Linux:线程概念 & 线程控制
线程概念
假设某个进程要在输出1 - 10的同时,让另外一个执行流去输出11 - 20,应该怎么办?
如果从进程的角度出发,我们可以创建一个子进程,让父子进程同时跑,比如这样:
cpp
int main()
{
pid_t id = fork();
//子进程
if (id == 0)
{
for (int i = 1; i <= 10; i++)
{
cout << i << endl;
sleep(1);
}
exit(0);
}
//父进程
for (int i = 11; i <= 20; i++)
{
cout << i << endl;
sleep(1);
}
return 0;
}输出结果:
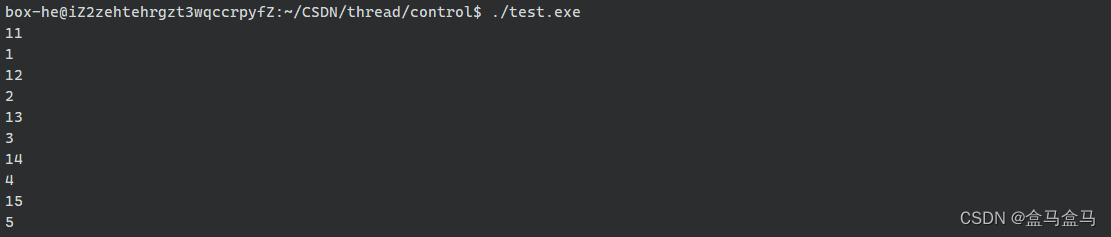
这样确实可以做到让两个执行流同时运行,从而提高效率,但是代价太大了。这种方式是通过创建一个子进程实现的,而一个进程需要额外创建PCB,进程地址空间,页表等等。
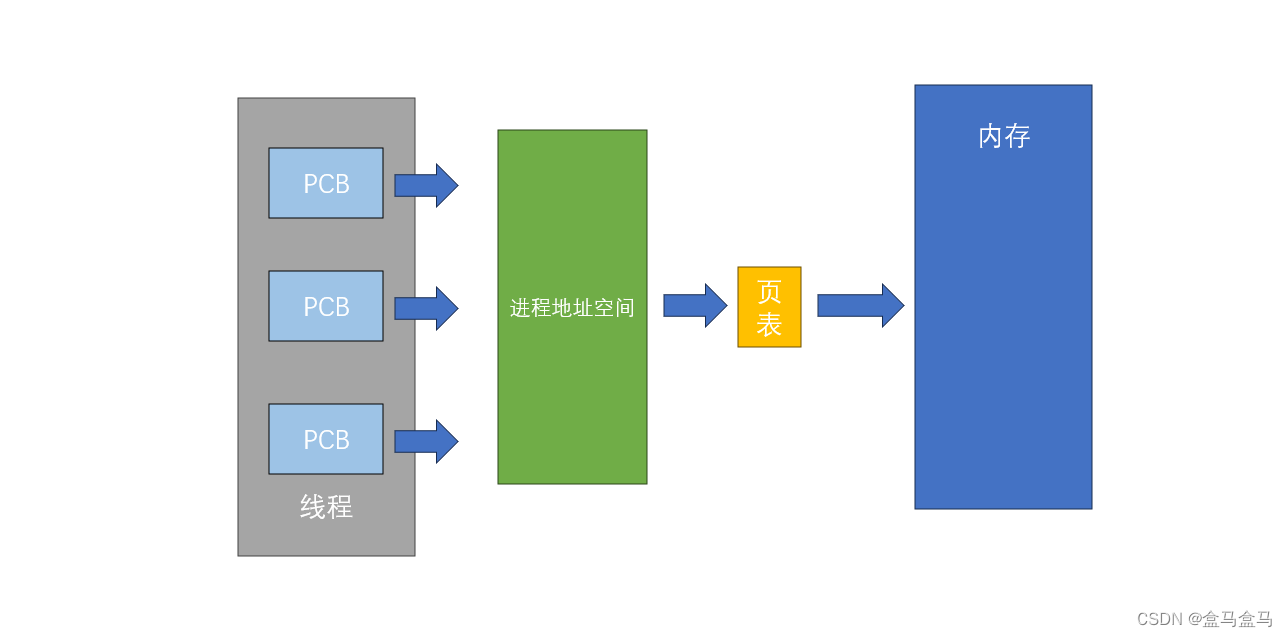
在CPU调度进程的时候,本质是在调度进程的PCB,把进程的PCB放到运行队列中,然后CPU依次执行队列中的进程。也就是说,如果我们想要让一个进程被CPU多次执行,从而让一个进程有多个执行流,只需要创建更多的PCB就可以了。在没学习到线程前,我们认为一个进程只有一个PCB,实则不然,一个进程可以有多个PCB(仅对Linux而言)。
