相比MapReduce僵化的Map与Reduce分阶段计算,Spark计算框架更有弹性和灵活性,运行性能更佳。
1 Spark的计算阶段
- MapReduce一个应用一次只运行一个map和一个reduce
- Spark可根据应用复杂度,分割成更多的计算阶段(stage),组成一个DAG,Spark任务调度器可根据DAG依赖关系执行计算阶段
逻辑回归机器学习性能Spark比MapReduce快100多倍。因某些机器学习算法可能需大量迭代计算,产生数万个计算阶段,这些计算阶段在一个应用中处理完成,而不像MapReduce需要启动数万个应用,因此运行效率极高。
DAG,不同阶段的依赖关系有向,计算过程只能沿依赖关系方向执行,被依赖的阶段执行完成前,依赖的阶段不能开始执行。该依赖关系不能有环形依赖,否则就死循环。
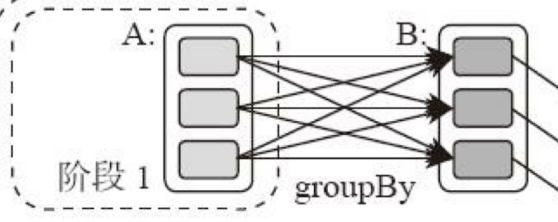
典型的Spark运行DAG的不同阶段:
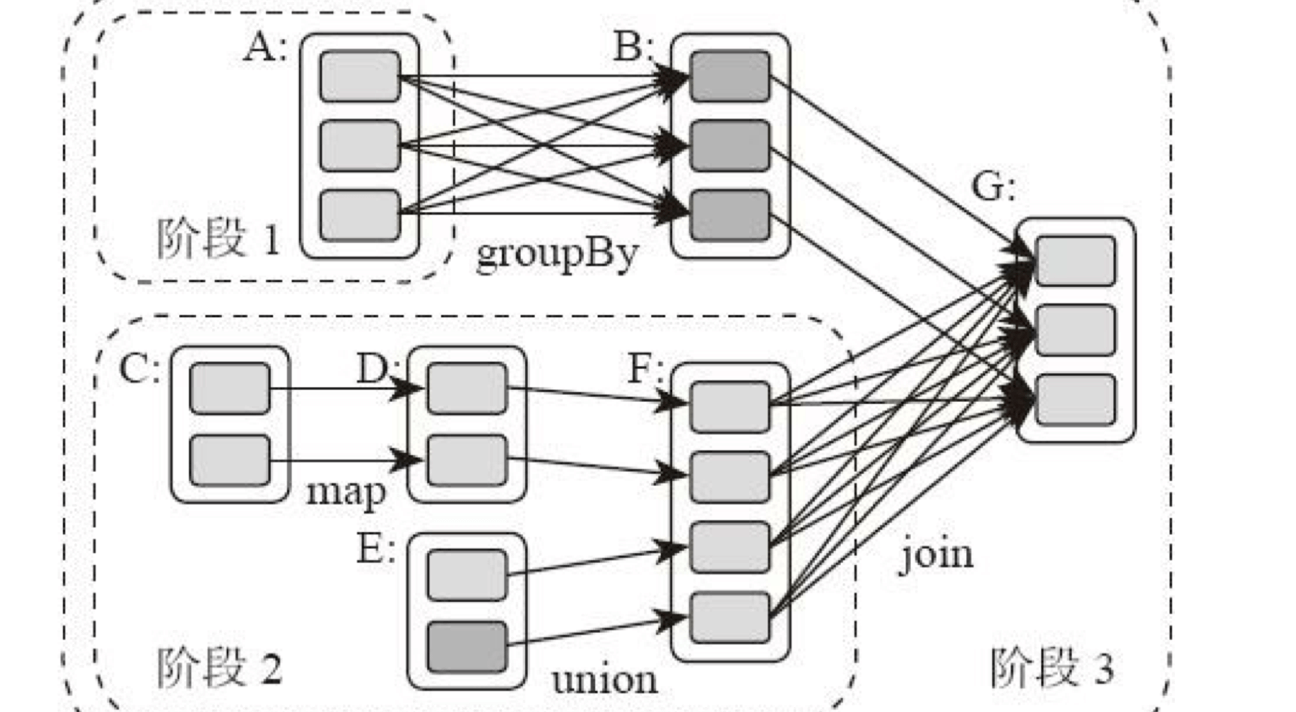
整个应用被切分成3个阶段,阶段3依赖阶段1、2,阶段1、2互不依赖。Spark执行调度时,先执行阶段1、2,完成后,再执行阶段3。对应Spark伪代码:
