一、JVM中数据内存区域划分


本地方法栈:里面保存的是native 关键字的方法,不是用Java写的,而是jvm内部用c++实现的。
**程序计数器 和 虚拟机栈 每个线程都存在一份。
如果一个 JVM 进程 中有 10个 线程,那么就会存在 10份 程序计数器 和 虚拟机栈。
**堆区 和 元数据区 是整个进程独一份的!!!
所以有这样的说法 : 在jvm里,每个线程都有自己私有的栈空间



例如:


二、 类加载
1.类加载的基本流程

1)加载:找到.class文件,打开文件,读取文件内容

2)验证:类文件结构
在Java SE 官方标准文档中,记录了 ClassFile 文件结构的细节
Chapter 4. The class File Format


3)准备:给类对象分配内存空间(最终目的 构造类对象)

4)解析:针对类对象中的字符串常量进行处理
字符串常量 在被创建的时候,初始化语句先被设置成一个 "文件的偏移量",通过这个偏移量,就能找到这个字符串常量 的 位置了。
当这个类真正被加载到内存中的时候,再把这个偏移量,替换回真正的地址
5)初始化:针对类对象进行初始化

2.双亲委派模型

类加载过程中,找 .class文件的过程


双亲委派模型,可以看成一个简单的 查找优先级 的问题
优先级 :bootstrap classloader > extension classloader > application classloader