而对于同一个进程的每一个PCB,都算作一个线程。
线程是进程内部的一个执行分支,是
CPU调度的基本单位
每个线程都会拿到同一个进程的不同部分代码,从而让多个区域的代码一起执行,提高进程的效率。
我们再辨析一下进程与线程的关系:
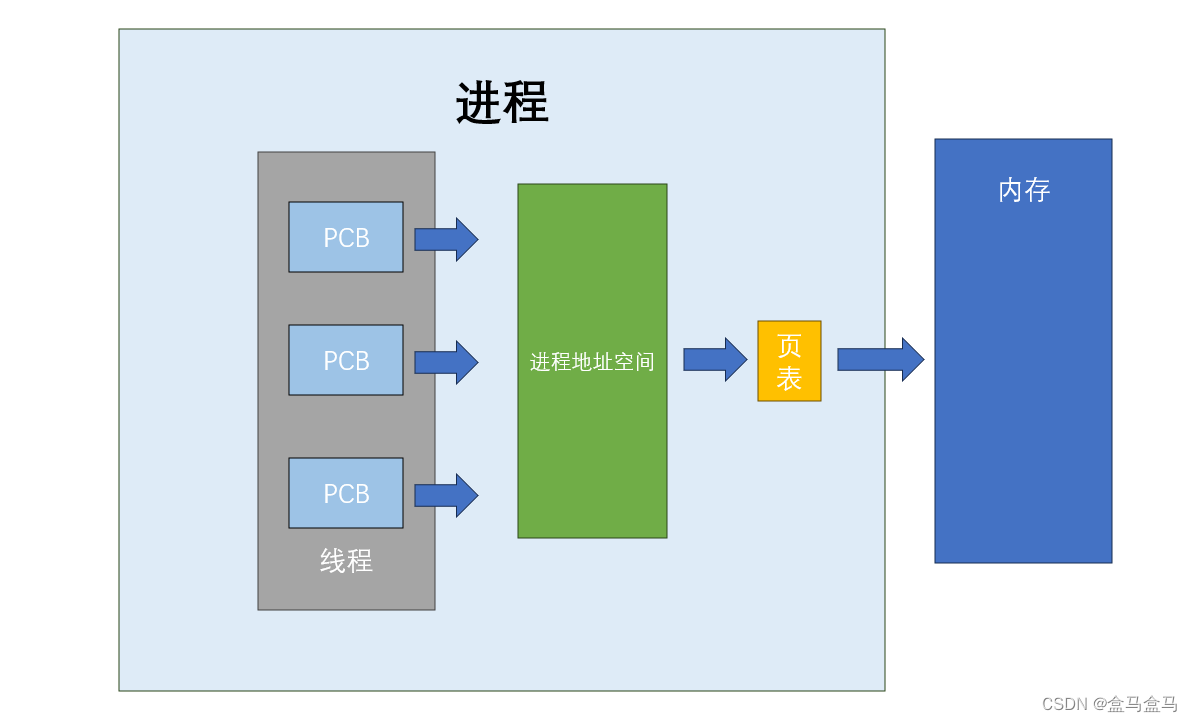
进程 = 内核数据结构 + 代码和数据
上图中,多个PCB,进程地址空间,页表等都属于进程的内核数据结构,因此这些所有内容加起来,才算做进程。
进程是承担系统资源分配的基本实体
因为多个线程是共享地址空间,页表等等,所以一个线程不可能去承担系统的资源分配,反而来说,线程是被分配资源的。操作系统分配资源时,以进程为单位,当一个进程拿到资源后,再去分配给不同的线程。
轻量级进程 LWP
其实我刚刚的所有描述,都是针对Linux而言的。大部分操作系统的处理线程的方式,并不是直接创建多个PCB,而是额外设计了一个TCB (Thread Contrl Block):
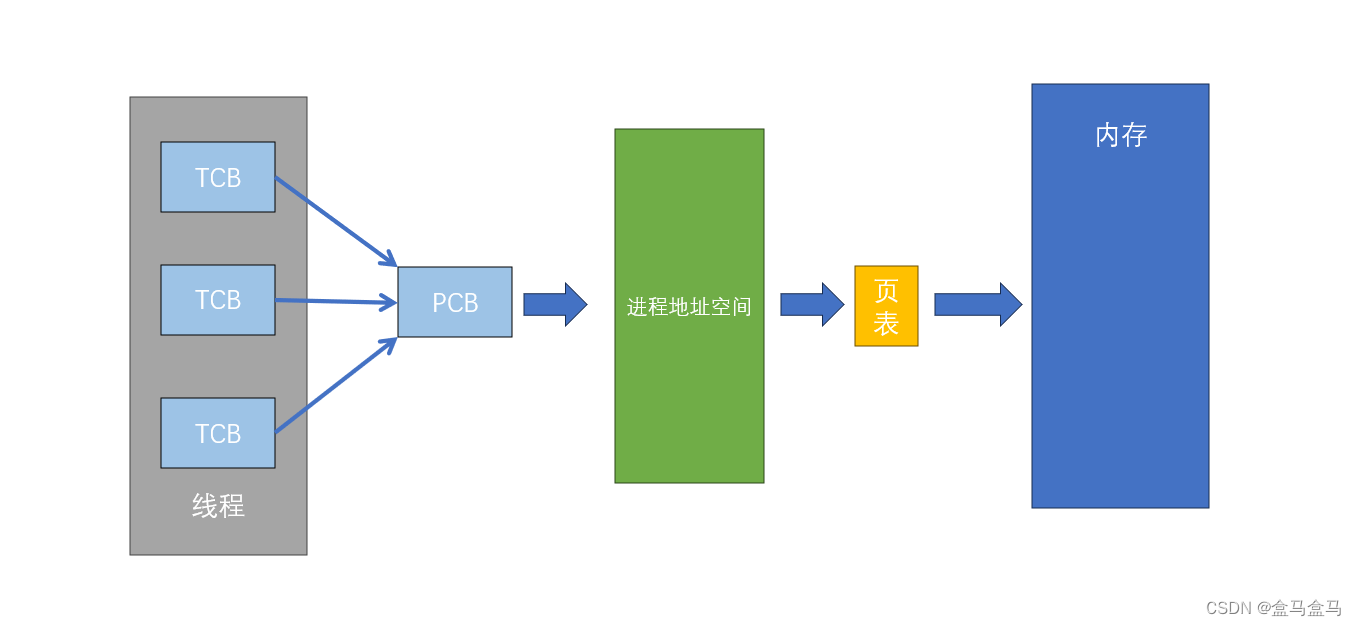
多个TCB分别控制不同部分的代码,CPU调度线程时,也去调度TCB。比如主流的Windows,MacOS等操作系统,都是这样做的。
但是Linux认为:PCB就已经可以被CPU调度了,进程调度已经有一套很完善的体系了,如果再额外给线程设计一套线程的调度解决方案,未免太多余了。因此Linux中没有设计TCB这样的结构,而是直接复用PCB来实现线程。
