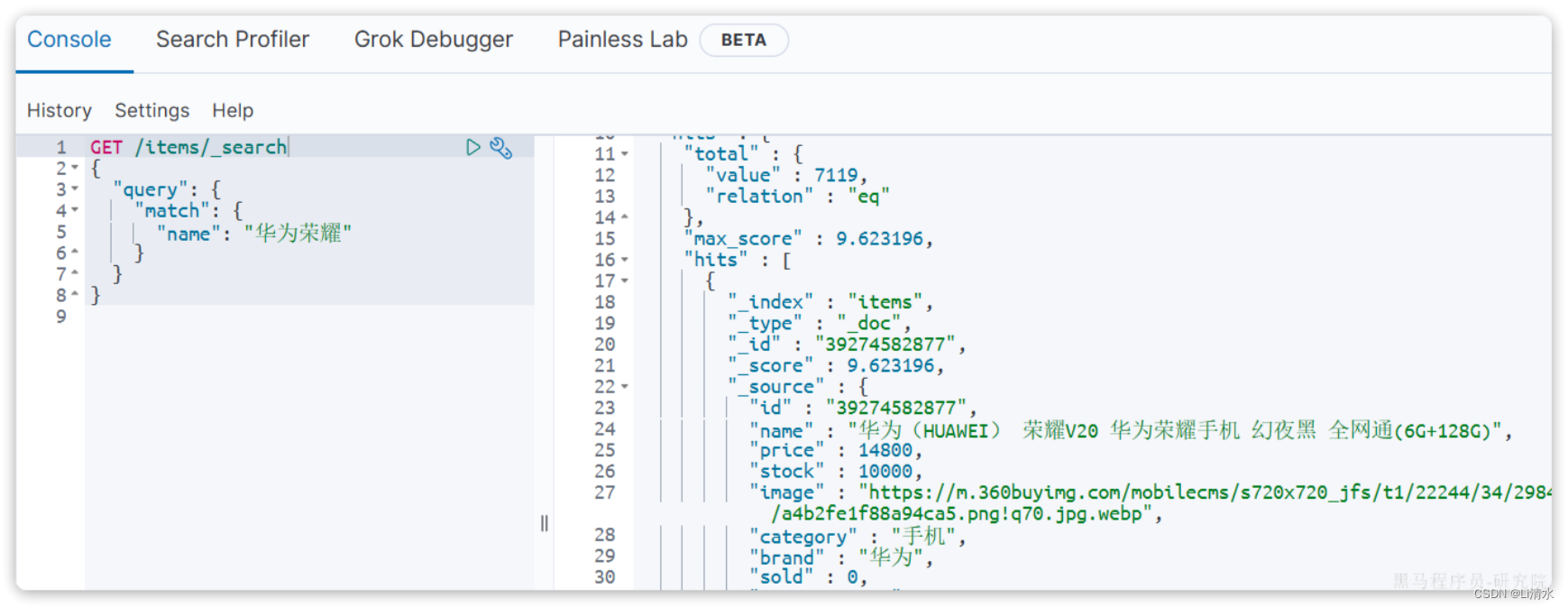
以全文检索中的match为例,语法如下:
GET /{索引库名}/_search
{
"query": {
"match": {
"字段名": "搜索条件"
}
}
}示例:
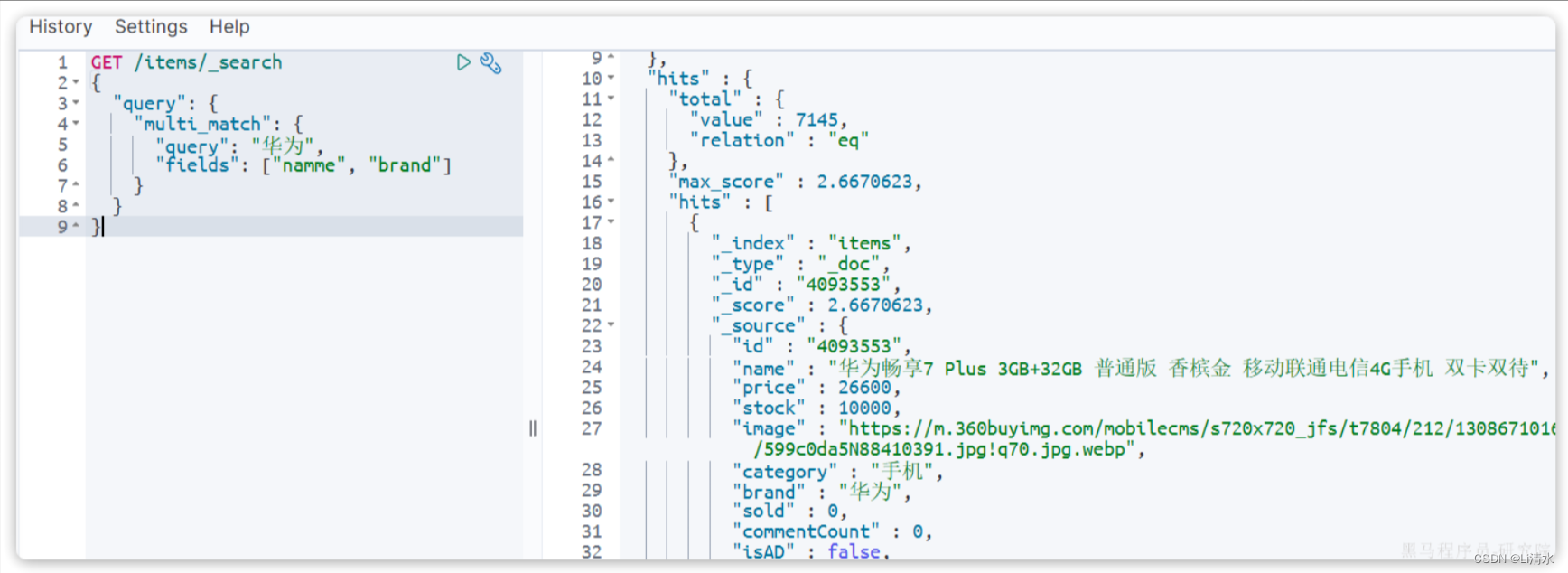
与match类似的还有multi_match,区别在于可以同时对多个字段搜索,而且多个字段都要满足,语法示例:
GET /{索引库名}/_search
{
"query": {
"multi_match": {
"query": "搜索条件",
"fields": ["字段1", "字段2"]
}
}
}示例:
精确查询
-
精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
-
ids -
term -
range
-
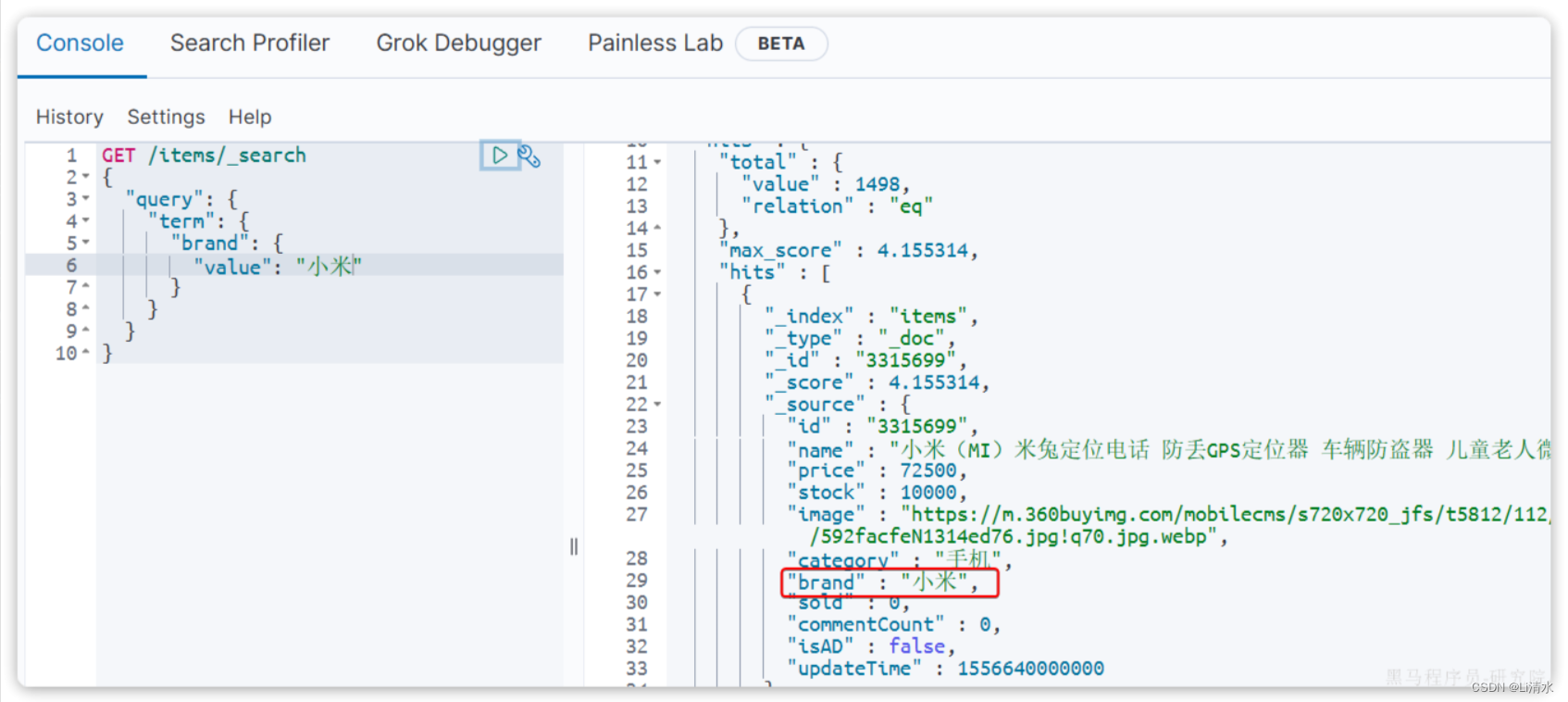
以term查询为例,其语法如下:
GET /{索引库名}/_search
{
"query": {
"term": {
"字段名": {
"value": "搜索条件"
}
}
}
}示例:
 当你输入的搜索条件不是词条,而是短语时,由于不做分词,你反而搜索不到:
当你输入的搜索条件不是词条,而是短语时,由于不做分词,你反而搜索不到:

1.3 复合查询
-
复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
复合查询大致可以分为两类:
-
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
-
第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
-
function_score
-
dis_max
-
算分函数查询
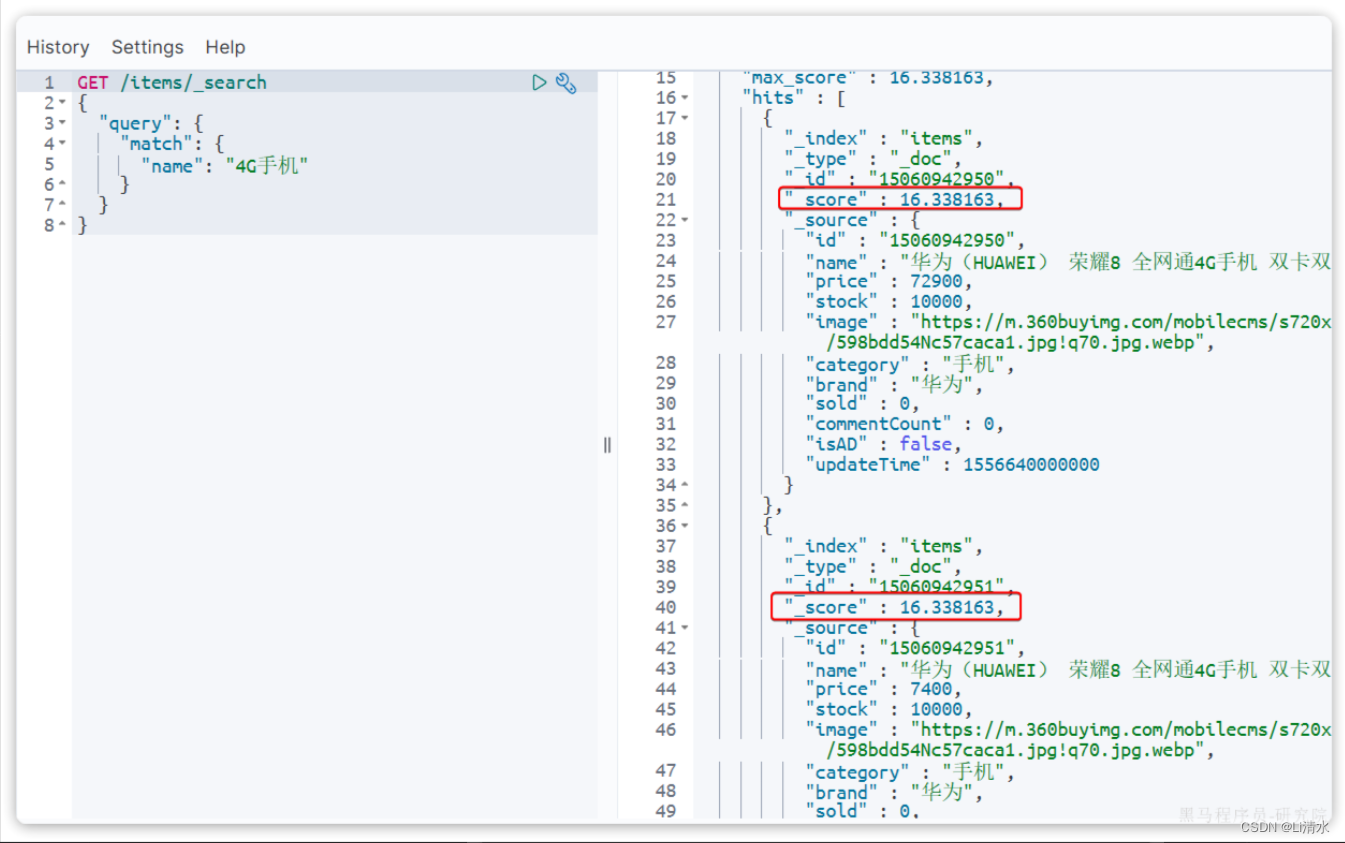
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分 (_score),返回结果时按照分值降序排列。
例如,我们搜索 "手机",结果如下:
 从elasticsearch5.1开始,采用的相关性打分算法是BM25算法,公式如下:
从elasticsearch5.1开始,采用的相关性打分算法是BM25算法,公式如下:

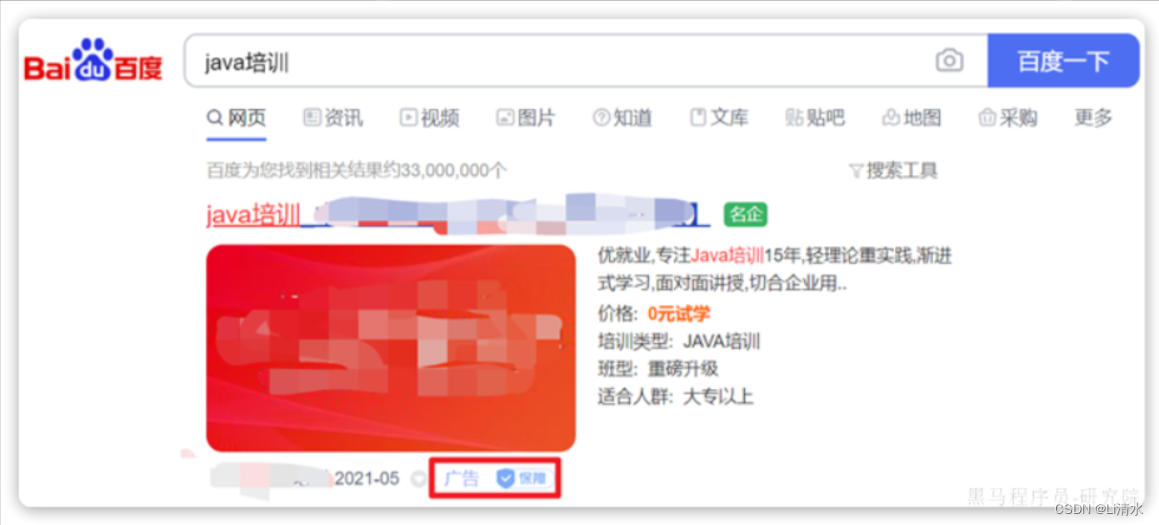