双亲委派模型 并不是不能打破的。

三、GC垃圾回收
在c++中,delete 存在执行不到的情况,就可能存在内存泄漏



GC垃圾回收的步骤
1.找到垃圾
垃圾:不在使用的对象
GC圈中主流的两个方案:
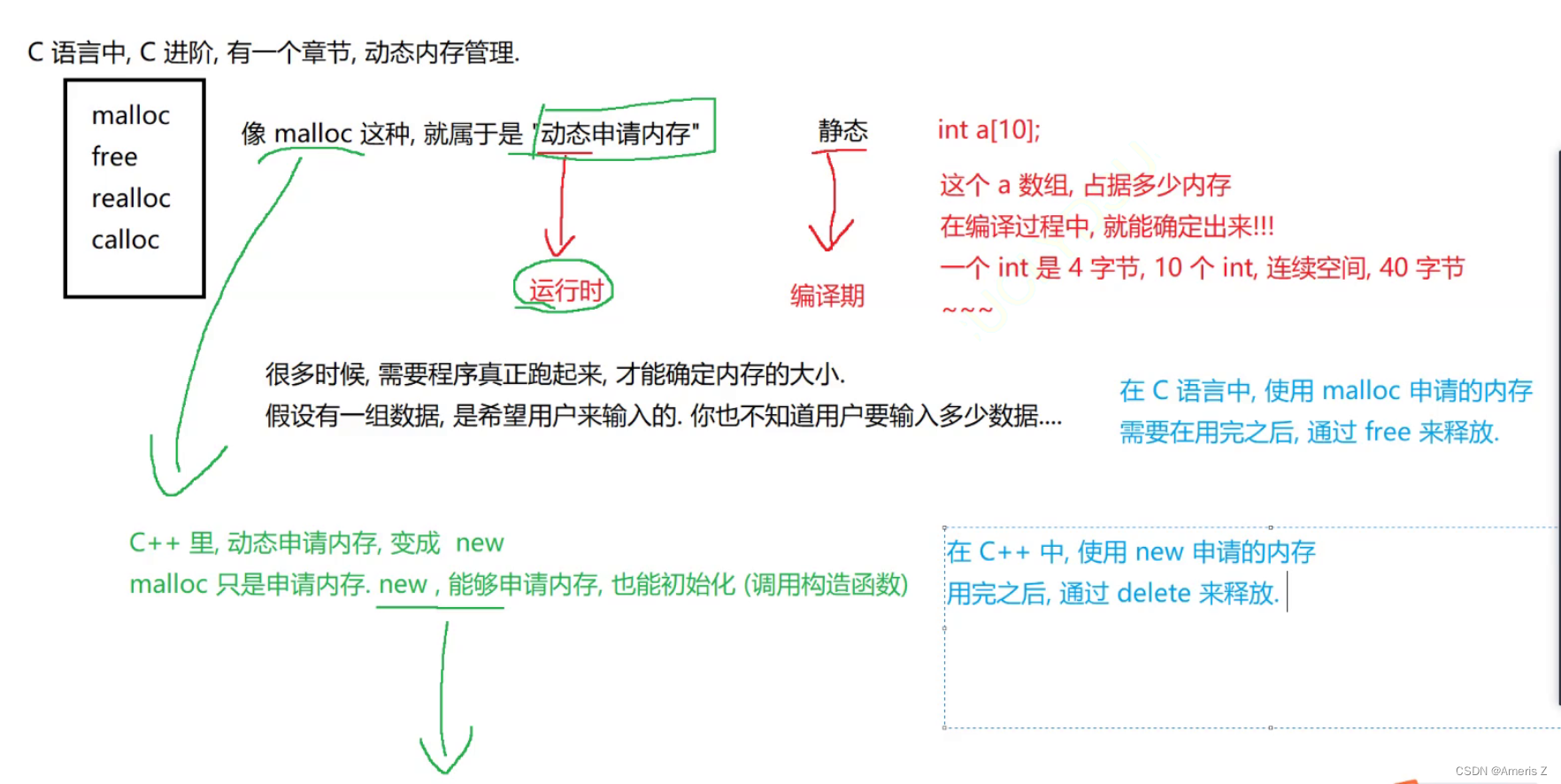
1)引用计数【python 、php】
当引用计数为 0 ,此时代码中就不能访问到这个对象了
此时这个对象就可以视为垃圾了
***为什么Java不用这个方案??
**1浪费内存
每个对象单独开一块空间,保存对应的对象的引用个数。
一个计数器,少说2个字节
如果对象为 2个字节,计数器占 2/2+2(50%)的空间;