scala
rddB = rddA.groupBy(key)
rddD = rddC.map(func)
rddF = rddD.union(rddE)
rddG = rddB.join(rddF)所以Spark作业调度执行核心是DAG,整个应用被切分成数个阶段,每个阶段的依赖关系也很清楚。根据每个阶段要处理的数据量生成任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现大数据分布式计算。
负责Spark应用DAG生成和管理的组件是DAGScheduler:
- DAGScheduler根据程序代码生成DAG
- 然后将程序分发到分布式计算集群
- 按计算阶段的先后关系调度执行
Spark划分计算阶段的依据
显然并非RDD上的每个转换函数都会生成一个计算阶段,如上4个转换函数,但只有3个阶段。
观察上面DAG图,计算阶段的划分就看出,当RDD之间的转换连接线呈现多对多交叉连接,就产生新阶段。一个RDD代表一个数据集,图中每个RDD里面都包含多个小块,每个小块代表RDD的一个分片。
一个数据集中的多个数据分片需进行分区传输,写到另一个数据集的不同分片,这种数据分区交叉传输操作,在MapReduce运行过程也看过。
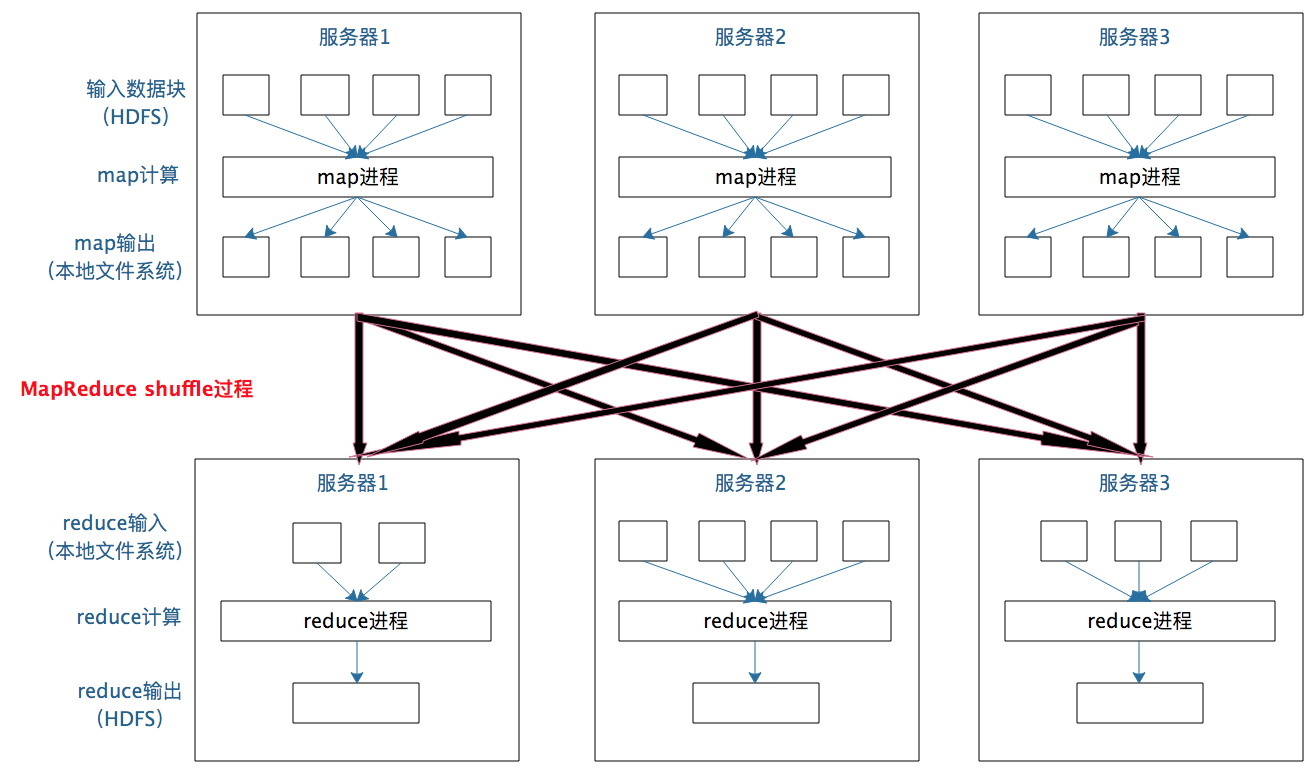
这就是shuffle过程,Spark也要通过shuffle将数据重组,相同Key的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。
计算阶段划分依据是shuffle,而非转换函数的类型,有的函数有时有shuffle,有时无。如上图例子中RDD B和RDD F进行join,得到RDD G,这里的RDD F需要进行shuffle,RDD B不需要。
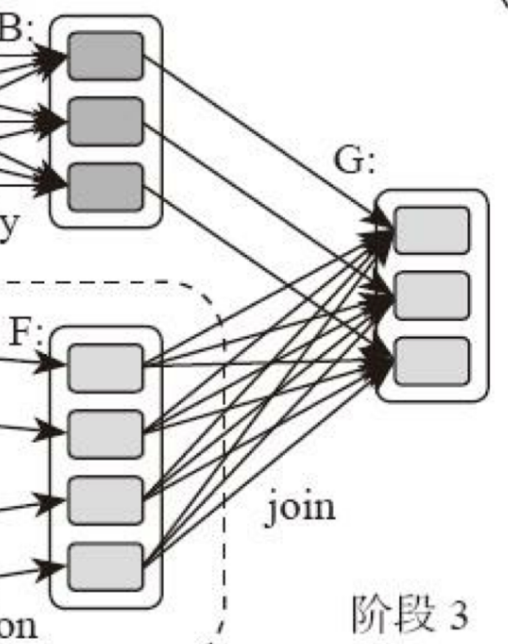
因为RDD B在前面一个阶段,阶段1的shuffle过程中,已进行数据分区。分区数目和分区K不变,无需再shuffle:
- 这种无需进行shuffle的依赖,在Spark里称窄依赖
- 需进行shuffle的依赖,称宽依赖
类似MapReduce,shuffle对Spark也重要,只有通过shuffle,相关数据才能互相计算。
既然都要shuffle,为何Spark更高效?