基于这套公式,就可以判断出某个文档与用户搜索的关键字之间的关联度,还是比较准确的。但是,在实际业务需求中,常常会有竞价排名的功能。不是相关度越高排名越靠前,而是掏的钱多的排名靠前。
例如在百度中搜索Java培训,排名靠前的就是广告推广:
 要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
基本语法:
示例:给IPhone这个品牌的手机算分提高十倍,分析如下:
-
过滤条件:品牌必须为IPhone
-
算分函数:常量weight,值为10
-
算分模式:相乘multiply
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是Iphone
"term": {
"brand": "Iphone"
}
},
"weight": 10 // 算分权重为2
}
],
"boost_mode": "multipy" // 加权模式,求乘积
}
}
}
function score 查询中包含四部分内容:
-
原始查询 条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数 :符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
weight:函数结果是常量
-
field_value_factor:以文档中的某个字段值作为函数结果
-
random_score:以随机数作为函数结果
-
script_score:自定义算分函数算法
-
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
-
multiply:相乘
-
replace:用function score替换query score
-
其它,例如:sum、avg、max、min
-
function score的运行流程如下:
-
1)根据原始条件 查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件 的文档,基于算分函数 运算,得到函数算分(function score)
-
4)将原始算分 (query score)和函数算分 (function score)基于运算模式做运算,得到最终结果,作为相关性算分。
bool查询
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。
bool查询支持的逻辑运算有:
-
must:必须匹配每个子查询,类似"与"
-
should:选择性匹配子查询,类似"或"