在Linux中,一个进程可以有多个PCB,当PCB的数目为1,那么这个PCB可以代表一个进程;如果PCB数目有多个,那么这个PCB代表一个进程的多个线程。
因此在Linux中,没有真正的线程,一个执行流由一个PCB维护。一个执行流既有可能表示一个进程,也有可能表示一个线程。Linux把这种介于线程与进程之间的状态,称为轻量级进程 LWP (Light Weight Process)。
Linux中所有对线程的操作,本质都是对轻量级进程的操作
接下来在一个进程内部创建两个线程,观察一些现象。如何创建线程,在本博客的线程控制部分会讲解,现在大家只需要观察现象,知道我的一个进程内部有两个线程即可。

上图中,为两个线程同时输出,第一个线程输出I am thread - 1,第二个线程输出I am thread - 2。
我们先通过 ps -ajx观察一下进程test.exe的状态:

看可以看到只有一个进程,PID = 141776,也就是这两个线程同属于一个进程。
如果想要观察线程,需要指令ps -aL:

可以看到,确实是有两个叫做test.exe的线程的,它们的PID都是141776,但是它们的LWP不同。一个LWP = 141776,另外一个LWP = 141777,而LWP就是我们刚刚说的轻量级进程。
另外的,你会发现第一个线程的PID = LWP = 141776,说明这个线程是主线程,其余的所有线程都是这个主线程创造的。
页表
