目录
【命题追踪------十进制小数转换为二进制小数(2021、2022)】
[2.1.2 定点数的编码表示](#2.1.2 定点数的编码表示)
【命题追踪------补码的表示范围(2010、2013、2014、2022)】
【命题追踪------补码和真值的相互转换(2020、2023)】
【命题追踪------机器码与补码、无符号数之间的转换(2021)】
[2.1.4 C语言中的整数类型及类型转换](#2.1.4 C语言中的整数类型及类型转换)
[【命题追踪------int 型数据的表示范围(2017、2019)】](#【命题追踪——int 型数据的表示范围(2017、2019)】)
【命题追踪------有符号数与无符号数的相互转换(2011、2016、2019)】
【命题追踪------无符号数的零扩展(2012),补码的符号扩展(2021)】
2.1数制与编码
2.1.1进位计数制及其相互转换
【命题追踪 ------采用二进制编码的原因(2018)】
在计算机系统内部,所有信息都是用二进制进行编码的,这样做的原因有以下几点。
-
二进制只有两种状态,使用有两个稳定状态的物理器件就可以表示二进制数的每一位,制造成本比较低,例如用高低电平或电荷的正负极性都可以很方便地表示0和1。
-
二进制位1和0正好与逻辑值"真"和"假"相对应,为计算机实现逻辑运算和程序中的逻辑判断提供了便利条件。
-
二进制的编码和运算规则都很简单,通过逻辑门电路能方便地实现算术运算。
【命题追踪 ------十进制小数转换为二进制小数**(2021、2022)**】
一个十进制数转换为任意进制数,通常采用基数乘除法。这种转换方法对十进制数的整数部分和小数部分将分别进行处理,对整数部分采用除基取余法,对小数部分采用乘基取整法,最后将整数部分与小数部分的转换结果拼接起来。
**【例 2.2】**将十进制数 123.6875 转换成二进制数。
解:
除基取余法(整数部分):整数部分除基取余,最先取得的余数为数的最低位,最后取得的余数为数的最高位(即除基取余,先余为低,后余为高),商为0时结束。
整数部分:
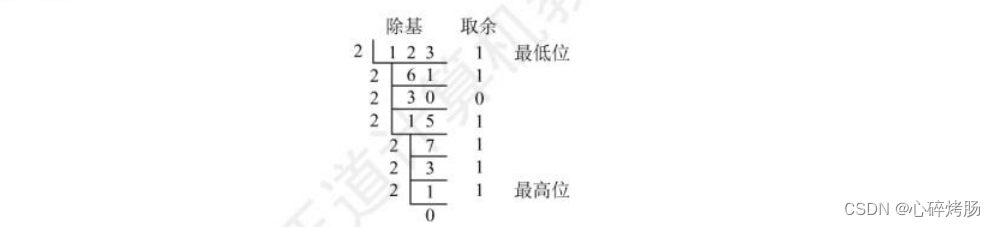
因此整数部分 123=(1111011)₂。
乘基取整法(小数部分):小数部分乘基取整,最先取得的整数为数的最高位,最后取得的整数为数的最低位(即乘基取整,先整为高,后整为低),乘积为1.0(或满足精度要求)时结束。
小数部分:

因此小数部分0.6875=(0.1011)₂,所以 123.6875=(1111011.1011)₂。
注意:关于十进制数转换为任意进制数为何采用除基取余法和乘基取整法,以及所取之数放置位置的原理,请结合r进制数的数值表示公式思考,而不应死记硬背。
注意:在计算机中,小数和整数不一样,整数可以连续表示,但小数是离散的,所以并不是每个十进制小数都可以准确地用二进制表示。例如 0.3,无论经过多少次乘二取整转换都无法得到精确的结果。但任意一个二进制小数都可以用十进制小数表示,希望读者引起重视。
2.1.2 定点数的编码表示
【命题追踪 ------补码的表示范围**(2010、2013、2014、2022)**】
补码表示法中的加减运算统一采用加法操作实现。
正数的补码和原码相同,负数的补码等于模(n+1位补码的模为2ⁿ⁺¹)与该负数绝对值之差。
补码的定义如下:
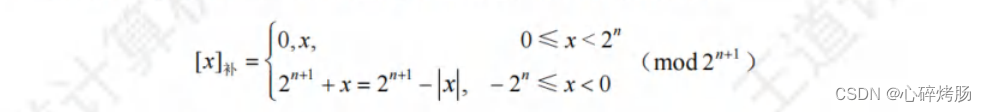
综合上述定义可知,无论是正数还是负数,x补 = 2ⁿ⁺¹+x(-2ⁿ≤x<2ⁿ,mod 2ⁿ⁺¹)。
例如,若 x1 = +1010,x = -1101,字长为8位,则其补码表示为 x1补 = 0 ,0001010,x2补 = 2⁸ - 0,0001101= 1,1110011。
若字长为 n+1,则补码整数的表示范围为-2ⁿ≤x≤2ⁿ-1(比原码多表示"-2ⁿ")。
几个特殊数据的补码表示:
-