-
must_not:必须不匹配,不参与算分,类似"非"
-
filter:必须匹配,不参与算分
bool查询的语法如下:
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"should": [
{"term": {"brand": { "value": "vivo" }}},
{"term": {"brand": { "value": "小米" }}}
],
"must_not": [
{"range": {"price": {"gte": 2500}}}
],
"filter": [
{"range": {"price": {"lte": 1000}}}
]
}
}
}出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
例如黑马商城的搜索页面:
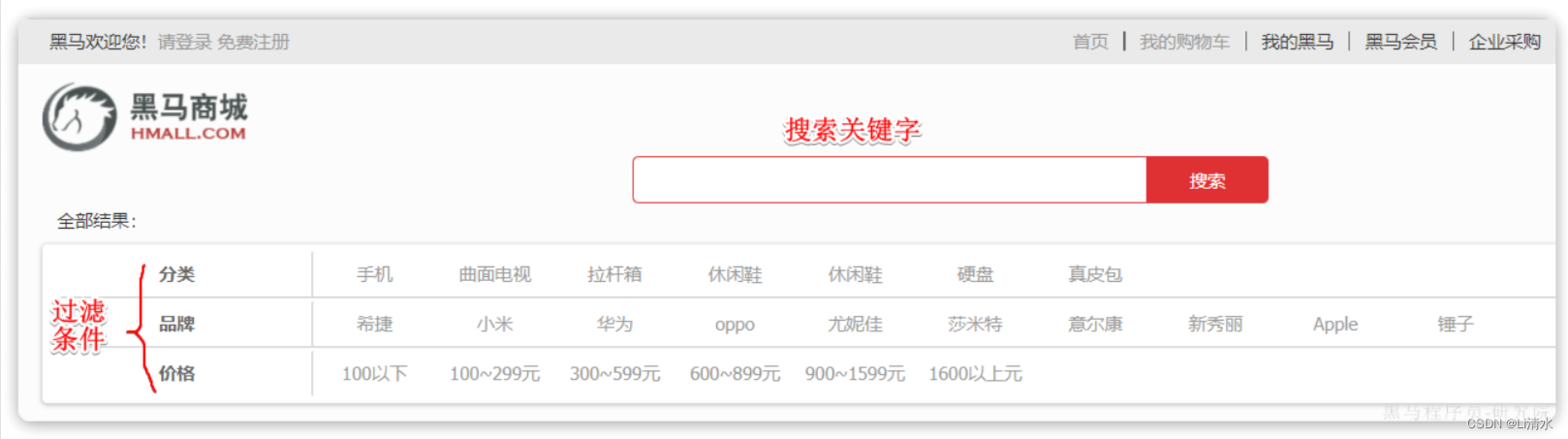
其中输入框的搜索条件肯定要参与相关性算分,可以采用match。但是价格范围过滤、品牌过滤、分类过滤等尽量采用filter,不要参与相关性算分。
比如,我们要搜索手机,但品牌必须是华为,价格必须是900~1599,那么可以这样写:
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"filter": [
{"term": {"brand": { "value": "华为" }}},
{"range": {"price": {"gte": 90000, "lt": 159900}}}
]
}
}
}1.4 排序
elasticsearch默认是根据相关度算分(
_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
语法说明:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"排序字段": {
"order": "排序方式asc和desc"
}
}
]
}示例,我们按照商品价格排序:
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}1.5 分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
基础分页
elasticsearch中通过修改
from、size参数来控制要返回的分页结果:
from:从第几个文档开始
size:总共查询几个文档类似于mysql中的
limit ?, ?
