Stable Diffusion 3: Research Paper
1. 核心理念
扩展模型 (Stable Diffusion) 在與 DALL·E 3、Midjourney v6 和 Ideogram v1这些图像生成系统相比,在书写效果以及响应指令方面表现出色。人类用户的预测性评估显示了这一点。
全新多模态扩散变换器(MMDiT)架构,在图像和语言表示之间使用了不同的参数化学习权重函数,这有助于提高 Stable Diffusion 文本理解与翻译能力。
2. 性能
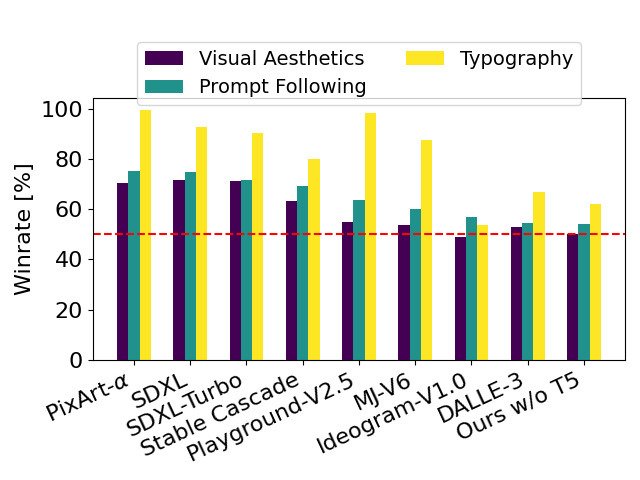
本图表以SD3为基准,揭示了该模型在与竞争对手比较时的情况。 由于这些竞争对手都是根据人类专家对视觉美学、以及字体设计进行的评分,从而确定了模型表现的领先地位。
我们在对比 Stable Diffusion 3 与其他多种开源模型,如 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5和 Pixart-α 等的输出图像后,以及使用闭源系统(例如 DALL·E 3、Midjourney v6 和 Ideogram v1)对其进行测试并评估人工评分,来判断性能。在这些测试中,给出了不同模型的输出示例以作参照,然后请求评审者按照预定义的场景("主题随机")、对文本的排版效果("字体质量")和美术表现力("视觉特色")等方面给出最高得分模型。
我们在进行测试后发现,Stable Diffusion 3的性能已经达到或超过了目前的图像生成系统在上述方面所具有的最高水平。
在对消费级硬件进行早期,未优化的卷积神经网络测试时,我们所使用的 SD3 模型最大参数量为80亿,能够轻松地放入RTX 4090中的24GB显存空间并在50个采样步长下,用时34秒就可以生成分辨率为1024×1024的图像。此外,我们还将在 SD3 初次发布期间提供多种不同版本,从参数量范围涵盖了800万到80亿之间的模型,以消除对于硬件系统造成的限制。
3. 架构细节