本质Spark算一种MapReduce计算模型的不同实现。Hadoop MapReduce简单粗暴根据shuffle将大数据计算分成Map、Reduce两阶段就完事。但Spark更细,将前一个的Reduce和后一个的Map连接,当作一个阶段持续计算,形成一个更优雅、高效地计算模型,其本质依然是Map、Reduce。但这种多个计算阶段依赖执行的方案可有效减少对HDFS的访问,减少作业的调度执行次数,因此执行速度更快。
不同于Hadoop MapReduce主要使用磁盘存储shuffle过程中的数据,Spark优先使用内存进行数据存储,包括RDD数据。除非内存不够用,否则尽可能使用内存, 这即Spark比Hadoop性能高。
2 Spark作业管理
Spark里面的RDD函数有两种:
- 转换函数,调用后得到的还是RDD,RDD计算逻辑主要通过转换函数
- action函数,调用后不再返回RDD。如count()函数,返回RDD中数据的元素个数
- saveAsTextFile(path),将RDD数据存储到path路径
Spark的DAGScheduler遇到shuffle时,会生成一个计算阶段,在遇到action函数时,会生成一个作业(job)。
RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段含多个计算任务(task)。
作业、计算阶段、任务的依赖和时间先后关系:
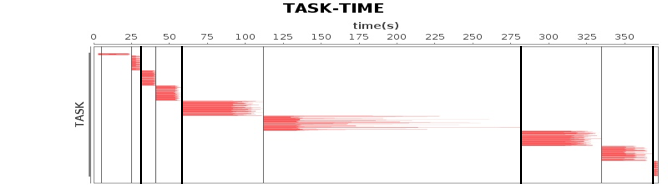
横轴时间,纵轴任务。两条粗黑线之间是一个作业,两条细线之间是一个计算阶段。一个作业至少包含一个计算阶段。水平方向红色的线是任务,每个阶段由很多个任务组成,这些任务组成一个任务集合。
DAGScheduler根据代码生成DAG图后,Spark任务调度就以任务为单位进行分配,将任务分配到分布式集群的不同机器上执行。
3 Spark执行流程
Spark支持Standalone、Yarn、Mesos、K8s等多种部署方案,原理类似,仅不同组件的角色命名不同。
3.1 Spark cluster components
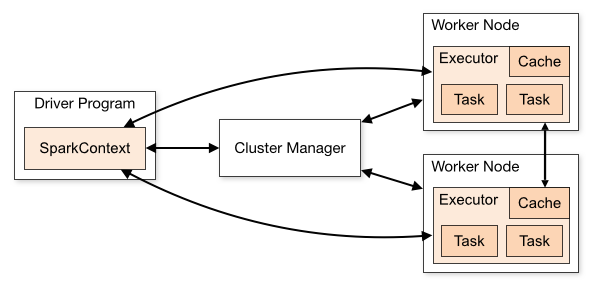
Spark应用程序启动在自己的JVM进程里(Driver进程),启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造执行的DAG图,切分成最小的执行单位-计算任务。
然后,Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
Worker收到信息后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的Worker分配任务。
Worker收到任务后,启动Executor进程执行任务。Executor先检查自己是否有Driver的执行代码,若无,从Driver下载执行代码,通过Java反射加载后开始执行。