语法如下:
GET /items/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 每页文档数量,默认10
"sort": [
{
"price": {
"order": "desc"
}
}
]
}深度分页
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第99页。那么分页查询的条件如下:
GET /items/_search
{
"from": 990, // 从第990条开始查询
"size": 10, // 每页查询10条
"sort": [
{
"price": "asc"
}
]
}从语句来分析,要查询第990~1000名的数据。
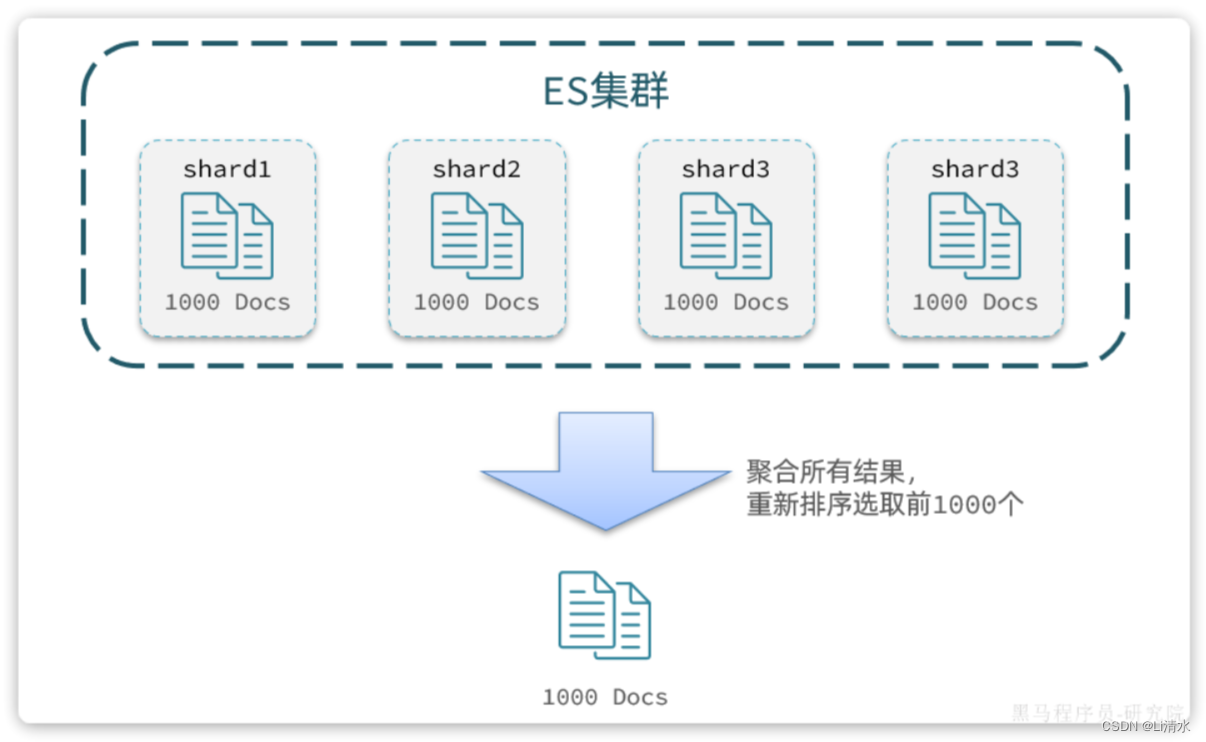
从实现思路来分析,肯定是将所有数据排序,找出前1000名,截取其中的990~1000的部分。但问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第1片上的第900~1000,在另1个节点上并不一定依然是900~1000名。所以我们只能在每一个分片上都找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取990~1000的数据即可。
如图:
试想一下,假如我们现在要查询的是第999页数据呢,是不是要找第9990~10000的数据,那岂不是需要把每个分片中的前10000名数据都查询出来,汇总在一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力。
因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,elasticsearch提供了两种解决方案:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。 -
scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
总结:
大多数情况下,我们采用普通分页就可以了。查看百度、京东等网站,会发现其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条。
因此,一般我们采用限制分页深度的方式即可,无需实现深度分页。
1.6 高亮
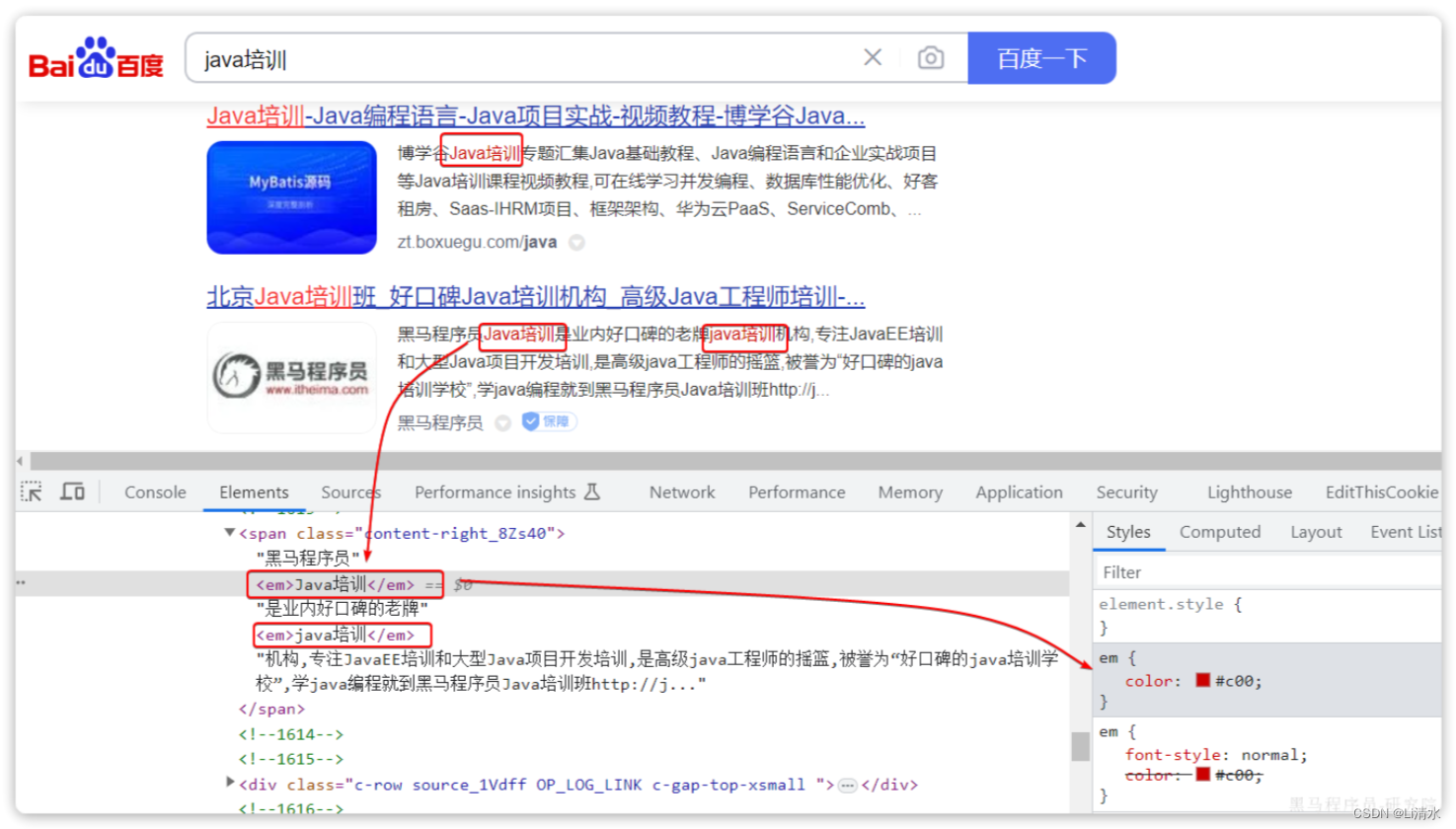
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
观察页面源码,你会发现两件事情:
高亮词条都被加了
<em>标签
<em>标签都添加了红色样式
事实上elasticsearch已经提供了给搜索关键字加标签的语法,无需我们自己编码。
基本语法如下:
GET /{索引库名}/_search
{
"query": {
"match": {
"搜索字段": "搜索关键字"
}
},
"highlight": {
"fields": {
"高亮字段名称": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}注意:
搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match参与高亮的字段必须是
text类型的字段默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
示例:

1.7 总结
查询搜索的完整语法:

第二章 RestClient查询
2.1 快速入门
利用RestHighLevelClient对象,实现查询的基本步骤如下:
1)创建
request对象,这次是搜索,所以是SearchRequest2)准备请求参数,也就是查询DSL对应的JSON参数
3)发起请求
4)解析响应,响应结果相对复杂,需要逐层解析
发送请求
1.准备Request(准备搜索的"表")
2.组织DSL参数(准备查询方式)
3.发送请求,得到的响应结果放在SearchResponse类型的对象中。
首先以match_all查询为例,其DSL和JavaAPI的对比如图:

