Futurepedia致力于使AI技术对各行各业的专业人士更加可理解和实用,提供全面的AI网站和工具目录、易于遵循的指南、每周新闻通讯和信息丰富的YouTube频道,简化AI在专业实践中的整合。如何把Futurepedia上的全部AI网站数据爬取下来呢?
网站一页有12个AI工具介绍,根据网站说明:We've categorized 5571 AI tools into 10 categories.,估计一共有465页。
每页的请求网址是:https://www.futurepedia.io/api/search
参数是:
{"verified":false,"sort":"popular","feature":\[\],"pricing":\[\],"q":"","page":3}
{"verified":false,"sort":"popular","feature":\[\],"pricing":\[\],"q":"","page":4}
在ChatGPT中输入提示词:
你是一个Python编程专家,完成一个Python脚本编写的任务,具体步骤如下:
在F盘新建一个Excel文件:futurepediaio20240609.xlsx
爬取网页:
请求网址:
https://www.futurepedia.io/api/search
请求方法:
POST
状态代码:
200 OK
远程地址:
127.0.0.1:10809
引荐来源网址政策:
strict-origin-when-cross-origin
请求载荷:{"verified":false,"sort":"popular","feature":\[\],"pricing":\[\],"q":"","page":{pagenumber}}
{pagenumber}从1开始,以1递增,以465结束
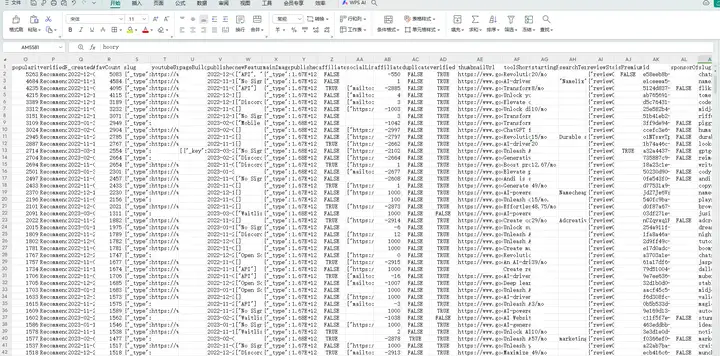
获取网页的响应,这是一个嵌套的json数据;
获取json数据中"data"键的值,这也是一个json数据;
提取每个json数据中所有键的名称,写入Excel文件的表头,所有键对应的值,写入Excel文件的数据列;
保存Excel文件;
注意:每一步都输出信息到屏幕;
每爬取1页数据后暂停5-9秒;
需要对 JSON 数据进行预处理,将嵌套的字典和列表转换成适合写入 Excel 的格式,比如将嵌套的字典转换为字符串。
要设置请求标头:
Accept:
application/json, text/plain, */*
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Content-Length:
77
Content-Type:
application/json
Origin:
Priority:
u=1, i
Referer:
https://www.futurepedia.io/?sort=popular
Sec-Ch-Ua:
"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
empty
Sec-Fetch-Mode:
cors
Sec-Fetch-Site:
same-origin
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
ChatGPT生成的源代码:
import requests
import openpyxl
import time
import random
import json
文件路径和名称
file_path = r"F:\futurepediaio20240609.xlsx"
创建一个新的 Excel 工作簿
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "Search Results"
请求的 URL 和方法
url = "https://www.futurepedia.io/api/search"
请求头
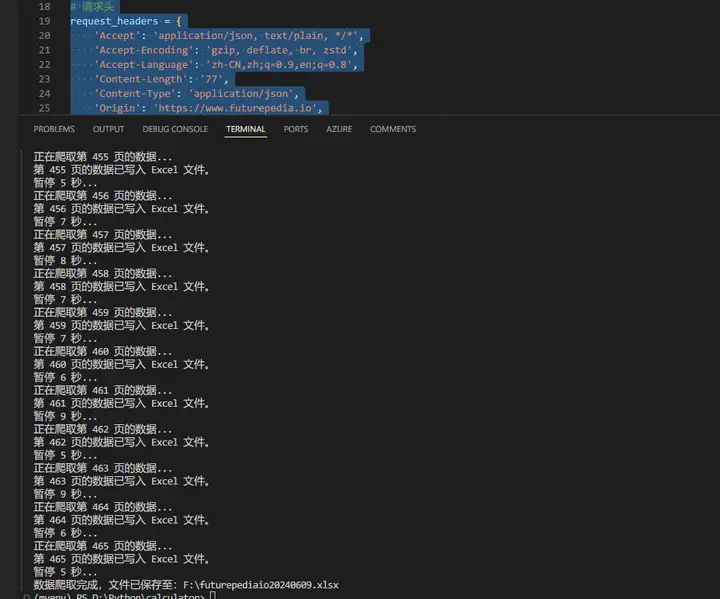
request_headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Content-Length': '77',
'Content-Type': 'application/json',
'Origin': 'https://www.futurepedia.io',
'Priority': 'u=1, i',
'Referer': 'https://www.futurepedia.io/?sort=popular',
'Sec-Ch-Ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
初始页码
page_number = 1
headers_written = False
数据处理函数:将嵌套的字典或列表转换为字符串
def clean_data(value):
if isinstance(value, (dict, list)):
return json.dumps(value, ensure_ascii=False) # 确保非 ASCII 字符被正确编码
return value
爬取数据
while page_number <= 465:
print(f"正在爬取第 {page_number} 页的数据...")
请求载荷
payload = {
"verified": False,
"sort": "popular",
"feature": \[\],
"pricing": \[\],
"q": "",
"page": page_number
}
发送 POST 请求
try:
response = requests.post(url, headers=request_headers, json=payload)
except Exception as e:
print(f"请求失败,错误信息:{e}")
break
检查请求是否成功
if response.status_code != 200:
print(f"请求失败,状态码:{response.status_code}")
break
获取 JSON 数据
data = response.json()
products = data.get("data", \[\])
if products:
if not headers_written:
获取 JSON 数据中的键作为表头
headers = set()
for product in products:
headers.update(product.keys())
headers = list(headers)
ws.append(headers)
headers_written = True
将数据写入 Excel
for product in products:
cleaned_product = clean_data(product.get(header, "")) for header in headers
ws.append(cleaned_product)
保存 Excel 文件
wb.save(file_path)
print(f"第 {page_number} 页的数据已写入 Excel 文件。")
随机暂停 5-9 秒
sleep_time = random.randint(5, 9)
print(f"暂停 {sleep_time} 秒...")
time.sleep(sleep_time)
else:
print(f"第 {page_number} 页没有数据。")
break
更新页码
page_number += 1
print(f"数据爬取完成,文件已保存至:{file_path}")