为了实现文本到图像生成,我们的模型需要同时考虑文字和图像两个维度。因此,我们将这种新的架构命名为多模态对称网络(MMDiT),它是指该模型可以处理多种类型数据源信息。与之前版本Stable Diffusion一样,我们仍然利用预先训练的模型来将文字和图像进行编码。具体来说,我们使用了两个CLIP模型和T5来编码文本表示,并通过一种改良版自动编码算法对图片进行编码。

我们改进的多模态扩散变换器(MMDiT)的理念概念示意图:
SD3架构是基于迁移变换模型(DiI)的一个延伸,这里的 DiI 指的是 Peebles 与 Xie(2023)发表的文章中提出的一种模型。由于语言和图像对应特征概念上存在重大区别,因此我们使用了两个不同的权重来处理这两个模式,从而能让他们保持分开运作但是也能共享信息。图中所示的就是其中的一种设置方法:将文本和图像序列连接起来进行注意力计算,这样两个模式可以在独立空间中运作,并同时考虑另一个模式。
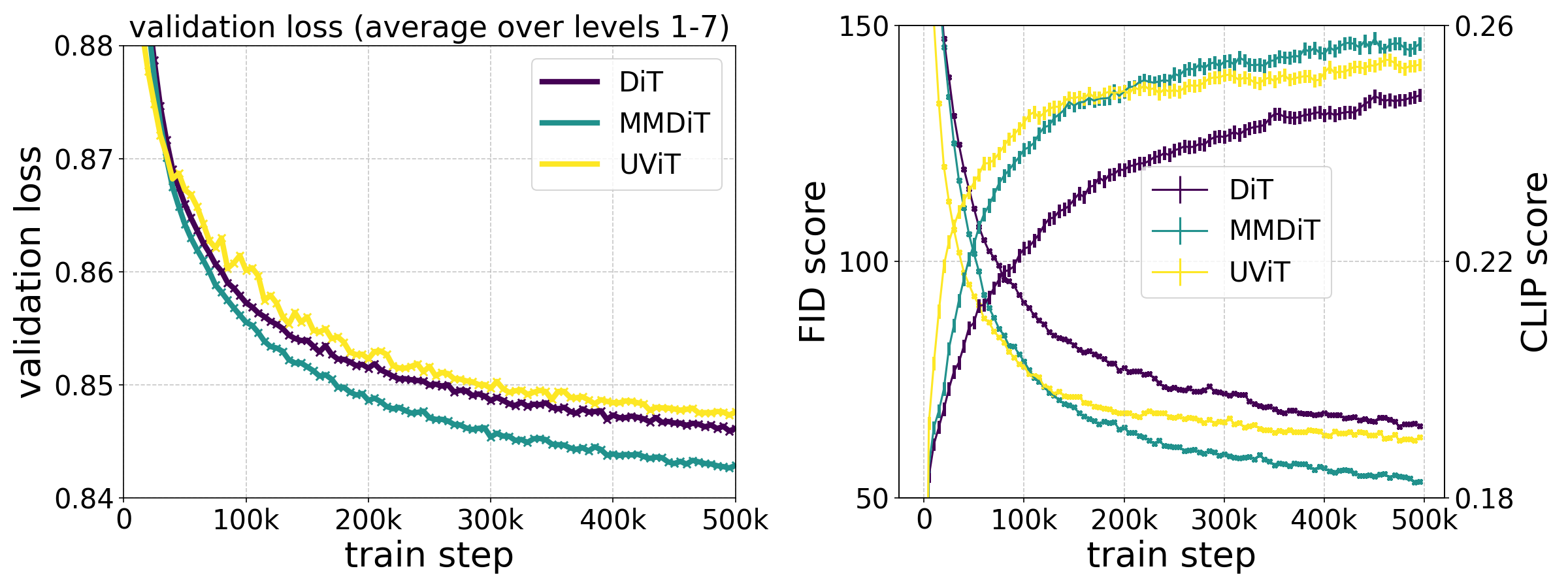
我们的 MMDiT 架构在训练过程中测量对比图像和文本同步性能时表现优于之前已有的图文转换模型,如UViT(Hoogeboom et al,2023)和DiT(Peebles 与 Xie,2023)。
通过此方法,图片和文字元素之间的信息流动能够提高输出内容的整体理解效率并改善其美学表现,我们在本文讨论了视频模式等多模态扩展方案。

随着 Stable Diffusion 3 的升级后的提示方式,我们的模型能够创作出涵盖多种不同主题和特点并且可以随意转换形象风格的图像。

4. 改进加权Rectified Flows方法
稳定扩散3采用Rectified Flows(RF)方程式,该方法在训练过程中将数据与噪音连接到了直线路径上,这样一来就会导致生成过程更加平滑。相反地,传统RF方法使得推理过程的途径显得曲折不清。这将影响到后续的扫描过程。为了缩小训练路径,我们设计了一种新方法------使用反向流动力学模型对特定数据和随机信息进行连接。这些操作可以提高中间部分的权重,因为我们认为在这些部分训练过程会变得更加复杂。与传统方法相比,我们所设计的方法能够有效地改善环境,而且在60种其他数据流中对比后显示出了良好的表现,并且用了多个测试数据集、指标以及取样方式进行比较。相关结果表明:传统RF方法在步数少的情况下有所改善,但随着步长增加,其表现反而会变得更差。相反地,我们新设计的模型则能在不同样本和指标情况下保持良好水平,并且在更多样本、更复杂指标环境中表现优异。