代码解读:
-
第一步,创建
SearchRequest对象,指定索引库名 -
第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
-
第三步,利用
client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能:
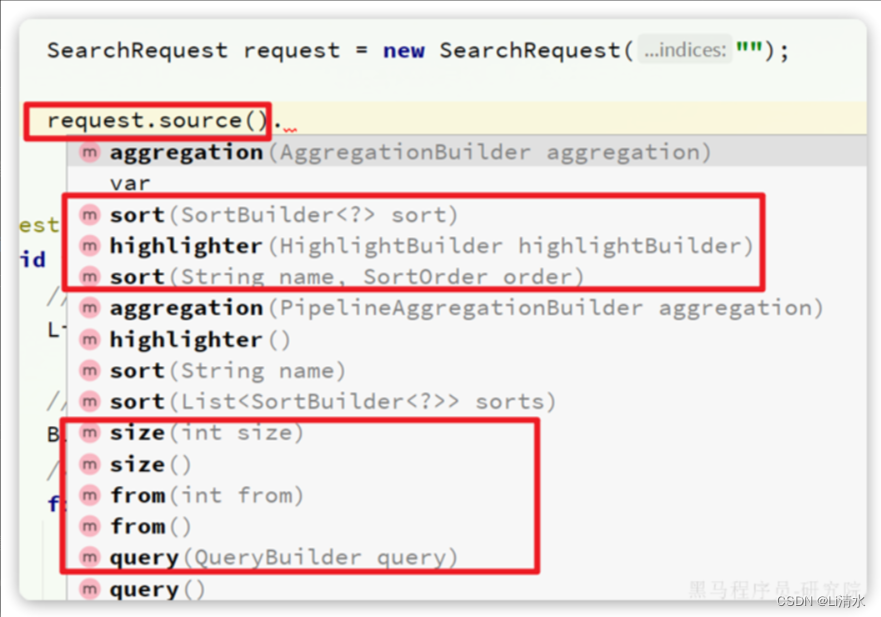 另一个是
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询 、复合查询等:

解析响应结果
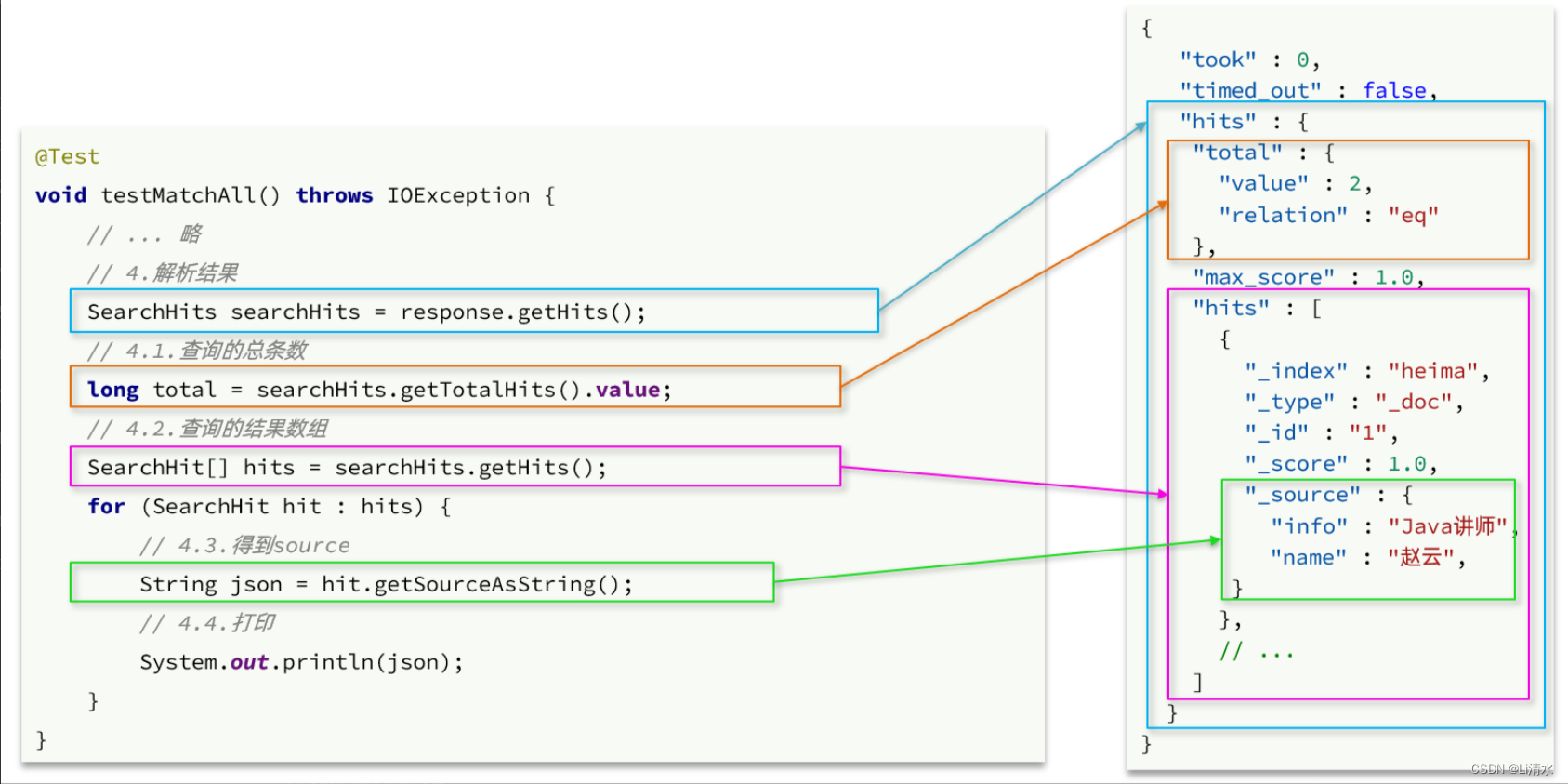
在发送请求以后,得到了响应结果
SearchResponse,这个类的结构与我们在kibana中看到的响应结果JSON结构完全一致:
{
"took" : 0,
"timed_out" : false,
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "heima",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Java讲师",
"name" : "赵云"
}
}
]
}
}elasticsearch返回的结果是一个JSON字符串,结构包含:
-
hits:命中的结果-
total:总条数,其中的value是具体的总条数值 -
max_score:所有结果中得分最高的文档的相关性算分 -
hits:搜索结果的文档数组,其中的每个文档都是一个json对象_source:文档中的原始数据,也是json对象
-
因此,我们解析SearchResponse的代码就是在解析这个JSON结果,对比如下:
总结
完整代码如下:
java
@Test
void testMatchAll() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
request.source().query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
// 1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 2.遍历结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 3.得到_source,也就是原始json文档
String source = hit.getSourceAsString();
// 4.反序列化并打印
ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);
System.out.println(item);
}
}2.2 叶子查询
所有的查询条件都是由QueryBuilders来构建的,叶子查询也不例外。因此整套代码中变化的部分仅仅是query条件构造的方式,其它不动。所有的查询条件都是由QueryBuilders来构建的,叶子查询也不例外。因此整套代码中变化的部分仅仅是query条件构造的方式,其它不动。
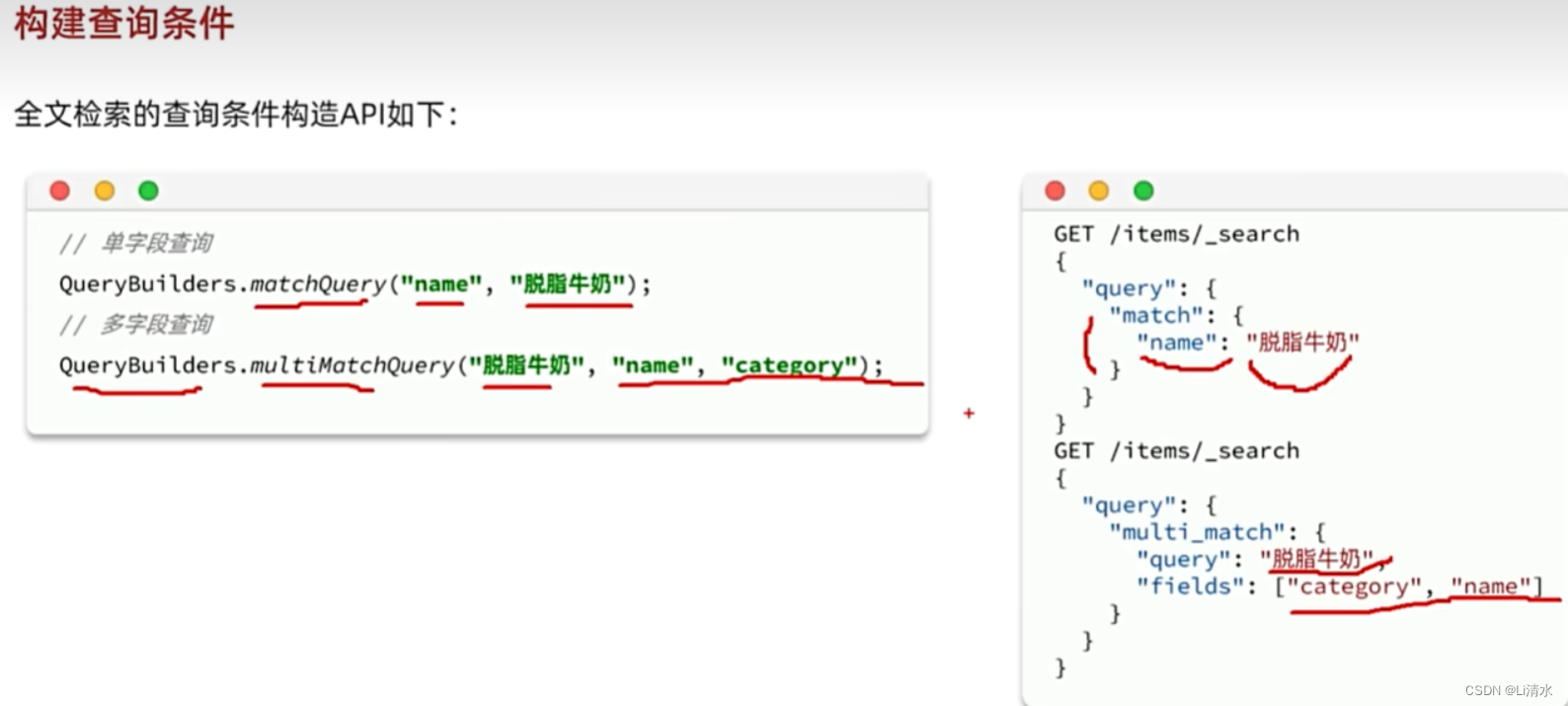 例如
例如match查询:
java
@Test
void testMatch() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}再比如multi_match查询:
java
@Test
void testMultiMatch() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
request.source().query(QueryBuilders.multiMatchQuery("脱脂牛奶", "name", "category"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}2.3 复合查询
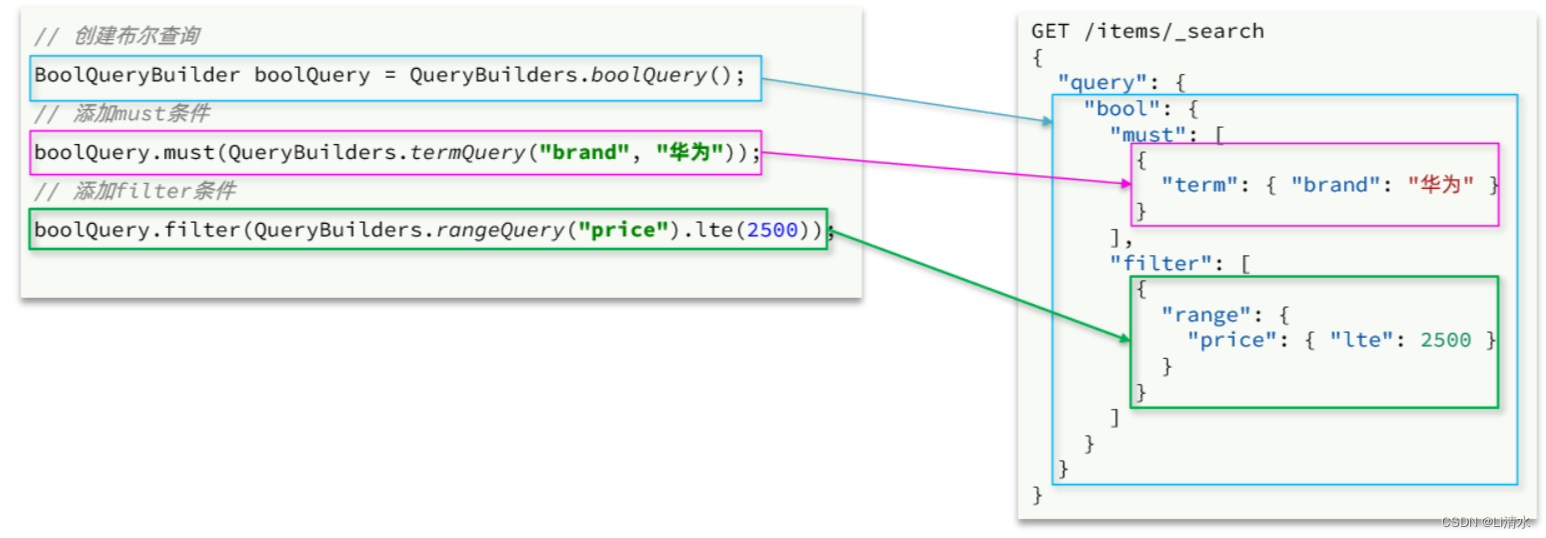
复合查询也是由