如果对象为 4个字节,计数器占2/2+4 (33%)的空间;
当 对象数量很少 或者 对象空间比较大 的时候,影响不大
当 对象空间小(例如对象本身2个字节,计数器2个字节,就浪费了50%),数量还多(n个50%的空间浪费),计数器所占空间就难以忽略
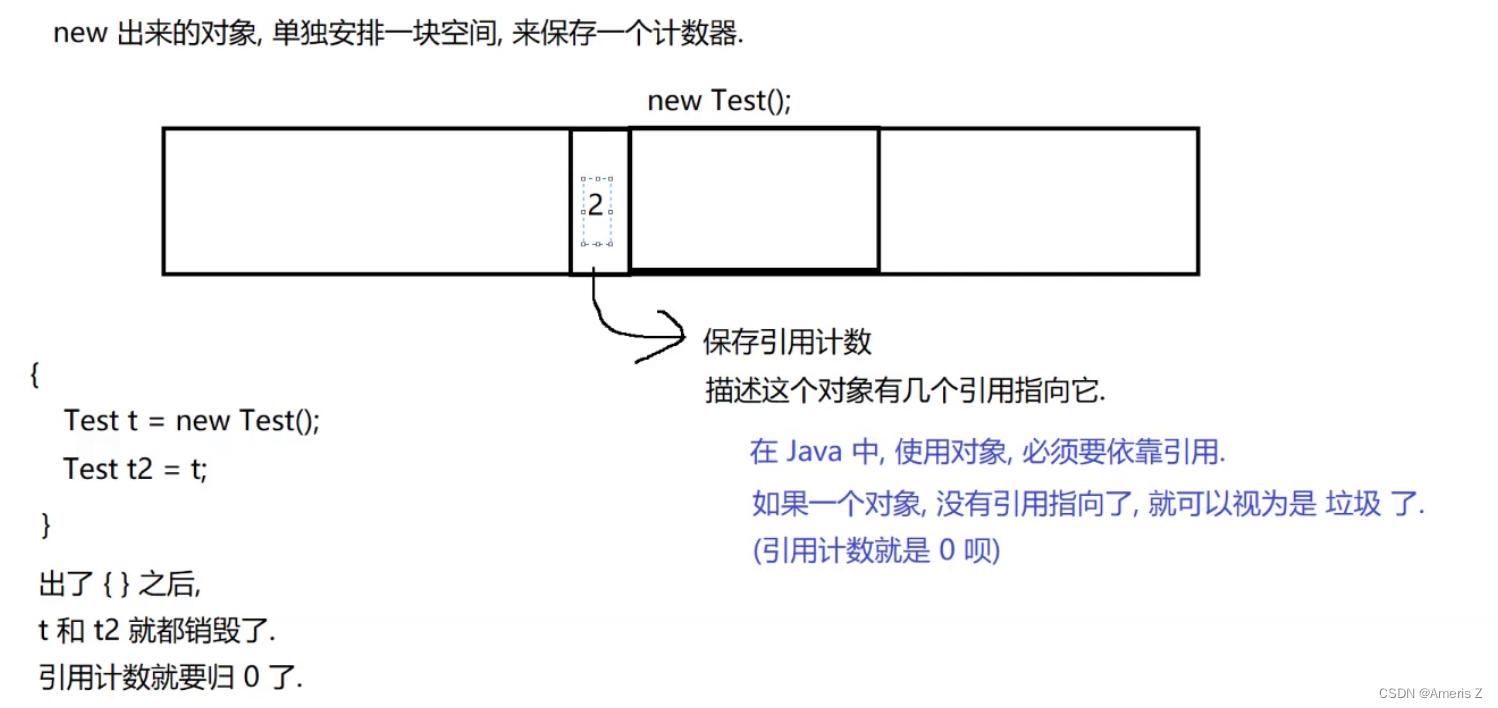
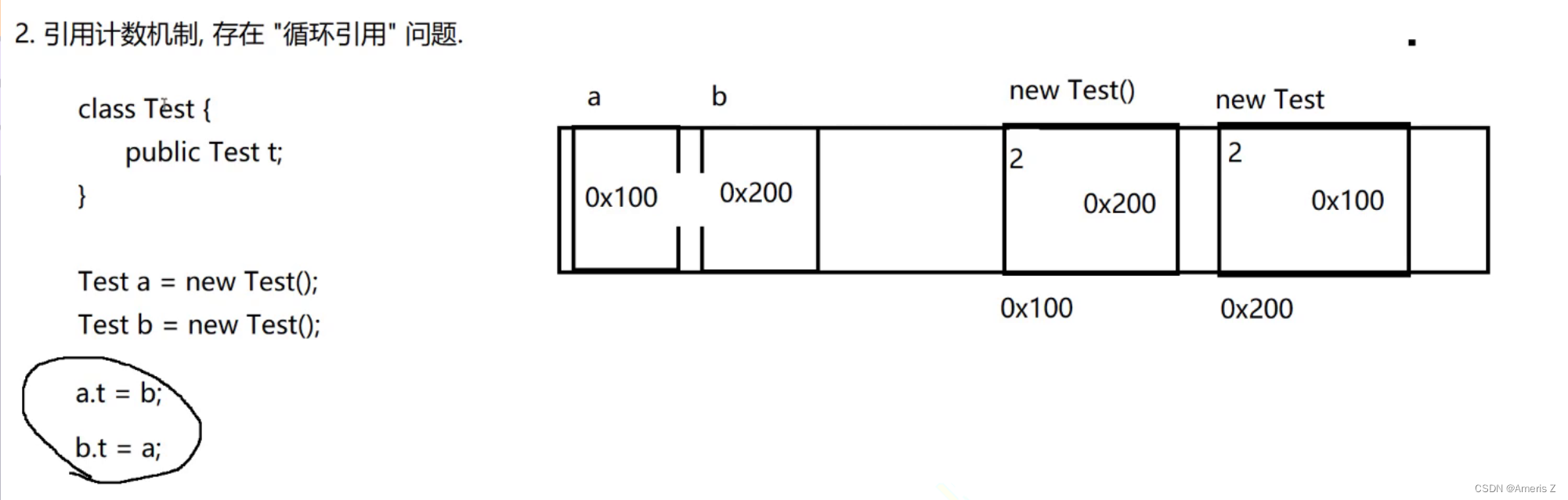
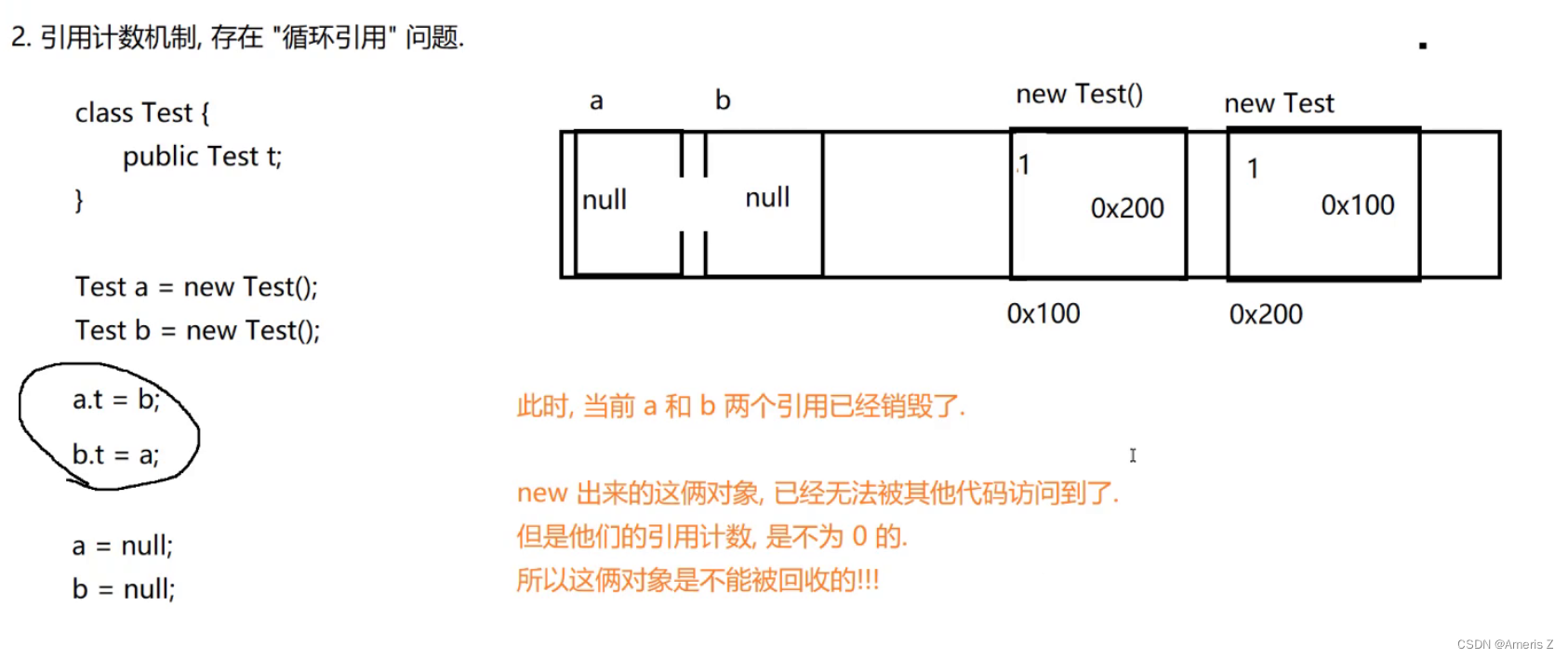
**2存在 " 引用循环 " 的问题
此时,第一个对象 引用了 第二个对象。
第二个对象 引用了 第一个对象。