那么进程是如何实现把资源分配给多个线程的呢?这就要谈一谈页表了。
先看一看内存与磁盘是如何管理的:
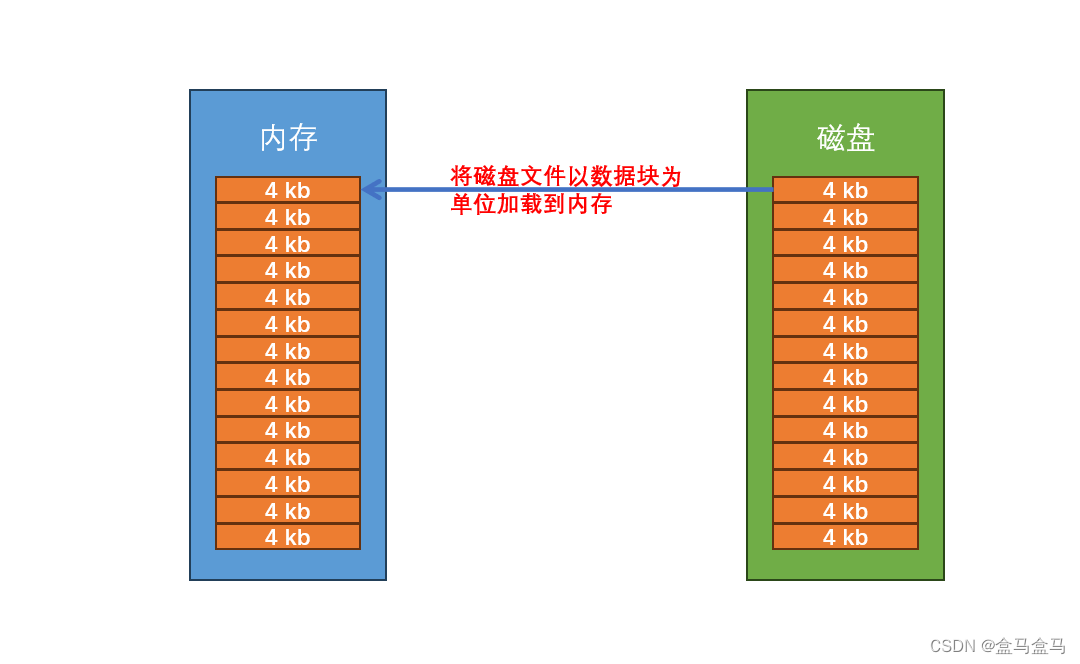
不论是内存还是磁盘,都被划分为了以4kb为单位的数据块,一个数据块可以被称为页框 / 页帧。
操作系统管理内存,或者管理磁盘,都是以4kb为基本单位的。比如把磁盘中的数据加载到内存中,就是以4kb为基本单位进行拷贝id。
页框是被struct page管理的,Linxu 2.6.10中,struct page源码如下:
cpp
struct page
{
page_flags_t flags;
atomic_t _count;
atomic_t _mapcount;
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
#if defined(WANT_PAGE_VIRTUAL)
void *virtual;
#endif
};操作系统想要管理所有的页框,只需要创建一个数组,数组的元素类型是struct page。此时操作系统对内存或磁盘的管理,就变成了对数组的增删查改。而且从上方的struct page源码中可以发现,它是不存储页框的起始地址和终止地址的,因为可以通过下标计算出起始地址,起始地址 + 4kb就可以求出终止地址。
那么这个页框和页表有什么关系呢?
我们以32位操作系统为例,页表的结构如下:
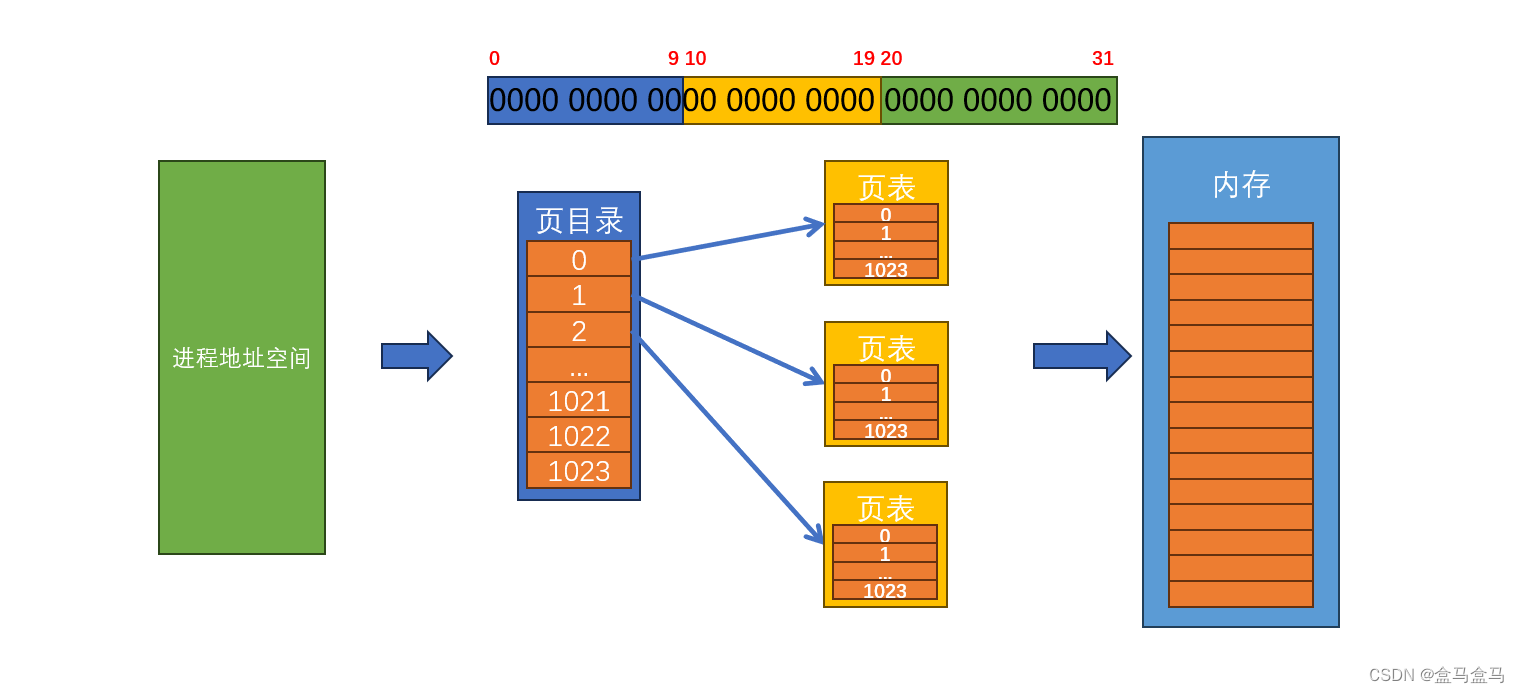