- +0补 = -0补 = 0,00...0 (含符号位共 n+1 个0),说明 0 的补码表示是唯一的。
-
- -1补 = 2ⁿ⁺¹-1 = 1,11...1(含符号位共n+1个1)。
-
- 2ⁿ-1补 = 0,11..1(n个1),即n+1位补码能表示的最大整数。
-
- -2ⁿ补 = 1,00...0(n个0),即n+1位补码能表示的最小整数。
【命题追踪 ------补码和真值的相互转换**(2020、2023)**】
在日常生活中,通常用正号、负号来分别表示正数(正号可省略)和负数,如+15、-8等。
这种带"+"或"-"符号的数称为真值。
**真值转换为补码:**对于正数,与原码的方式一样。
对于负数,符号位取1,其余各位由真值 "各位取反,末位加1" 得到。
补码转换为真值:若符号位为0,与原码的方式一样。
若符号位为1,真值的符号为负,数值部分各位由补码 "各位取反,末位加1" 得到。
【命题追踪 ------补码大小的判断**(2015)**】
- ① 原码、补码、反码的符号位相同,正数的机器码相同。
- ② 原码、反码的表示在数轴上对称,二者都存在 +0 和 -0 两个 0。
- ③ 补码、移码的表示在数轴上不对称,零的表示唯一,它们比原码、反码多表示一个数。
- ④ 整数的补码、移码的符号位相反,数值位相同。
- ⑤ 负数的补码、反码末位相差1。
- ⑥ 原码很容易判断大小。而负数的补码、反码很难直接判断大小,可采用如下规则快速判断:对于负数,数值位部分越小,其绝对值越大,即负得越多。
2.1.3整数的表示
【命题追踪 ------机器码与补码、无符号数之间的转换(2021)】
当一个编码的全部二进制位均为数值位而没有符号位时,该编码表示就是无符号整数,简称无符号数。此时,默认数的符号为正。
因为无符号整数省略了一位符号位,所以在字长相同的情况下,它能表示的最大数比有符号整数能表示的大。
一般在全部是正数运算且不出现负值结果的场合下,使用无符号整数表示。例如,可用无符号整数进行地址运算,或用它来表示指针。
例如,对于8位无符号整数,最小数为0000 0000(值为0),最大数为1111 1111(值为2⁸-1=255),即表示范围为0~255;
而对于8位有符号整数,最小数为1000 0000(值为-2⁷= -128),最大数为 0111 1111(值为2⁷-1=127),即表示范围为-128~127。
2.1.4 C语言中的整数类型及类型转换
【命题追踪 ------int 型数据的表示范围**(2017、2019)**】
C语言中的整型数据就是定点整数,根据位数的不同,可分为字符型(char,8位)、短整型(short 或 shont int, 16 位)、整型(int,32 位)、
长整型(long 或 long int,在 32 位机器中为 32位,在 64 位机器中为 64 位)。
char 是整型数据中比较特殊的一种,其他如 short/int/long 等不指定signed/unsigned 时都默认是有符号整数,但 char 默认是无符号整数。
无符号整数(unsigned short/intlong)的全部二进制位均为数值位,没有符号位,相当于数的绝对值。
signed/unsigned 整型数据都是按补码形式存储的,只是 signed 型的最高位代表符号位,而在unsigned 型中表示数值位,因此这两者所表示的数据范围也有所不同。
【命题追踪------有符号数与无符号数的相互转换(2011、2016、2019)】
C语言允许在不同的数据类型之间做类型转换。
强制类型转换格式为"TYPE b=(TYPE) a",强制类型转换后,返回一个具有 TYPE 类型的数值,这种操作并不会改变操作数本身。
先看由 short 型转换到 unsigned short 型的情况。考虑如下代码片段:
cpp
int main(){
short x= -4321;