要想使用第一个对象,就要拿到第二个对象。
要想拿到第二个对象,就要先拿到第一个对象。这样就有了一个逻辑上的死循环。
类似于 家钥匙锁车里了,车钥匙锁家里了
2)可达性分析**【Java】**
可达性分析,本质上是 时间换空间 的手段。
用一个或多个线程,周期性的扫描我们代码中的对象。
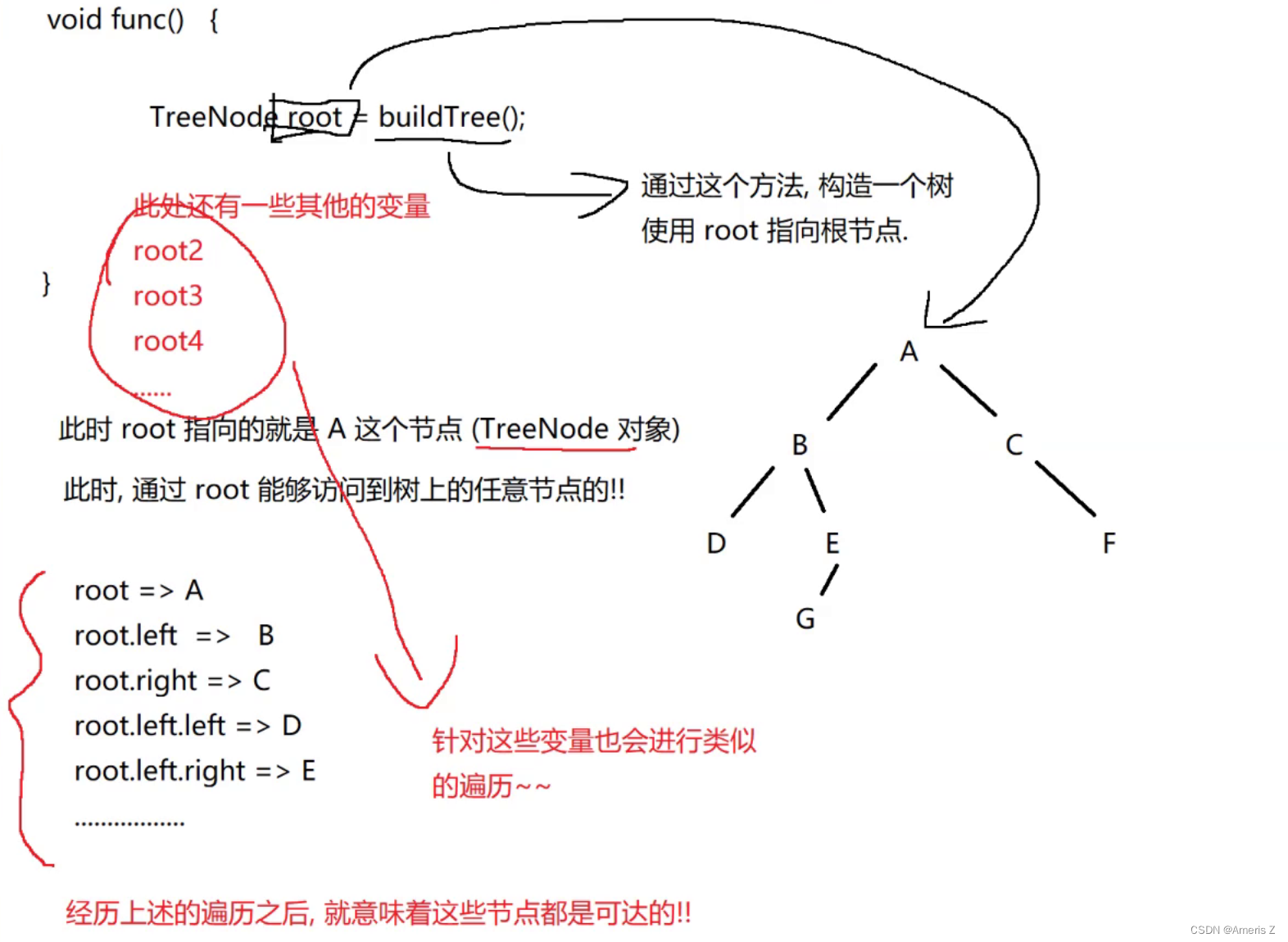
从一些特定的对象出发,尽可能的进行访问遍历。把所有能访问到的对象,都标记成可达。反之,经过扫描后,未被标记的对象,就是"垃圾"了。
例如:
***可达情况:
***不可达情况:
***可达性分析是周期性的,可能某个对象上一秒还不是垃圾,下一秒就是垃圾了