4 Spark V.S Hadoop
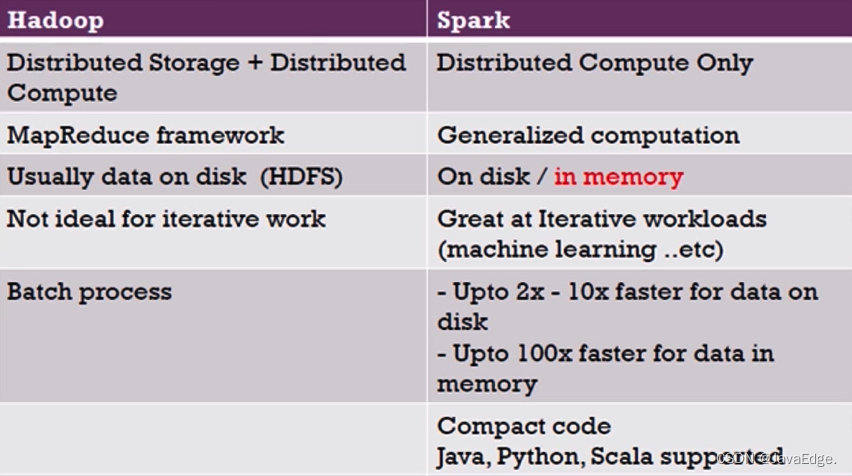
4.1 个体对比
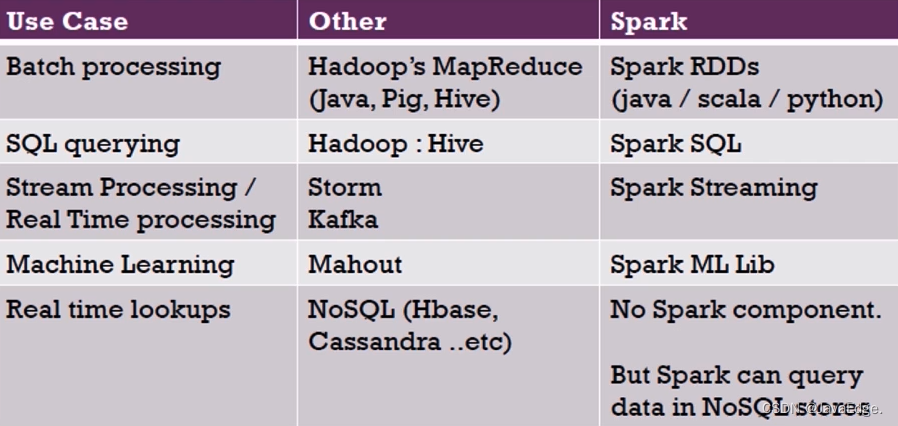
4.2 生态圈对比
4.3 MapReduce V.S Spark

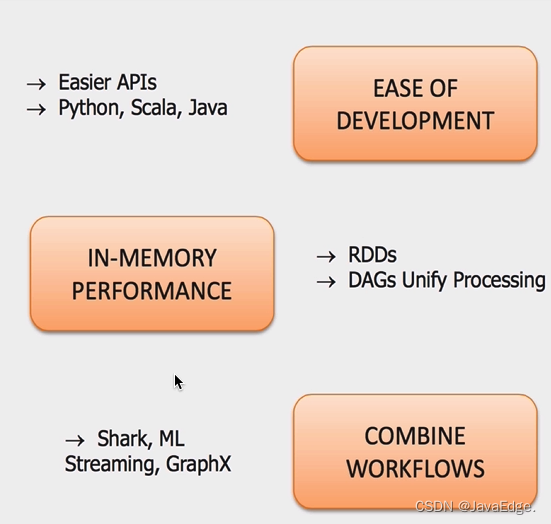
4.4 优势
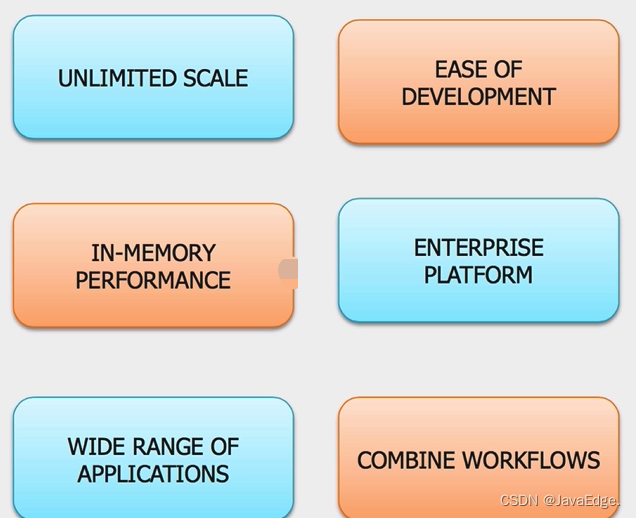
4.5 Spark 和 Hadoop 协作
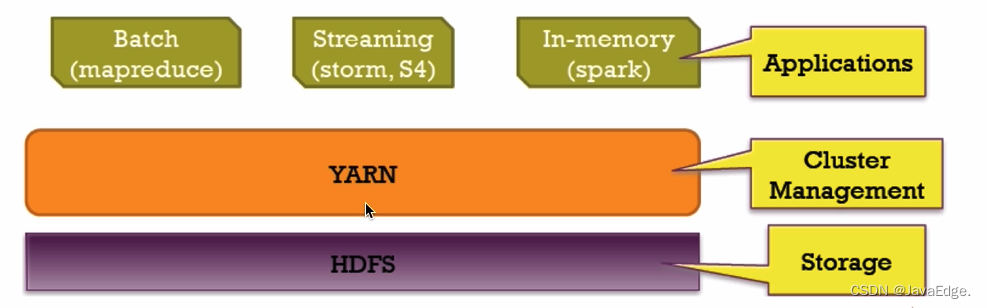
5 总结
相比Mapreduce,Spark的主要特性:
- RDD编程模型更简单
- DAG切分的多阶段计算过程更快
- 使用内存存储中间计算结果更高效
Spark在2012开始流行,那时内存容量提升和成本降低已经比MapReduce出现的十年前强了一个数量级,Spark优先使用内存的条件已成熟。
本文描述的内存模型自 Apache Spark 1.6+ 开始弃用,新的内存模型基于 UnifiedMemoryManager,并在这篇文章中描述。
在最近的时间里,我在 StackOverflow 上回答了一系列与 ApacheSpark 架构有关的问题。所有这些问题似乎都是因为互联网上缺少一份关于 Spark 架构的好的通用描述造成的。即使是官方指南也没有太多细节,当然也缺乏好的图表。《学习 Spark》这本书和官方研讨会的资料也是如此。
在这篇文章中,我将尝试解决这个问题,提供一个关于 Spark 架构的一站式指南,以及对其一些最受欢迎的概念问题的解答。这篇文章并不适合完全的初学者------它不会为你提供关于 Spark 主要编程抽象(RDD 和 DAG)的洞见,但是它要求你有这些知识作为先决条件。
从 http://spark.apache.org/docs/1.3.0/cluster-overview.html 上可用的官方图片开始:
Spark 架构官方:
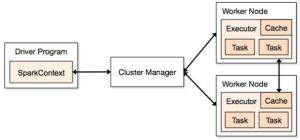
如你所见,它同时引入了许多术语------"executor","task","cache","Worker Node"等等。当我开始学习 Spark 概念的时候,这几乎是互联网上唯一关于 Spark 架构的图片,现在情况也没有太大改变。我个人不是很喜欢这个,因为它没有显示一些重要的概念,或者显示得不是最佳方式。
让我们从头说起。任何,任何在你的集群或本地机器上运行的 Spark 过程都是一个 JVM 过程。与任何 JVM 过程一样,你可以用 -Xmx 和 -Xms JVM 标志来配置它的堆大小。这个过程如何使用它的堆内存,以及它为什么需要它?以下是 JVM 堆内的 Spark 内存分配图表:
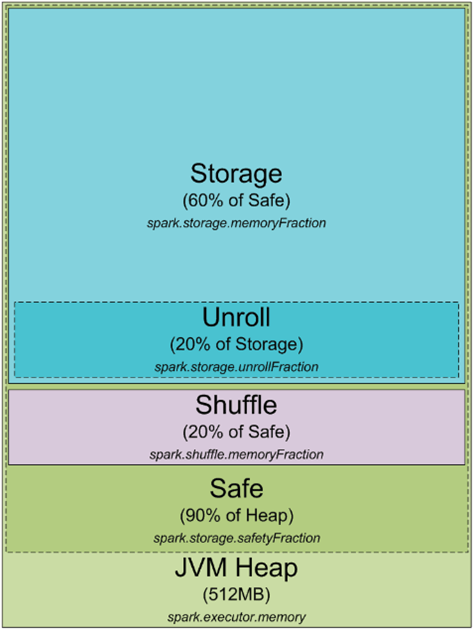