QueryBuilders来构建,我们以bool查询为例,DSL和JavaAPI的对比如图:
 完整代码如下:
完整代码如下:
java
@Test
void testBool() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
// 2.1.准备bool查询
BoolQueryBuilder bool = QueryBuilders.boolQuery();
// 2.2.关键字搜索
bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));
// 2.3.品牌过滤
bool.filter(QueryBuilders.termQuery("brand", "德亚"));
// 2.4.价格过滤
bool.filter(QueryBuilders.rangeQuery("price").lte(30000));
request.source().query(bool);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}2.4 排序和分页
requeset.source()就是整个请求JSON参数,所以排序、分页都是基于这个来设置,其DSL和JavaAPI的对比如下:
 完整示例代码:
完整示例代码:
java
@Test
void testPageAndSort() throws IOException {
int pageNo = 1, pageSize = 5;
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
// 2.1.搜索条件参数
request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));
// 2.2.排序参数
request.source().sort("price", SortOrder.ASC);
// 2.3.分页参数
request.source().from((pageNo - 1) * pageSize).size(pageSize);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}2.5 高亮
高亮查询与前面的查询有两点不同:
条件同样是在
request.source()中指定,只不过高亮条件要基于HighlightBuilder来构造高亮响应结果与搜索的文档结果不在一起,需要单独解析
首先来看高亮条件构造,其DSL和JavaAPI的对比如图:
 示例代码如下:
示例代码如下:
java
@Test
void testHighlight() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.组织请求参数
// 2.1.query条件
request.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));
// 2.2.高亮条件
request.source().highlighter(
SearchSourceBuilder.highlight()
.field("name")
.preTags("<em>")
.postTags("</em>")
);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}再来看结果解析,文档解析的部分不变,主要是高亮内容需要单独解析出来,其DSL和JavaAPI的对比如图:
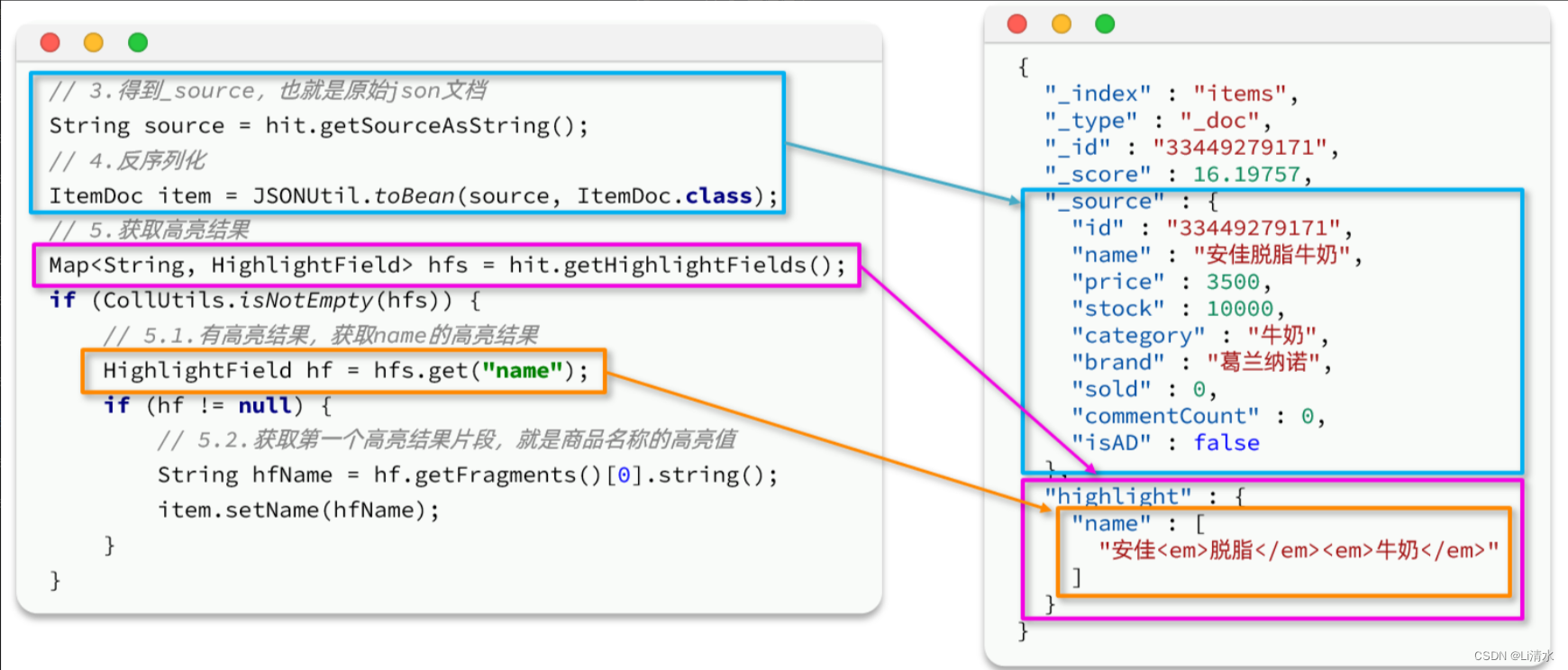 完整代码如下:
完整代码如下:
java
private void handleResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
// 1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 2.遍历结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 3.得到_source,也就是原始json文档