2.释放垃圾
三种回收垃圾的基本思路
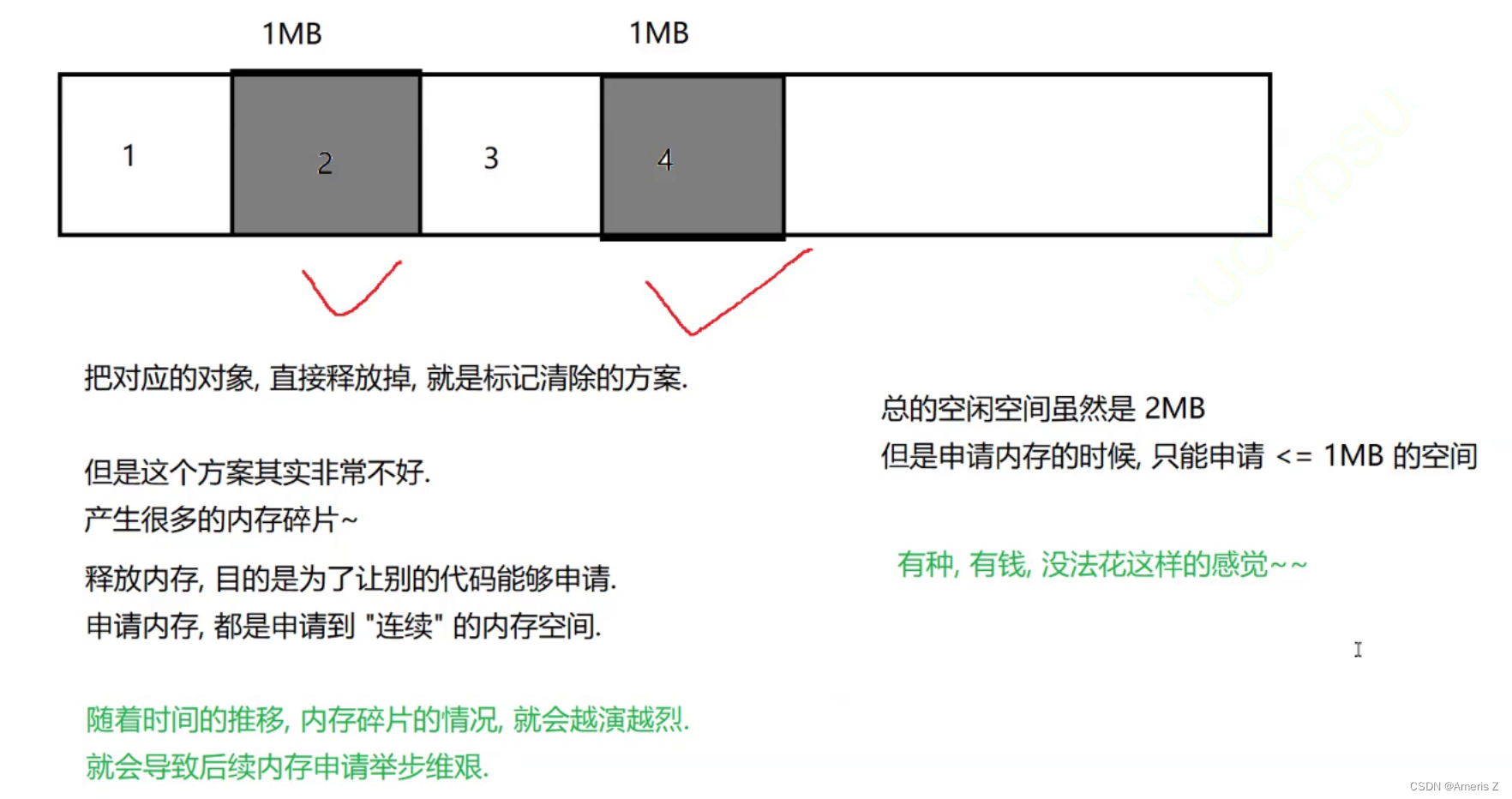
1)标记清除(简单粗暴)
缺陷:产生大量内存碎片
假设这里有四个对象,2和4被标记为垃圾,要清除。
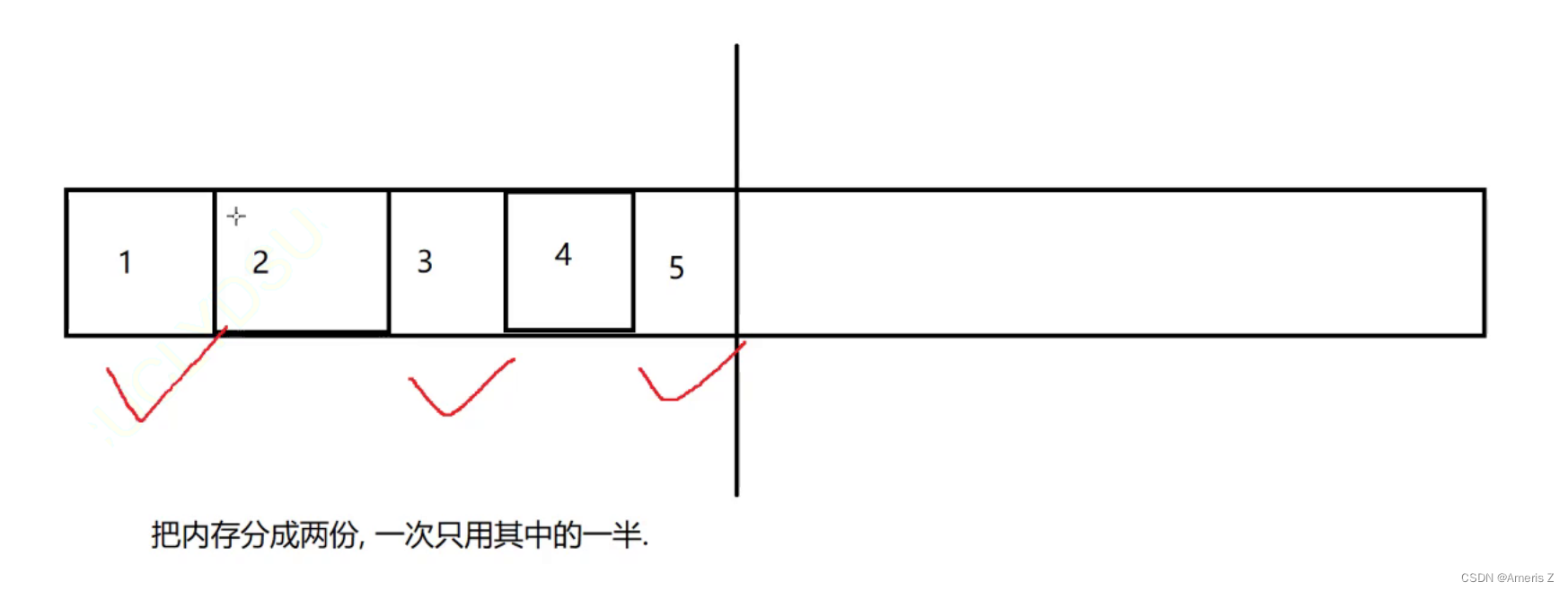
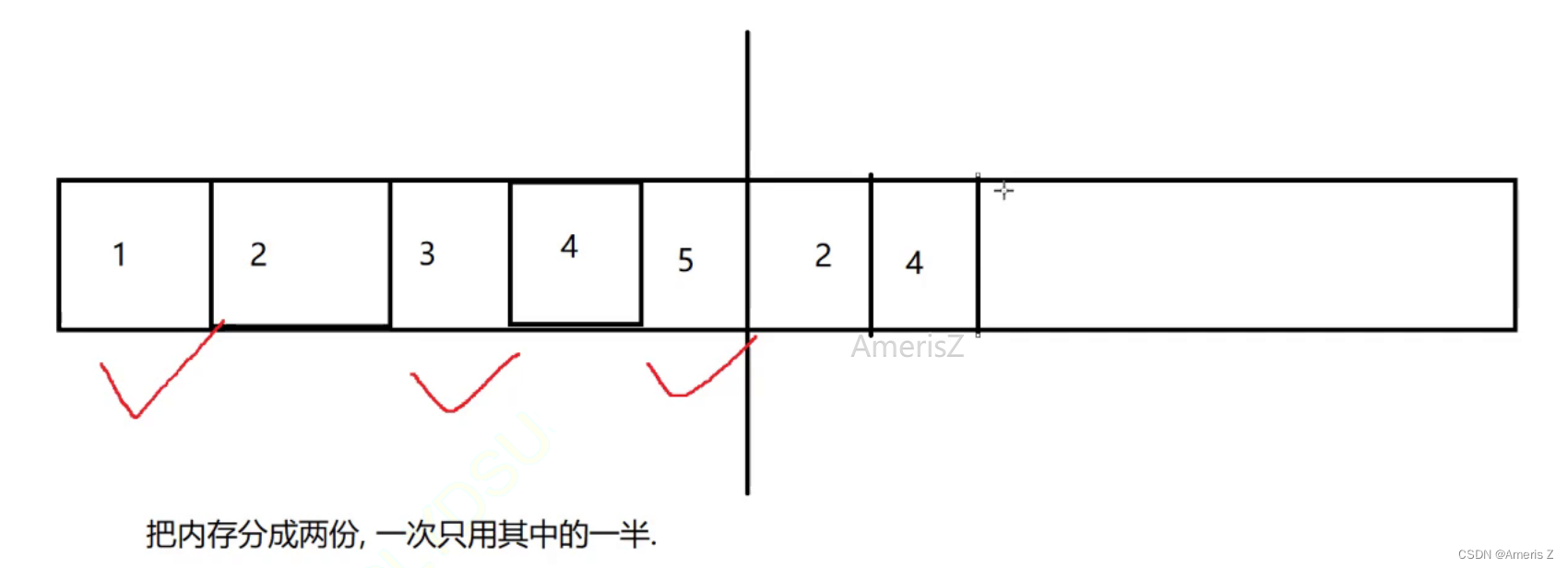