页表的任务是把虚拟地址解析为物理地址,当传入一个虚拟地址,页表就要对其解析。一个32位的地址,会被分为三部分,第一部分是前10位,第二部分是中间10位,第三部分是末尾12位。
第一部分就是上图中的深蓝色部分,其由页目录进行解析。 2 10 = 1024 {\color{Red} 2 ^ {10} = 1024} 210=1024,即前10位地址有1024种可能,而页目录就是一个长度为1024的数组。解析地址时,先通过前10位,在页目录中找到对应的下标。每个页目录的元素,指向一个页表。
第二部分是上图中的黄色部分,其由页表进行解析,同样的 2 10 = 1024 {\color{Red} 2 ^ {10} = 1024} 210=1024,即中间10位地址也1024种可能,所以每个页表的长度也是1024。解析中间10位时,在页表中找到对应的下标,从而找到对应的内存。
第三部分时上图中的绿色部分。还记得吗,一个数据块的大小是4 kb,这是内存管理的基本单位。而 2 12 b y t e = 4 k b {\color{Red} 2 ^ {12} byte = 4 kb} 212byte=4kb,而第三部分就是12位!因此第三部分也叫做页内偏移,通过前两个部分,我们已经可以锁定到内存中的一个页框了,而第三部分存储的是物理地址相对于页框起始地址的偏移量,此时就可以根据起始地址 + 偏移量来确定一个地址。
以上就是页表解析地址的全过程。
那么这和线程的资源分配有什么关系呢?