String source = hit.getSourceAsString();
// 4.反序列化
ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);
// 5.获取高亮结果
Map<String, HighlightField> hfs = hit.getHighlightFields();
if (CollUtils.isNotEmpty(hfs)) {
// 5.1.有高亮结果,获取name的高亮结果
HighlightField hf = hfs.get("name");
if (hf != null) {
// 5.2.获取第一个高亮结果片段,就是商品名称的高亮值
String hfName = hf.getFragments()[0].string();
item.setName(hfName);
}
}
System.out.println(item);
}
}第三章 数据聚合
聚合(
aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
聚合常见的有三类:
-
桶(
Bucket) 聚合:用来对文档做分组(类似MySQL中的groupby)-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组 -
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(
Metric**)**聚合:用以计算一些值,比如:最大值、最小值、平均值等-
Avg:求平均值 -
Max:求最大值 -
Min:求最小值 -
Stats:同时求max、min、avg、sum等
-
-
管道(
pipeline**)**聚合:其它聚合的结果为基础做进一步运算
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型;
参与聚合的字段:必须是不进行分词的。
3.1 DSL实现聚合
Bucket聚合
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
基本语法如下:
java
GET /items/_search
{
"size": 0,
"aggs": {
"category_agg": {
"terms": {
"field": "category",
"size": 20
}
}
}
}语法说明:
-
size:设置size为0,就是每页查0条,则结果中就不包含文档,只包含聚合 -
aggs:定义聚合-
category_agg:聚合名称,自定义,但不能重复-
terms:聚合的类型,按分类聚合,所以用term-
field:参与聚合的字段名称 -
size:希望返回的聚合结果的最大数量
-
-
-
来看下查询的结果:

带条件聚合
真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
例如,我想知道价格高于3000元的手机品牌有哪些,该怎么统计呢?
我们需要从需求中分析出搜索查询的条件和聚合的目标:
-
搜索查询条件:
-
价格高于3000
-
必须是手机
-
-
聚合目标:统计的是品牌,肯定是对brand字段做term聚合
语法如下:
java
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
},
{
"range": {
"price": {
"gte": 300000
}
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}聚合结果如下:
java
{
"took" : 2,
"timed_out" : false,
"hits" : {
"total" : {
"value" : 13,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"brand_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "华为",
"doc_count" : 7
},
{
"key" : "Apple",
"doc_count" : 5
