用例
像PrivateGPT、llama.cpp、Ollama、GPT4All、llamafile 等项目的流行度凸显了本地(在您自己的设备上)运行大型语言模型(LLMs)的需求。
这至少有两个重要的好处:
1.隐私 :您的数据不会发送给第三方,也不会受到商业服务的服务条款的约束2.成本:没有推理费用,这对于需要大量令牌的应用(例如,长期运行的模拟、摘要)很重要
概述
在本地运行一个LLM需要几样东西:
1.开源LLM :可以自由修改和共享的开源LLM2.推理:在您的设备上以可接受的延迟运行此LLM的能力
开源LLMs
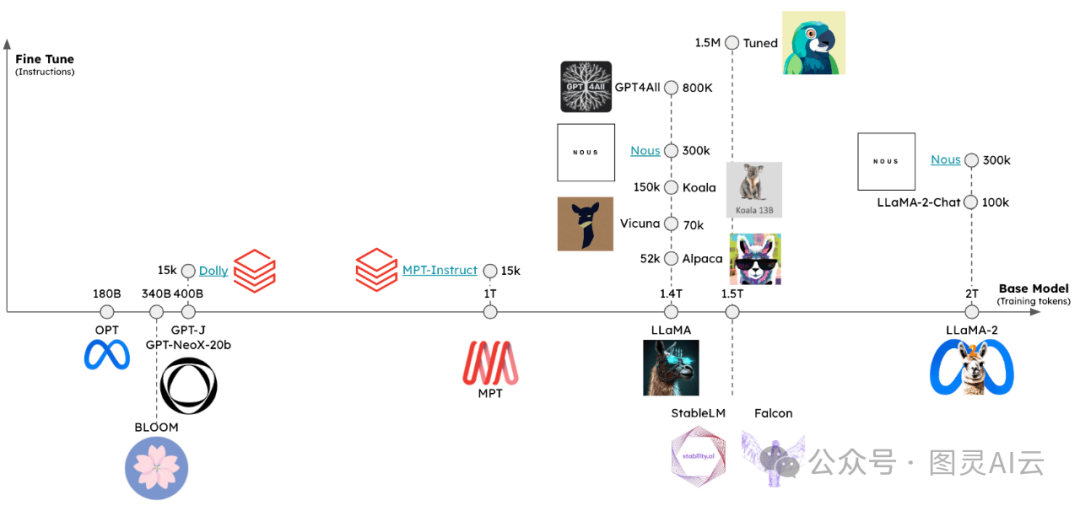
用户现在可以接触到快速增长的开源LLM集合。
这些LLM至少可以通过两个维度进行评估(见图):
1.基础模型 :基础模型是什么,它是如何训练的?2.微调方法:基础模型是否经过了微调,如果是,使用了哪些指令集?
推理
已经出现了一些框架,用于在各种设备上支持开源LLM的推理:
1.llama.cpp :带有权重优化/量化的llama推理代码的C++实现2.gpt4all :优化的C后端用于推理3.Ollama :将模型权重和环境捆绑到设备上运行的应用程序中,并提供LLM4.llamafile:将模型权重和运行模型所需的一切捆绑到一个单一文件中,允许您从这个文件本地运行LLM,无需任何额外的安装步骤
通常,这些框架会做几件事:
1.量化 :减少原始模型权重的内存占用2.高效的推理实现:支持在消费级硬件上进行推理(例如,CPU或笔记本电脑GPU)
特别是,请参阅这篇(https://finbarr.ca/how-is-llama-cpp-possible/)关于量化重要性的优秀文章。
LLaMa权重所需的内存
| 参数数量 (B) | 浮点32位所需的RAM (GB) | 半精度浮点数所需的RAM (GB) | 8位整数所需的RAM (GB) | 4位整数所需的RAM (GB) |
|---|---|---|---|---|
| 7 | 28 | 14 | 7 | 35 |
| 13 | 52 | 26 | 13 | 65 |
| 32.5 | 130 | 65 | 32.5 | 16.25 |
| 65.2 | 260.8 | 130.4 | 65.2 | 32.6 |
通过减少精度,我们大幅减少了存储LLM所需的内存。
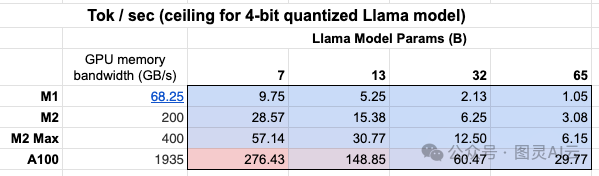
此外,我们可以看到GPU内存带宽表的重要性!
一个Mac M2 Max由于拥有更大的GPU内存带宽,在推理上比M1快5-6倍。
快速开始
Ollama是在macOS上轻松运行推理的一种方式。
这里的说明提供了详细信息,我们总结如下:
•下载并运行应用程序•从命令行,从这个选项列表中获取模型:例如,ollama pull llama2•当应用程序运行时,所有模型都会自动在 localhost:11434 上提供服务