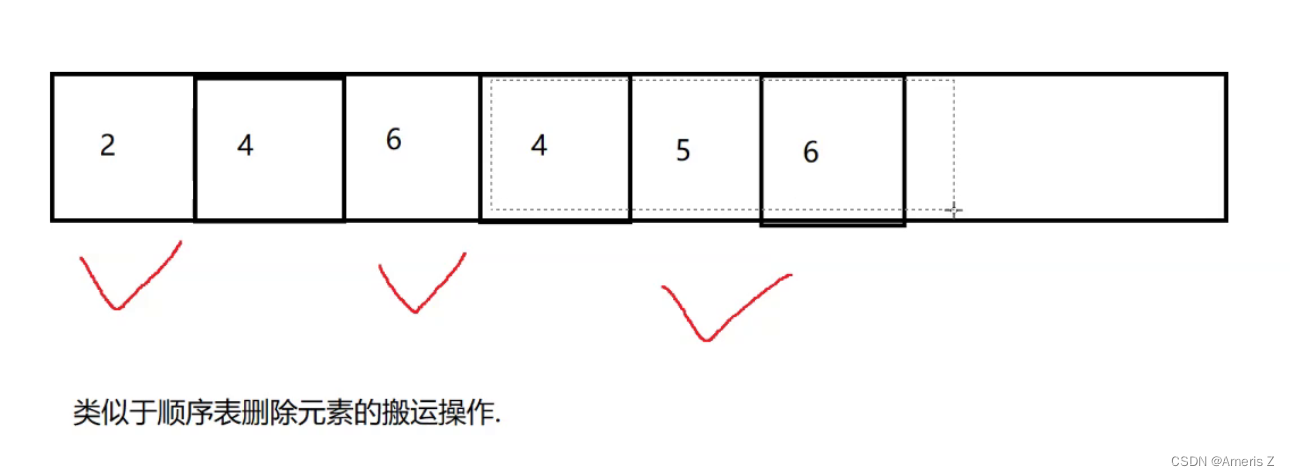
2)复制算法
通过复制的方法,把有效的对象复制到一起。再统一释放剩余空间
优势:避免了内存碎片
缺点:
1.内存要浪费一半,利用率不高
2.如果有效对象特别多,拷贝开销就很会很大
假设这里有五个对象,其中1 3 5是垃圾,有效数据是 2 4.
把有效数据,复制到一边
再把原来的数据全部释放