我们可以看到,一个页目录把整个页表划分为了1024部分,一个部分能映射的总地址数目位4kb * 1024 = 4mb。
给不同线程分配进程不同的区域,本质就是让不同进程看到页表的不同子集
线程控制
POSIX 线程库 - ptherad
讲完基本概念后,我们再看看如何控制线程。Linux控制线程,是通过原生线程库pthread的。
Linux中本质上是没有线程的,而是通过轻量级进程来模拟线程。因此 Linux 没有线程相关的系统调用接口,而是轻量级进程的系统调用接口。为了让用户感觉自己在操控线程,因此所有Linux系统都会必须配套一个 原生线程库 pthread,将轻量级进程的系统调用,封装为线程的操控,让用户感觉自己在操控线程。
之所以叫做原生线程库,就是因为所有Linux系统必须配备这个库,是原生的。因为库属于用户操作接口的范围,所以Linux的线程也叫做用户级线程。
在使用
gcc / g++编译时,要带上选项-l pthread,来引入原生线程库
例如:
cpp
g++ -o test.exe test.cpp -l pthread那么简单了解什么是线程库后,接下来就要讲解线程相关接口了。
在讲解接口前,先铺垫一个概念:TID,所有线程库对线程的操作,都是基于TID的。这个TID用于标识一个唯一的线程。TID与LWP不是一个东西,不要搞混。
TID的数据类型是pthread_t。
线程创建
pthread_create
ptherad_create函数用于创建一个线程,需要头文件<pthread.h>,函数原型如下:
cpp
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);参数:
thread:输出型参数,输出创建出来的线程的TIDattr:设置线程的状态,这个不用管,设为nullptr即可start_routine:类型为void* (*)(void*)线程执行的函数的函数指针arg:用于给新的线程传递参数,也就是给函数start_routine传参,该函数的第一个参数为void*类型,arg也是void*
返回值:
- 如果创建成功,返回
0 - 如果创建失败,返回错误码
示例:
cpp
void *threadRun(void *args)
{
string name = (char *)args;
while (true)
{
cout << name << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRun, (void *)"thread - 1");
while (true)
{
cout << "thread - main" << endl;
sleep(1);
}
return 0;
}以上代码中,先创建一个pthread_t类型的tid,随后通过pthread_create创建一个线程。
- 第一个参数
&tid,即创建线程后把该线程的TID输出到变量tid中; - 第二个参数
nullptr,不用管; - 第三个参数
threadRun,即创建出来的线程去执行这个函数; - 第四个参数
(void *)"thread - 1",即函数threadRun的第一个参数传入一个字符串,由于参数类型是void*,要进行一次类型转换。
随后主线程循环输出"thread - main",创建的线程把参数args提取出来变成string,string name = (char *)args;,再输出这个string。
输出结果:

现在就有两个线程同时在跑了,而且我们成功把字符串thread - 1通过参数传给了新创建的线程。
pthread_self
ptherad_self函数用于得到当前线程的TID,需要头文件<pthread.h>,函数原型如下:
cpp
pthread_t pthread_self(void);返回值:当前线程的TID。
线程退出
讲解线程退出的相关接口前,我们来看一个实验:
如果某个线程调用
exit接口,会发生什么
代码:
cpp
void *threadRun(void *args)
{
string name = (char *)args;
int cnt = 3;
while (cnt--)
{
cout << name << endl;
sleep(1);
}
exit(0);
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRun, (void *)"thread - 1");
while (true)
{
cout << "thread - main" << endl;
sleep(1);
}
return 0;
}以上代码十分简单,就是在刚才的代码中多加了一句exit而已。主线程创建完线程后,死循环输出thread - main。而创建出来的线程在输出三次thread - 1后通过exit退出。
按理来说,创建出来的线程通过exit退出后,此时就只剩主线程了,于是一直循环输出thread - main。所以预测现象为:输出三次thread - 1后,剩下的全是thread - main。
输出结果:

奇怪的现象发生了,当thread - 1通过exit退出后,主线程也退出了。