默认情况下,Spark 以 512MB JVM 堆启动。为了安全起见,避免 OOM 错误,Spark 只允许使用堆的 90%,这由参数 spark.storage.safetyFraction 控制。好的,正如你可能已经听说 Spark 是一个内存中的工具,Spark 允许你将一些数据存储在内存中。如果你读过我这里的文章 https://0x0fff.com/spark-misconceptions/,你应该理解 Spark 并不是真的内存工具,它只是利用内存来缓存 LRU(http://en.wikipedia.org/wiki/Cache_algorithms)。所以一些内存是为你处理的数据缓存而保留的部分,这部分通常是安全堆的 60%,由 spark.storage.memoryFraction 参数控制。所以如果你想知道你可以在 Spark 中缓存多少数据,你应该取所有执行器的堆大小之和,乘以 safetyFraction 和 storage.memoryFraction,默认情况下,它是 0.9 * 0.6 = 0.54 或者让 Spark 使用的总的堆大小的 54%。
现在更详细地了解 shuffle 内存。它的计算方法为 "堆大小" * spark.shuffle.safetyFraction * spark.shuffle.memoryFraction 。spark.shuffle.safetyFraction 的默认值是 0.8 或 80%,spark.shuffle.memoryFraction 的默认值是 0.2 或 20%。所以最终你可以使用最多 0.8*0.2 = 0.16 或 JVM 堆的 16% 用于 shuffle。但是 Spark 如何使用这些内存呢?你可以在这里获取更多细节(https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala),但总的来说,Spark 用这些内存进行它的 Shuffle。当 Shuffle 进行时,有时你也需要对数据进行排序。当你排序数据时,你通常需要一个缓冲区来存储排序后的数据(记住,你不能就地修改 LRU 缓存中的数据,因为它是用来稍后重用的)。所以它需要一些 RAM 来存储排序的数据块。如果你没有足够的内存来排序数据会怎样?有一系列通常被称为"外部排序"的算法(http://en.wikipedia.org/wiki/External_sorting)允许你进行分块数据的排序,然后再将最终结果合并起来。
我还没涵盖的 RAM 的最后部分是"unroll"内存。被 unroll 过程使用的 RAM 部分是 spark.storage.unrollFraction * spark.storage.memoryFraction * spark.storage.safetyFraction,默认值等于 0.2 * 0.6 * 0.9 = 0.108 或者堆的 10.8%。这是当你将数据块 unroll 到内存时可以使用的内存。为什么你需要 unroll 它呢?Spark 允许你以序列化和非序列化形式存储数据。序列化形式的数据不能直接使用,因此你需要在使用之前 unroll 它,所以这是用于 unroll 的 RAM。它与存储 RAM 共享,这意味着如果你需要一些内存来 unroll 数据,这可能会导致 Spark LRU 缓存中存储的一些分区被删除。