},
{
"key" : "小米",
"doc_count" : 1
}
]
}
}
}可以看到,结果中只剩下3个品牌了。
Metric聚合
我们统计了价格高于3000的手机品牌,形成了一个个桶。现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
这就要用到
Metric聚合了,例如stat聚合,就可以同时获取min、max、avg等结果。
语法如下:
java
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
},
{
"range": {
"price": {
"gte": 300000
}
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": {
"stats_meric": {
"stats": {
"field": "price"
}
}
}
}
}
}可以看到我们在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
-
stats_meric:聚合名称-
stats:聚合类型,stats是metric聚合的一种field:聚合字段,这里选择price,统计价格
-
结果如下:

另外,我们还可以让聚合按照每个品牌的价格平均值排序:

总结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
-
聚合名称
-
聚合类型
-
聚合字段
聚合可配置属性有:
-
size:指定聚合结果数量
-
order:指定聚合结果排序方式
-
field:指定聚合字段
3.2 RestClient实现聚合
可以看到在DSL中,
aggs聚合条件与query条件是同一级别,都属于查询JSON参数。因此依然是利用request.source()方法来设置。不过聚合条件的要利用
AggregationBuilders这个工具类来构造。DSL与JavaAPI的语法对比如下:

聚合结果与搜索文档同一级别,因此需要单独获取和解析。具体解析语法如下:

完整代码如下:
java
@Test
void testAgg() throws IOException {
// 1.创建Request
SearchRequest request = new SearchRequest("items");
// 2.准备请求参数
BoolQueryBuilder bool = QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("category", "手机"))
.filter(QueryBuilders.rangeQuery("price").gte(300000));
request.source().query(bool).size(0);
// 3.聚合参数
request.source().aggregation(
AggregationBuilders.terms("brand_agg").field("brand").size(5)
);
// 4.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 5.解析聚合结果
Aggregations aggregations = response.getAggregations();
// 5.1.获取品牌聚合
Terms brandTerms = aggregations.get("brand_agg");
// 5.2.获取聚合中的桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 5.3.遍历桶内数据
for (Terms.Bucket bucket : buckets) {
// 5.4.获取桶内key
String brand = bucket.getKeyAsString();
System.out.print("brand = " + brand);
long count = bucket.getDocCount();
System.out.println("; count = " + count);
}
}