exit接口的作用,是终止整个进程,任意一个线程调用该接口,所有线程都会退出
因此我们不能通过exit来退出一个线程。
pthread_exit
ptherad_exit函数用于退出当前线程,需要头文件<pthread.h>,函数原型如下:
cpp
void pthread_exit(void *retval);在pthread_create时,线程执行的函数类型就是void* (*)(void*)也就是说线程调用的函数返回值是void*。退出线程pthread_exit时,第一个参数retval就是用于指定这个返回值的。
pthread_cancel
ptherad_cancel函数用于在主线程中指定退出一个线程,需要头文件<pthread.h>,函数原型如下:
cpp
int pthread_cancel(pthread_t thread);参数:thread是要杀掉的线程的TID
pthread_join
线程和进程一样,也有等待的机制,用于获取线程的退出信息,这个过程叫做线程等待,而线程等待就是通过pthread_join完成的。
pthread_join函数用于等待一个线程,需要头文件<pthread.h>,函数原型如下:
cpp
int pthread_join(pthread_t thread, void **retval);参数:
thread:等待的线程的TIDretval:输出型参数,线程退出后,该参数会接收到线程的函数返回值
返回值:
- 等待成功:返回
0 - 等待失败:返回错误码
ptherad_join会进行阻塞式等待。
示例:
cpp
void* threadRun(void* args)
{
string name = (char*)args;
int cnt = 3;
while (cnt--)
{
cout << name << endl;
sleep(1);
}
return (void*)12345;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRun, (void*)"thread - 1");
void* ret;
pthread_join(tid, &ret);
cout << "return value = " << (long long) ret << endl;
return 0;
}以上代码中,创建的线程输出三次"thread - 1"后退出,返回值为数字12345。主线程中通过join等待这个线程,并把返回值保存到变量ret中。随后输出这个结果,因为ret是指针,输出时先转为long long再输出。
输出结果:

可以看到,主线程成功通过pthread_join拿到了线程的返回值。
如果我们通过pthread_exit终止线程,该函数的第一个参数就是函数返回值,那么pthread_join得到的返回值就是pthread_exit的参数。
但是如果通过pthread_cancel终止线程,由于该函数没有指定线程的返回值,此时pthread_join得到的返回值是固定值PTHREAD_CANCELED。
pthread_detach
线程都是要被释放的,如果一个线程退出后没有被pthread_join,就会造成内存泄漏。但是如果你真的不希望去回收一个线程,你可以进行线程分离,被分离的线程,退出后会自己回收自己。
pthread_detach函数用于等待一个线程,需要头文件<pthread.h>,函数原型如下:
cpp
int pthread_detach(pthread_t thread);参数:thread是被分离的线程的TID
返回值:
- 分离成功:返回
0 - 分离失败:返回错误码
一个线程被分离后,不允许再被pthread_join等待,等待会发生错误。
pthread_detach既可以在主线程中对创建出来的线程使用,也可以线程自己对自己使用。
我们以后者作为示例:
cpp
void *threadRun(void *args)
{
pthread_detach(pthread_self());
while(true) ;
return (void*)12345;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRun, (void *)"thread - 1");
cout << "join..." << endl;
int ret = pthread_join(tid, nullptr);
cout << ret << ": " << strerror(ret) << endl;
return 0;
}以上代码中,在线程的函数中,自己分离自己pthread_detach(pthread_self()),随后创建的线程陷入死循环。
主线程中,强行pthread_join这个已经分离的函数,并输出错误码。
输出结果:

可以看到,由于等待了一个已经分离的线程,此时pthread_join的返回值就是22号错误Incalid argument
线程架构
线程与地址空间