这很好,因为此刻你知道了什么是 Spark 过程以及它如何利用它的 JVM 过程的内存。现在让我们转到集群模式------当你启动一个 Spark 集群时,它实际上是什么样的呢?我喜欢 YARN,所以我将讲述它在 YARN 上是如何工作的,但是总的来说,对于任何你使用的集群管理器来说都是一样的:
在 YARN 上的 Spark 架构:

当你有一个 YARN 集群时,它有一个 YARN Resource Manager 守护进程,控制集群资源(实际上是内存)以及在集群节点上运行的一系列 YARN Node Managers,控制节点资源利用率。从 YARN 的角度来看,每个节点代表你有控制权的 RAM 池。当你向 YARN Resource Manager 请求一些资源时,它会给你提供你可以联系哪些 Node Managers 为你启动执行容器的信息。每个执行容器是一个具有请求堆大小的 JVM。JVM 位置由 YARN Resource Manager 选择,你无法控制它------如果节点有 64GB 的 RAM 被 YARN 控制(yarn-site.xml 中的 yarn.nodemanager.resource.memory-mb 设置)并且你请求 10 个执行器,每个执行器 4GB,它们所有的都可以容易地在一个 YARN 节点上启动,即使你有一个大集群。
当你在 YARN 之上启动 Spark 集群时,你指定了你需要的执行器数量(--num-executors 标志或 spark.executor.instances 参数)、每个执行器使用的内存量(--executor-memory 标志或 spark.executor.memory 参数)、每个执行器允许使用的核心数量(--executor-cores 标志或 spark.executor.cores 参数),以及为每个任务的执行专用的核心数量(spark.task.cpus 参数)。同时你还指定了驱动程序应用程序使用的内存量(--driver-memory 标志或 spark.driver.memory 参数)。
