单机多卡并行
更多的芯片
https://courses.d2l.ai/zh-v2/assets/pdfs/part-2_2.pdf
多GPU训练
https://courses.d2l.ai/zh-v2/assets/pdfs/part-2_3.pdf

当transformer模型很大,有100GB的时候只能用模型并行。

数据并行,拿的参数是完整的?
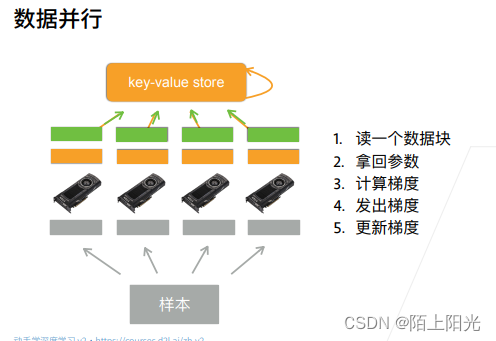

QA
1 当有一块卡显存更大的时候,可以把数据批量设大一些,单独给大显存的卡数据多一些。
2 梯度累加起来。
3 存储模型,梯度。中间数据量的大小取决于数据批量大小。批量变小,矩阵运算变小,性能会低。
4 模型并行可以做到一定程度的并行,并行程度会低
5 独立显卡会比集成显卡快很多。
6 无人车关心功耗,希望拿到server端的效果但是功耗要低。