unsigned short y=(unsigned short) x;
printf("x=%d,y=%u\n",x,y);
}有符号数 x 是一个负数,而无符号数 y 的表示范围显然不包括 x 的值。
在采用补码的机器上,上述程序会输出如下结果:
cpp
x = -4321,y = 61215输出的结果中,得到的 y 值似乎与原来的 x 没有一点关系。不过将这两个数转换为二进制表示时,我们就会发现其中的规律,如表 2.1所示。
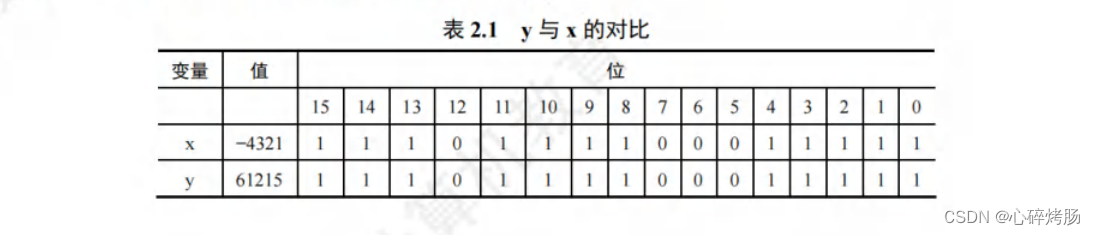
观察可知,将 short 型强制转换为 unsigned short 型只改变数值,而两个变量对应的每位都是一样的。
通过本例可知,强制类型转换的结果是保持位值不变,仅改变了解释这些位的方式。
再看由 unsigned short 型转换到 short 型的情况。考虑如下代码片段:
cpp
int main(){
unsigned short x=65535;
short y= (short)x;
printf("x=%u,y=%d\n",x,y);
}同样在采用补码的机器上,上述程序会输出如下结果:
cpp
x = 65535,y = -1把这两个数转换为二进制表示,同样可以证实之前的结论。
因此,有符号数转换为等长的无符号数时,符号位解释为数值的一部分,负数转换为无符号数时数值将发生变化。
同理,无符号数转换为有符号数时最高位解释为符号位,也可能发生数值的变化。
**注意:**若同时有无符号数和有符号数参与运算,则C语言标准规定按无符号数进行运算
【命题追踪------无符号数的零扩展(2012)】
另一种常见的运算是在不同字长的整数之间进行类型转换。
先看大字长变量向小字长变量转换的情况。考虑如下代码片段:
cpp
int main(){
int x=165537,u=-34991; //int型占用4B
short y=(short)x,v=(short)u; //short型占用2B
printf("x=%d,y=%d\n", x, y);
printf("u=%d,v=%d\n", u, v);
}运行结果如下:
cpp
x = 165537, y = -31071
u = -34991, v = 30545其中 x,y,u,v的十六进制表示分别为 0x000286a1,0x86a1,0xffff07751,0x7751,观察上述数字很容易得出结论,当大字长变量向小字长变量强制类型转换时,系统把多余的高位部分直接截断,低位部分直接赋值,因此也是一种保持位值的处理方法。
再看小字长变量向大字长变量转换的情况。考虑如下代码片段:
cpp
int main(){
short x=-4321;
int y=x;
unsigned short u=(unsigned short)x;
unsigned int v=u;
printf("x=%d,y=%d\n", x, y);
printf("u=%u,v=%u\n", u, v);
}运行结果如下:
cpp
x = -4321, y = -4321
u = 61215, v = 61215【命题追踪 ------无符号数的零扩展**(2012)** ,补码的符号扩展**(2021)**】
x,y,u,v的十六进制表示分别为 0xef1f,0xffffef1f,0xef1f,0x0000ef1f。
由本例可知,小字长到大字长的转换时,不仅要使相应的位值相等,还要对高位部分进行扩展。
若原数字是无符号整数,则进行零扩展,扩展后的高位部分用0填充。否则进行符号扩展,扩展后的高位部分用原数字符号位填充。
其实两种方式扩展的高位部分都可理解为原数字的符号位。
这与之前的三个例子都不一样,从位值与数值的角度看,前三个例子的转换规则都是保证相应的位值相等,而小字长向大字长的转换,在位值相等的条件下还要补充高位的符号位,可以理解为数值的相等。
注意,char 型为 8 位无符号整数,其在转换为 int 型时高位补0即可。