5. 增益Rectified Flow Transformer模型
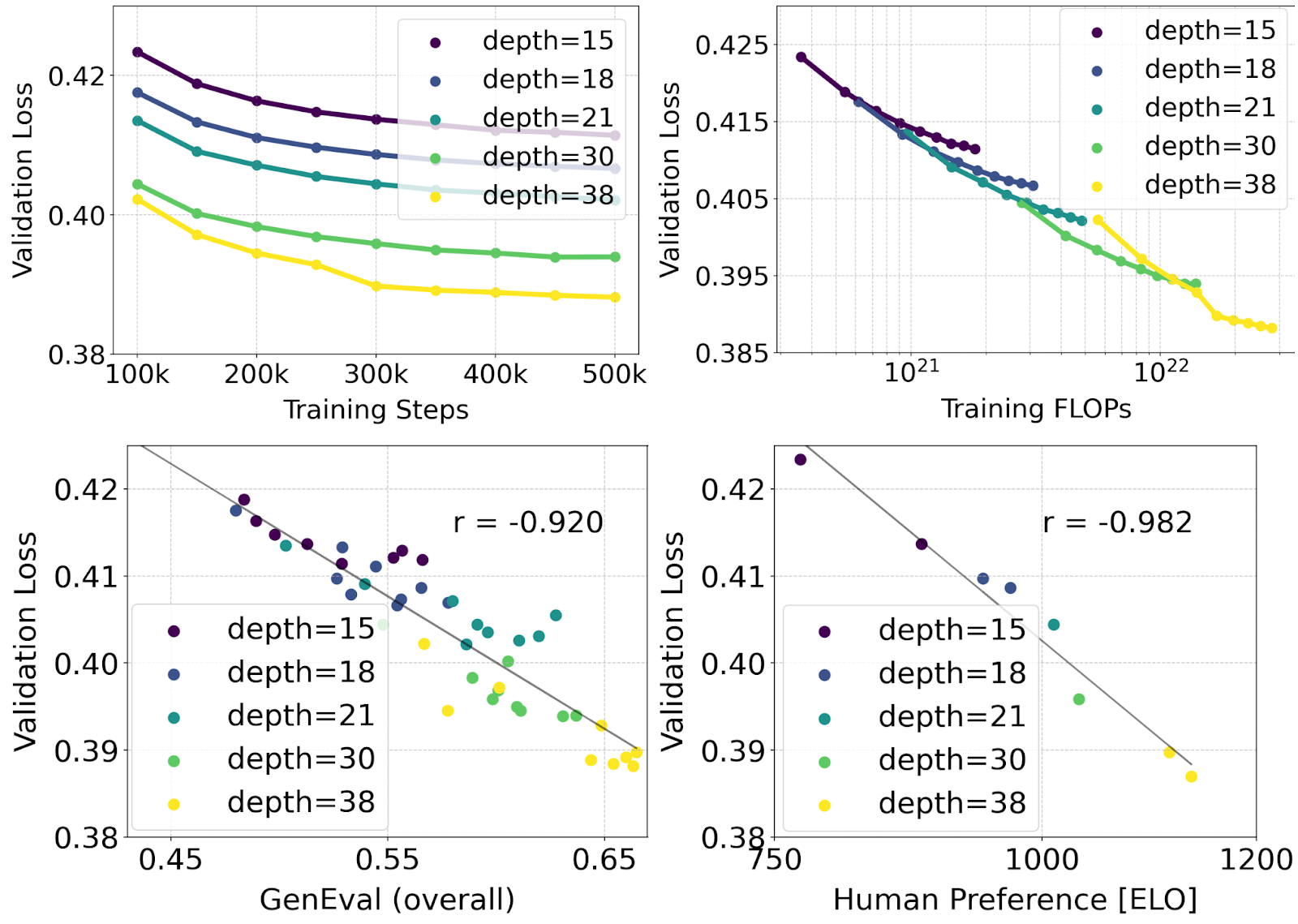
我们使用重叠流扩展的量化形式及MMDiT骨干网络进行了对图像从文本生成的混合效应性评估,并通过这些模型在不同层次上、以不同参数量进行学习来研究其可适用性。我们训练了从15个块到38个块的网络,并涵盖了4.5亿参数和80亿参数不同类型模型。通过测试自动图像对齐度评估量表(GenEval)及人工审查者评分(ELO),我们发现与验证损失之间存在明显的下降性关系(上图中最上方的维度)。这种趋势表明,模型大小及训练步数都与该指标有相关性。结果还表明,我们能根据验证损失观测到的趋势来预测这种模型在实际应用中的效率(下图中最下方)。而且从训练过程中收集的数据表明,我们能持续改进该模型性能。尽管早期观测得到了这种结果,但在后续研究中可能还会发现其他途径来提高模型的效率。
6. 可变长字符编码器
在排除预测过程中的具有大量内存需求的 T5 4.7B 参数字符编码器后,SD3 的内存消耗可以显著降低,而且功能性损失相当小。如果删除该文本编解码器不会影响视觉效果(上图中输入区无 T5 时的准确率为 50%),并且也不会改变字体表现力(输出区无 T5 时的准确率为 46 %,见图片下方"性能"一栏所示)。然而我们建议在使用 SD3 这个应用程序时使用该文本编解码器,因为从我们的测试结果来看,没有 T5 的情况下,字体表现力会明显降低(输出区无 T5 时的准确率为 38 %)。见下图所示:

只使用推理时不使用T5,对于处理复杂的提示,尤其是要求采用大量细节或字数较多的提示时会出现显著性能下降。上图为每个例子中分布式样本三个随机抽取点(3RSP)。
了解更多关于MMDiT、增益流体动力学和驱动Stable Diffusion 3研究成果的信息,请查看我们的完整研究论文。