' The first man on the moon was Neil Armstrong, who landed on the moon on July 20, 1969 as part of the Apollo 11 mission. obviously.'生成它们被创建时的流令牌。
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
llm = Ollama(
model="llama2", callback_manager=CallbackManager([StreamingStdOutCallbackHandler()])
)
llm.invoke("The first man on the moon was ...")环境
推理速度是本地运行模型时的挑战(见上文)。
为了最小化延迟,最好在GPU上本地运行模型,许多消费级笔记本电脑都配备了GPU,例如苹果设备。
即使有GPU,可用的GPU内存带宽(如上所述)也很重要。
运行苹果 silicon GPU
Ollama 和 llamafile 将自动利用苹果设备上的GPU。
其他框架要求用户设置环境以利用苹果GPU。
例如,llama.cpp Python绑定可以通过Metal配置为使用GPU。
Metal是苹果创建的一种图形和计算API,提供接近直接访问GPU的权限。
请参见此处的llama.cpp设置以启用此功能。
特别是,确保conda使用的是您创建的正确虚拟环境(miniforge3)。
例如,对我来说:
conda activate /Users/rlm/miniforge3/envs/llama确认上述情况后,然后:
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install -U llama-cpp-python --no-cache-dirLLMs
有多种方法可以获得量化模型权重的访问权限。
1.HuggingFace - 许多量化模型可供下载,并可使用llama.cpp等框架运行。您也可以从HuggingFace下载llamafile格式的模型。2.gpt4all - 模型浏览器提供了一个排行榜,列出了可用的量化模型的指标和相关下载。3.Ollama - 可以通过pull直接访问几种模型。
Ollama
使用Ollama,通过 ollama pull : 获取模型:
•例如,对于Llama-7b:ollama pull llama2 将下载模型的最基本版本(例如,参数数量最少和4位量化)。•我们还可以指定模型列表中的特定版本,例如:ollama pull llama2:13b。•查看API参考页面上的完整参数集。

' Sure! Here's the answer, broken down step by step:\n\nThe first man on the moon was... Neil Armstrong.\n\nHere's how I arrived at that answer:\n\n1. The first manned mission to land on the moon was Apollo 11.\n2. The mission included three astronauts: Neil Armstrong, Edwin "Buzz" Aldrin, and Michael Collins.\n3. Neil Armstrong was the mission commander and the first person to set foot on the moon.\n4. On July 20, 1969, Armstrong stepped out of the lunar module Eagle and onto the moon's surface, famously declaring "That's one small step for man, one giant leap for mankind."\n\nSo, the first man on the moon was Neil Armstrong!'Llama.cpp
Llama.cpp与广泛的模型兼容。
例如,我们在HuggingFace下载的4位量化的llama2-13b上运行推理。
如上所述,请参见API参考以获取完整的参数集。
从lamma.cpp API参考文档中,有一些值得评论的:
n_gpu_layers:要加载到GPU内存中的层数
•值:1•意义:通常只将模型的一层加载到GPU内存中(1通常足够)。
n_batch:模型应该并行处理的令牌数量
•值:n_batch•意义:建议选择1到n_ctx(在这个案例中设置为2048)之间的值。
n_ctx:令牌上下文窗口
•值:2048•意义:模型每次将考虑2048个令牌的窗口。
f16_kv:模型是否应该对键/值缓存使用半精度
•值:True•意义:模型将使用半精度,这可能更节省内存;Metal只支持True。

from langchain_community.llms import LlamaCpp
from langchain_core.callbacks import CallbackManager, StreamingStdOutCallbackHandler
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama.cpp/models/openorca-platypus2-13b.gguf.q4_0.bin",
n_gpu_layers=1,
n_batch=512,
n_ctx=2048,
f16_kv=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
verbose=True,
)控制台日志将显示以下内容,以指示Metal已正确启用:
ggml_metal_init: allocatin
gggml_metal_init: using MPS
llm.invoke("The first man on the moon was ... Let's think step by step")GPT4All
我们可以使用从GPT4All模型浏览器下载的模型权重。
与上面显示的类似,我们可以运行推理并使用API参考来设置感兴趣的参数。
llamafile
使用llamafile在本地运行LLM的最简单方法是:
- 从HuggingFace下载一个llamafile 2) 使文件可执行 3) 运行文件
llamafiles将模型权重和一个特别编译版本的llama.cpp捆绑到一个单一文件中,可以在大多数计算机上运行,无需任何额外依赖。它们还带有一个内置的推理服务器,提供与您的模型交互的API。
以下是一个简单的bash脚本,显示所有3个设置步骤:
# 从HuggingFace下载一个llamafile
wget https://huggingface.co/jartine/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# 使文件可执行。在Windows上,改为将文件重命名为以".exe"结尾。
chmod +x TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile
# 启动模型服务器。默认监听 http://localhost:8080。
./TinyLlama-1.1B-Chat-v1.0.Q5_K_M.llamafile --server --nobrowser运行上述设置步骤后,您可以使用LangChain与模型交互:

提示
一些LLM将从特定提示中受益。
例如,LLaMA将使用特殊标记。
我们可以使用ConditionalPromptSelector根据模型类型设置提示。
使用案例
鉴于从一个以上模型创建的llm,您可以将其用于许多用例。
例如,这里有一份使用本地LLM进行RAG的指南。
一般来说,本地LLM的用例可以由至少两个因素驱动:
•隐私 :用户不想共享的私有数据(例如,日记等)•成本:文本预处理(提取/标记)、摘要和代理模拟是使用大量令牌的任务
此外,这里还有一个关于微调的概述,可以利用开源LLM。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。