Embedding 是什么?
Embedding 是将自然语言词汇,映射为 固定长度 的词向量 的技术
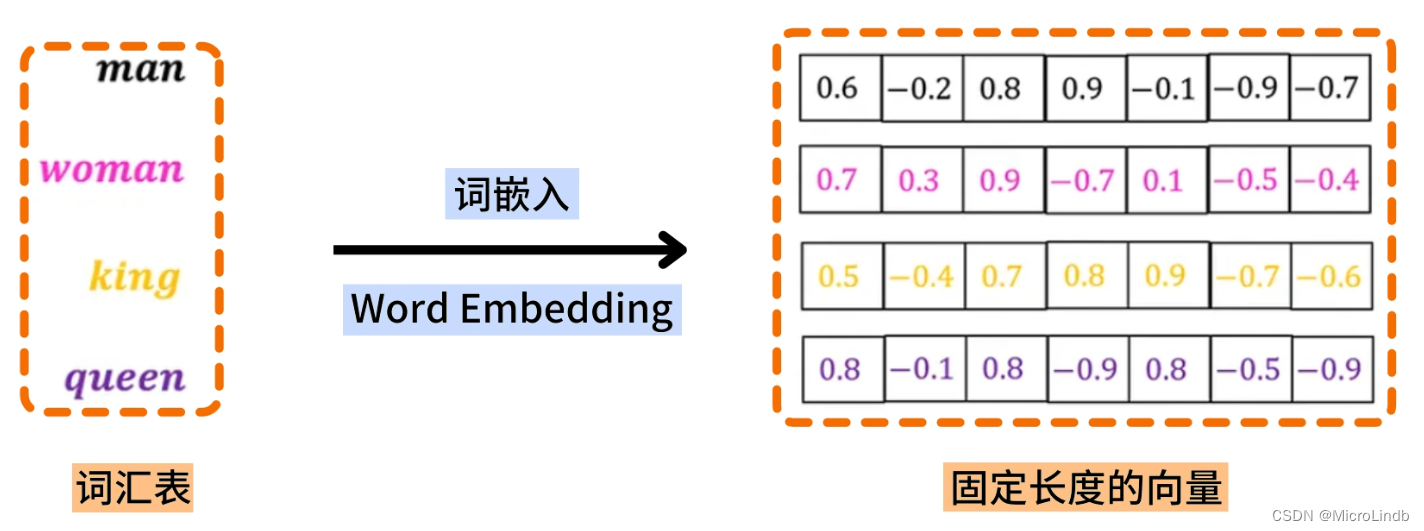
· 说到这里,需要介绍一下 One-Hot 编码 是什么。
· One-Hot 编码 使用了众多 5000 长度的1维矩阵,每个矩阵代表一个词语。
· 这有坏处,它不仅计算量更大,而且,它是 不可移植的,因为每个词汇表中,每个 One-Hot 矩阵对应的 prompt 都不同。
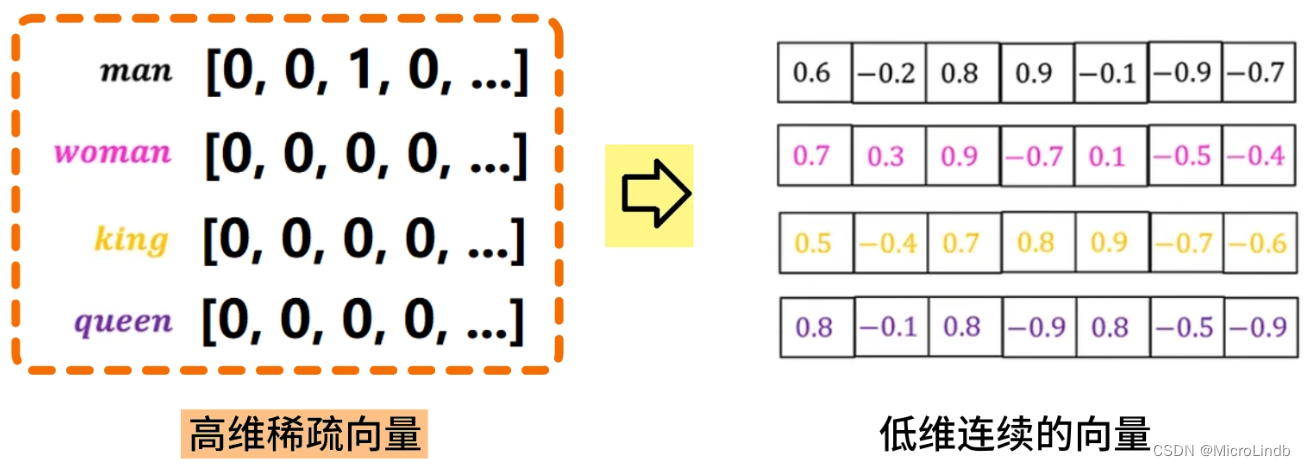