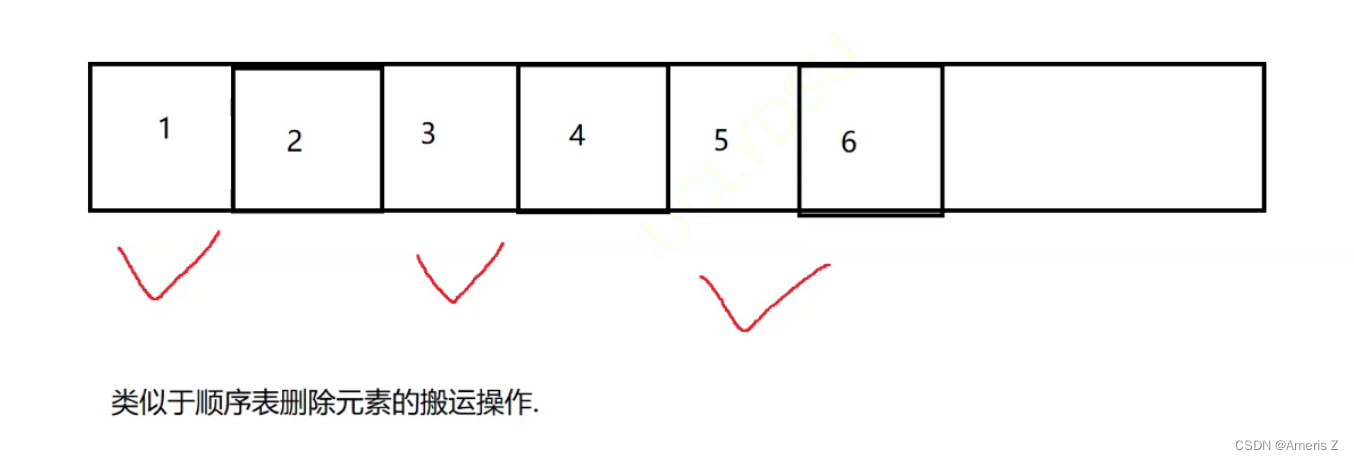
3)标记整理
优势:既能解决 内存碎片问题,又能 处理复制算法中的利用率
缺点:搬运的开销仍然很大
假设 1 3 5 是 垃圾,2 4 6 为有效对象
把有效的对象搬运到前面
再把剩余的删除