当你在集群上执行某事时,你的工作处理被分割成阶段,每个阶段又被分割成任务。每个任务分别被调度。你可以将每个作为执行者工作的 JVM 视为一个任务执行槽池,每个执行者会给你 spark.executor.cores / spark.task.cpus 执行槽供你的任务使用,总共有 spark.executor.instances 执行器。这是一个例子。有 12 个节点运行 YARN Node Managers 的集群,每个节点 64GB 的 RAM 和 32 个 CPU 核心(16 个物理核心与超线程)。这样,在每个节点上你可以启动 2 个执行器,每个执行器 26GB 的 RAM(为系统进程、YARN NM 和 DataNode 留下一些 RAM),每个执行器有 12 个核心用于任务(为系统进程、YARN NM 和 DataNode 留下一些核心)。所以总的来说你的集群可以处理 12 台机器 * 每台机器 2 个执行器 * 每个执行器 12 个核心 / 每个任务 1 个核心 = 288 个任务槽。这意味着你的 Spark 集群将能够并行运行多达 288 个任务,从而利用你在这个集群上拥有的几乎所有资源。你可以在这个集群上缓存数据的内存量是 0.9 * spark.storage.safetyFraction * 0.6 * spark.storage.memoryFraction * 12 台机器 * 每台机器 2 个执行器 * 每个执行器 26 GB = 336.96 GB。不算太多,但在大多数情况下它是足够的。
到目前为止效果很好,现在你知道了 Spark 如何使用它的 JVM 的内存以及你在集群上有哪些执行槽。正如你可能已经注意到的,我没有详细介绍"任务"究竟是什么。这将是下一篇文章的主题,但基本上它是 Spark 执行的一个单一工作单元,并作为 线程* 在执行器 JVM 中执行。这是 Spark 低作业启动时间的秘诀------在 JVM 中启动额外的线程比启动整个 JVM 快得多,而后者是在 Hadoop 中开始 MapReduce 作业时执行的。
现在让我们关注另一个叫做"partition"的 Spark 抽象。你在 Spark 中工作的所有数据都被分割成分区。一个单一的分区是什么,它是如何确定的?分区大小完全取决于你使用的数据源。对于大多数在 Spark 中读取数据的方法,你可以指定你想要在你的 RDD 中有多少分区。当你从 HDFS 读取一个文件时,你使用的是 Hadoop 的 InputFormat 来做到这一点。默认情况下,InputFormat 返回的每个输入分割都映射到 RDD 中的单个分区。对于 HDFS 上的大多数文件,每个输入分割生成一个对应于 HDFS 上存储的一个数据块的数据,大约是 64MB 或 128MB 的数据。大约,因为在 HDFS 中,数据是按照字节的确切块边界分割的,但是在处理时它是按照记录分割分割的。对于文本文件,分割字符是换行符,对于序列文件,是块末等等。这个规则的唯一例外是压缩文件------如果你有整个文本文件被压缩,那么它不能被分割成记录,整个文件将成为一个单一的输入分割,从而在 Spark 中成为一个单一的分区,你必须手动重新分区它。
现在我们所拥有的真的很简单------为了处理一个单独的数据分区,Spark 生成一个单一任务,这个任务在靠近你拥有的数据的位置(Hadoop 块位置,Spark 缓存的分区位置)的任务槽中执行。
参考