· Embedding 能够将 One-Hot 编码的高维稀疏向量(矩阵) 转化为 低维连续的向量(矩阵),请看下面的例子
来看看,降维算法能够将这些被 Embedding 转化了的向量在 2维 坐标系上展现成什么样:
很明显,意思越是不相同的词语,他们的向量距离在二维平面上也相距越远
越是意思相近的词语(cat,猫;kitten,小猫),它们的向量在二维平面上的距离越近
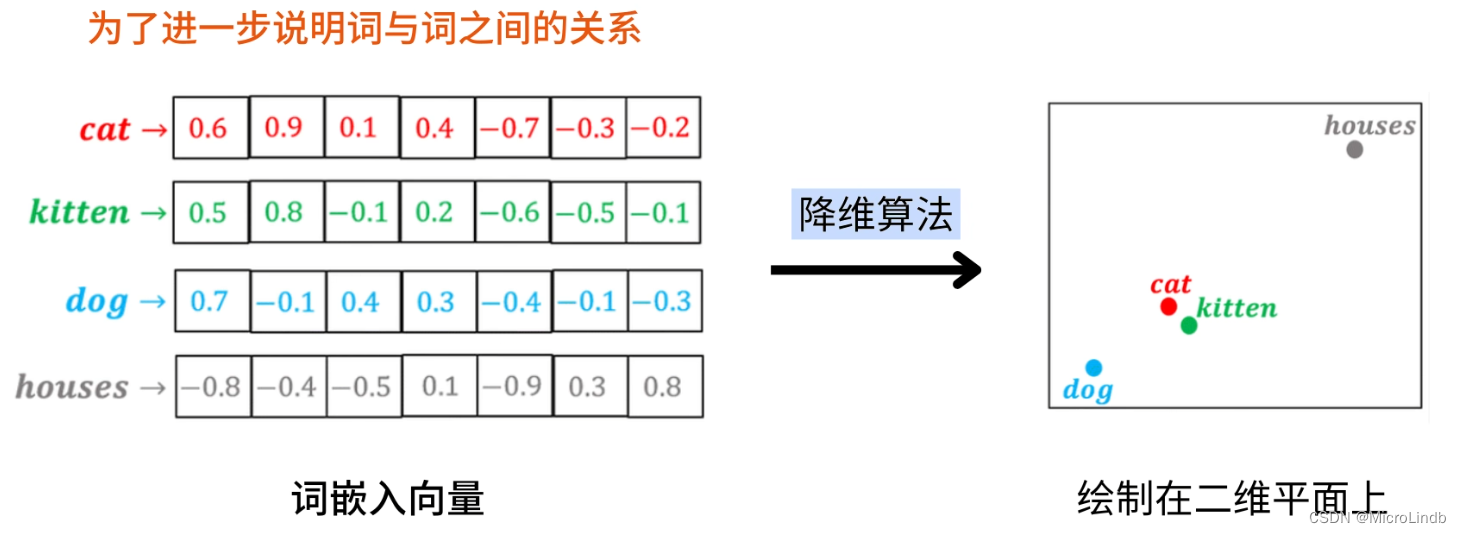
而且,有语义关联的一些词语,它们的向量也是有特殊的数学关系的:

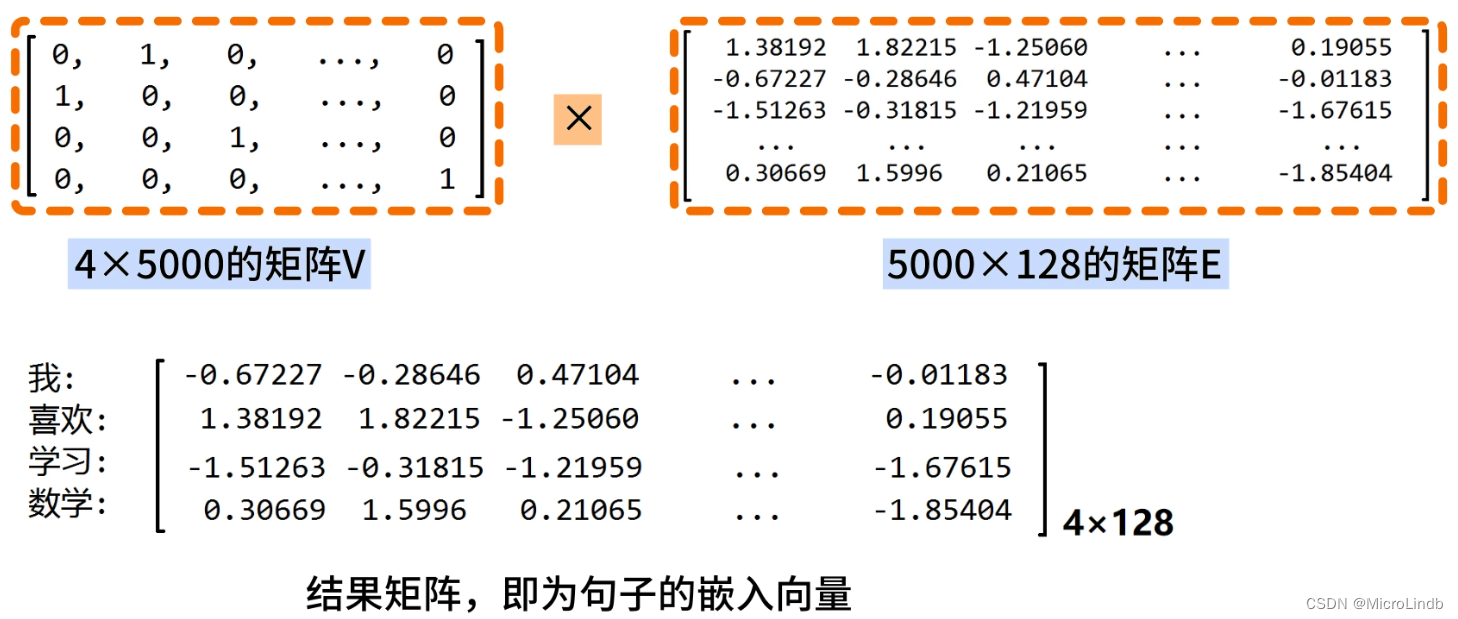
Embedding 将 text → vector 的具体过程
1.首先对句子进行处理,将句子切成单独的词语
2.被切的词语以 One-Hot 的编码格式存储

3.让代表你的词语的 One-Hot 编码的矩阵 和 嵌入矩阵(图中的矩阵E) 相乘,得到这句话的嵌入向量。
请注意,"嵌入矩阵"是提前被训练好的,也就是 Embedding 处理器 的本体。
在相乘之后,我们的自然语言句子的向量就从 4x5000的矩阵 → 4x128的矩阵
也就是,从 高维稀疏矩阵 → 低维稠密矩阵
这就是 Embedding 的作用机制!