3.JVM 中的释放垃圾
实际上,JVM中的 释放垃圾思路,是上述三种方案的结合体
通过新生代 和 老年代 相结合的方式,分代回收这样的思想,来释放垃圾。实际上JVM垃圾回收器具体实现的时候,会有一些优化和调整。
新生代 主要使用 复制算法
老年代 主要使用 标记整理算法
(标记算法并没有真正使用到)


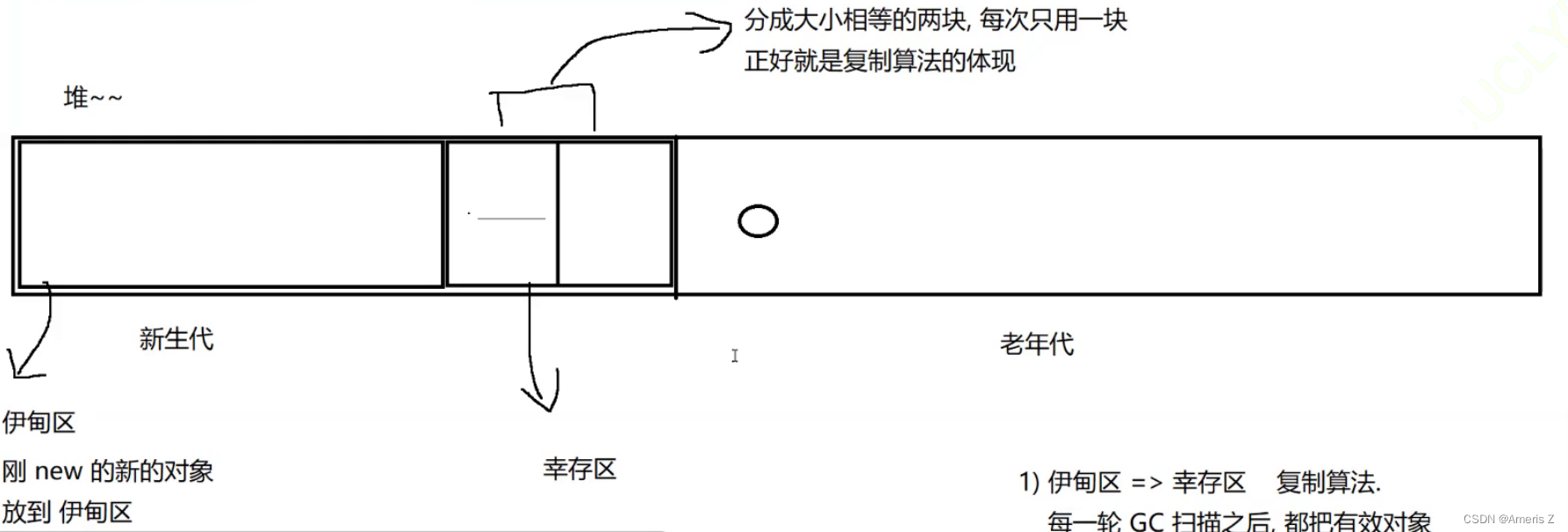
能活过的GC扫描次数越多的对象,会放在 老年代

