先来看一段关于python语言的爬虫代码
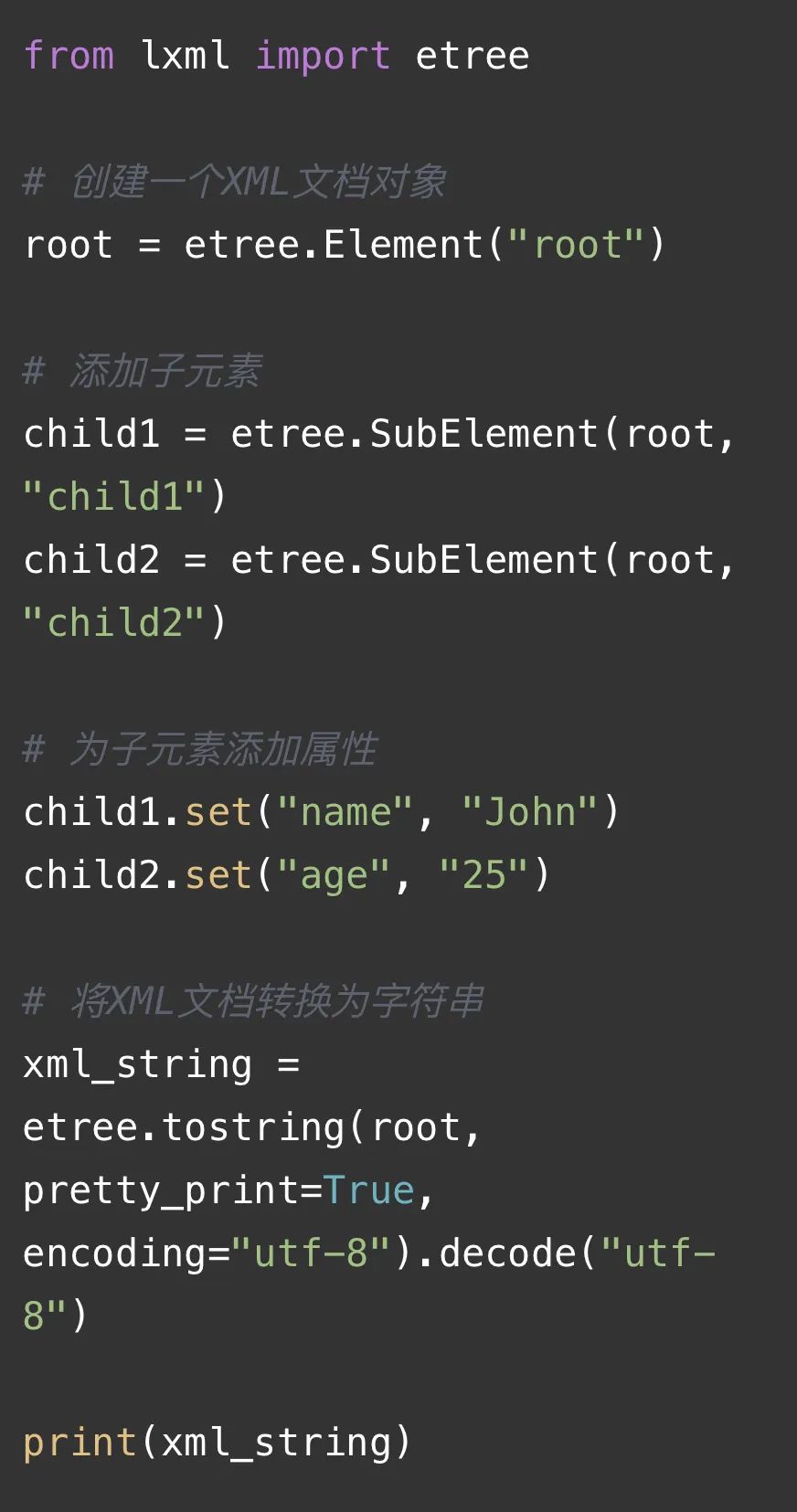
`
``
如下⬇️解释当前图片代码:
这段代码使用了lxml库来创建一个简单的XML文档。首先,我们导入了`etree`模块。然后,我们创建了一个根元素`root`,并使用`etree.SubElement()`函数向其添加了两个子元素`child1`和`child2`。接下来,我们为这两个子元素分别设置了属性`name`和`age`。最后,我们使用`etree.tostring()`函数将整个XML文档转换为字符串,并通过`pretty_print=True`参数设置输出格式为美化后的可读形式。最终,我们将生成的XML字符串打印出来。
Python中的lxml库
它是一个强大的XML和HTML处理库,它基于libxml2和libxslt库,提供了高效的XML解析和处理功能。在爬虫方向的应用中,lxml库的作用主要体现在其能够高效地解析网页内容并提取出结构化数据。以下是对lxml库在爬虫方向应用的详细说明:
- 快速解析
-
C语言实现:lxml库基于C语言编写,解析速度快,效率高。
-
内存占用小:相比其他解析库,lxml在解析大型文档时内存占用更小。
- 支持XPath
-
元素定位:lxml支持使用XPath语法进行元素定位和选择,便于快速定位到特定元素。
-
属性获取:可以通过XPath方便地获取元素的属性值,如链接(href)或数据节点信息。
- HTML解析器
-
内置解析功能:lxml内置了HTML解析器,可以方便地解析HTML文档。
-
自动补全标签:在解析过程中,lxml会自动补全缺失的HTML标签,确保文档结构的完整性。
- XSLT转换
-
样式转换:lxml支持XSLT转换,可以将XML文档转换为其他格式,如HTML。
-
数据呈现:通过XSLT转换,可以将爬取的数据以更友好的形式呈现出来。
- DTD和XML Schema验证
-
数据验证:lxml支持DTD和XML Schema验证,确保爬取的数据符合预定义的结构。
-
数据清洗:可以在解析过程中对数据进行清洗,去除不需要的信息。
- 错误处理
-
容错机制:lxml在解析不规则的HTML文档时具备良好的容错机制,能够处理不规范的标签和属性。
-
异常捕获:在爬取过程中可以捕获和处理异常,保证爬虫程序的稳定运行。
- 编码支持
-
多编码处理:lxml支持多种字符编码的解析,包括UTF-8、ASCII等,适应不同网页的编码需求。
-
字符转换:可以处理特殊字符的转换,避免因为编码问题导致的数据提取错误。
- 模块化设计
-
功能模块化:lxml库的功能模块划分清晰,用户可以根据需要选择使用相应的模块。
-
扩展性强:可以根据实际需求对lxml进行扩展,增加特定的解析和处理功能。
此外,为了更好地应用lxml库于爬虫项目,以下是一些额外的考虑因素:
-
在爬取数据前,应先了解目标网站的结构,以便更准确地使用XPath等工具进行数据定位。
-
在使用lxml进行大规模数据抓取时,需要注意遵守爬虫道德和相关法律法规,避免对网站服务器造成过大压力。
-
考虑到数据的后续使用,应在爬取过程中对数据进行适当的预处理,如去除空格、转换字符串格式等。
综上所述,lxml库在爬虫方向的应用主要体现在其快速解析能力、XPath支持、HTML解析功能以及对XSLT转换的支持等方面。这些特性使得lxml成为Python爬虫项目中不可或缺的工具之一,能够帮助开发者高效地从网页中提取出所需的数据。在实际的爬虫开发中,合理利用lxml库的功能,可以大大提升爬虫的效率和准确性。