依然是这一张图,我们之前一直没有讨论一个问题,那就是所有的线程共享一个进程地址空间。这意味着多个线程是可以访问同一个变量的,比如说一个全局变量g_val,我们可以在任意一个线程中访问它,一个线程修改了这个值,其余的线程的g_val也会受到影响。
示例:
cpp
int g_val = 5;
void* threadRun(void* args)
{
cout << "g_val = " << g_val << " &g_val = " << &g_val << endl;
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadRun, nullptr);
sleep(1);
cout << "g_val = " << g_val << " &g_val = " << &g_val << endl;
return 0;
}以上代码中,先创建了一个全局变量g_val,随后创建一个线程。
主线程与被创建的线程,都输出g_val的值与g_val的地址。
输出结果:

两个线程的g_val不论是值还是地址,都是一模一样的,说明就是同一个g_val。
如果你希望对于一个变量,每个线程都维护一份,互不影响,此时可以使用线程局部存储。
只需要在变量前面使用__thread(注意前面有两条下划线)修饰即可,比如这样:
cpp
__thread int g_val = 5;再次输出:

这次两个线程的g_val地址就不同了。
当然,线程之间不是啥都共享的,也有各自独立的部分:
- 线程PID
- 一组寄存器 / 硬件上下文 :因为线程是调度的基本单位,线程调度是需要上下文来记录自己的调度相关信息的,这个必须每个线程各自一份
- 栈帧 :也是因为线程是调度的基本单位,每个线程都在执行自己的函数栈,这个栈也是各自独立
- errno:线程之间的错误码各自独立
- 信号屏蔽字 :当一个进程收到信号,此时所有线程都会收到信号,但是每个线程的处理方式可以不同,就是通过每个线程独自维护一份
block达到的 - 调度优先级:同理,因为线程是调度的基本单位,线程之间可以有不同的优先级
线程与pthread动态库
我先前说过,线程的控制是通过pthread库实现的,毫无疑问pthread是一个动态库。线程需要被结构体描述,同时再被数据结构组织,这样才好管理一群线程,这个任务是pthread库完成的。
如下图:
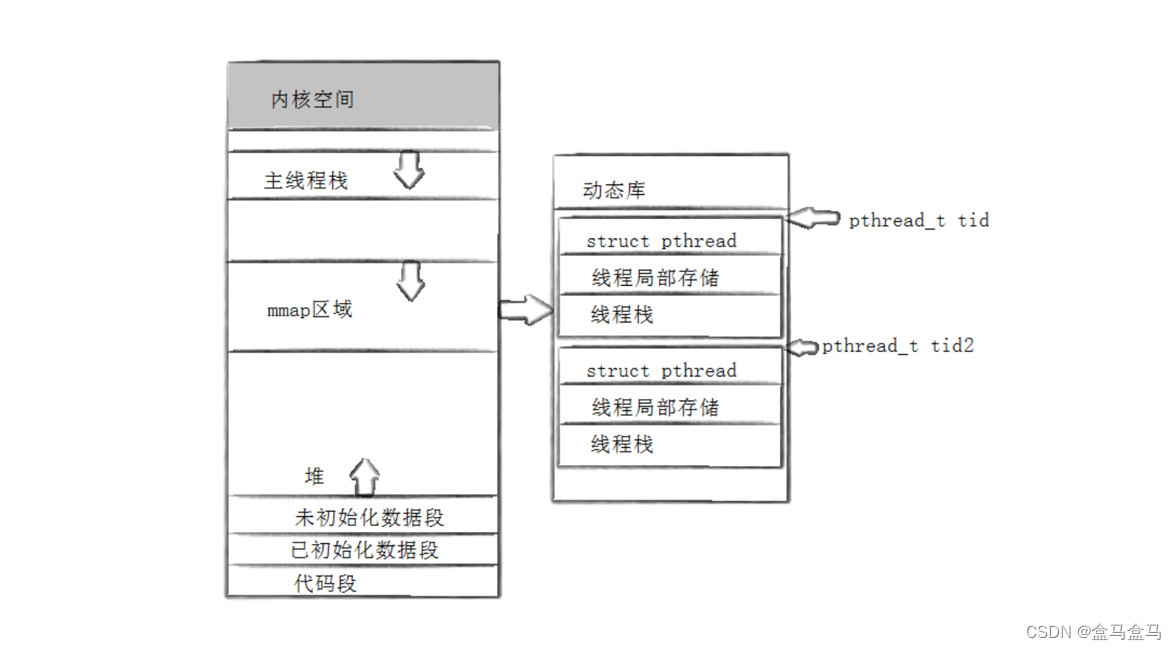
在pthread库中,通过结构体struct pthread来管理一个线程,在这给结构体中会存储很多线程之间独立的部分。我们刚讲过的线程局部存储,栈帧,TID,这几个部分就是保存在struct pthread中的。
还记得我们在说过,TID是一个线程的唯一标识符吗?我们来输出一下这个TID试试:
cpp
int main()
{
cout << pthread_self() << endl;
return 0;
}直接通过pthread_self拿到自己的TID,然后输出。
输出结果:

可以发现,这是一个很大很大的数字,这是为啥?
TID就是线程的struct pthread在内存中的物理地址
你不妨想想,为什么所有对线程的操作中,基本都带上了参数TID,因为通过TID,线程可以直接找到对应的物理地址,从而访问线程的更多信息。
在Linux中,标识一个轻量级进程是通过LWP完成的,在struct pthread内部,一定有一个成员是该线程对应的轻量级进程的LWP,进而完成用户操作线程到库操作轻量级进程的转换。
线程的优缺点
线程有如下优点:
创建一个新线程的代价要比创建一个新进程小得多
创建一个线程只需要额外创建一个PCB,进程地址空间,页表等都和别的线程共用,因此创建线程代价很小
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
由于线程共用进程地址空间和页表,在CPU切换调度的PCB时,如果两个PCB属于同一个进程的不同线程,那么它们的进程地址空间和页表都不用更新,因为它们共用,此时CPU就可以少加载很多数据。
在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
一般来说,I/O是很慢的操作,如果主线程一直等待I/O,效率就会很低下。这种需要阻塞等待的任务,建议创建其它线程,让其他线程去做。这样I/O对程序的运行效率影响就低很多,因为等待I/O的同时,主线程可以去做其他任务。
计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
所谓计算密集型应用,就是该程序主要功能是利用CPU进行计算。此时线程个数不建议太多,因为线程的调度也是需要消耗CPU资源的,此时最好让CPU多执行计算,而不是去频繁调度。
I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
所谓I/O密集型应用,就是说程序大部分时间都在I/O,此时建议多创建一些线程,让线程去I/O。
线程缺点如下:
- 线程的频繁调度也要消耗资源,可能会和计算争夺
CPU资源,导致计算效率降低,比如计算密集型应用就不太适合创建太多线程 - 程序健壮性降低,因为多线程的代码很难维护,不好控制