目录
一、实验目的
- 掌握分治法思想。
- 学会最近点对问题求解方法。
二、实验概述
分治法也称为分解法、分治策略等。分治法算法思想如下:
(1) 将一个问题划分为同一类型的若干子问题,子问题最好规模相同。
(2) 对这些子问题求解(一般使用递归方法,但在问题规模足够小时,有时也会利用另一个算法)。
(3) 有必要的话,合并这些子问题的解,以得到原始问题的答案。
当子问题足够大时,需要递归求解时,我们称之为递归情况(Recursive Case)。当子问题变得足够小,不再需要递归时,表示递归已经"触底",进入了基本情况(Base Case)。
三、实验内容
-
对于平面上给定的N个点,给出所有点对的最短距离,即,输入是平面上的N个点,输出是N点中具有最短距离的两点。
-
要求随机生成N个点的平面坐标,应用蛮力法编程计算出所有点对的最短距离。
-
要求随机生成N个点的平面坐标,应用分治法编程计算出所有点对的最短距离。
-
分别对N=100000---1000000,统计算法运行时间,比较理论效率与实测效率的差异,同时对蛮力法和分治法的算法效率进行分析和比较。
-
如果能将算法执行过程利用图形界面输出,可获加分。
四、问题描述
1.实验基本要求
- 随机生成n个点的随机坐标,且必须保证n个点均没有出现重复
- 使用蛮力法求解点的最短距离
- 使用分治法求解点的最短距离
- 分别对n=100000---1000000,统计算法运行时间,比较理论效率与实测效率的差异
- 对蛮力法和分治法的算法效率进行分析和比较
- 将算法执行过程利用图形界面输出
2.实验亮点
- 通过暴力法以及分治法详细介绍"最近点对"问题的实现方法
- 完成两种算法的++图形界面++ 可视化,使算法执行过程更清晰
- 完成数据运行效率的对比
- 对于算法实现的过程,绘制了算法示意图和算法流程图
3.实验说明
- 本实验从大规模数据验证了两种算法的正确性
- 本实验是基于蛮力法进行比较的
- 各算法消耗时间以秒为单位,只包含搜索的过程
五、算法原理和实现
1. 算法原理和实现
实验流程
首先通过随机数生成器生成特定范围内的double型数据,然后对点集分别使用蛮力法和分治法进行运算,计算出所有点对中的最短距离以及运行的时间消耗,并通过对比实际消耗与理论消耗、蛮力法与分治法消耗对比进行算法效率分析,得出实验结论

数据生成
在本题中,我选择使用随机设备做种子,并设置生成器,生成随机数为0-100以内的双精度浮点数,并用point结构体储存位置

数据去重
由于随机值生成的过程中有可能生成重复点的情况,因此需要对重复的点进行剔除
在生成随机数时,通过依次对比避免重复

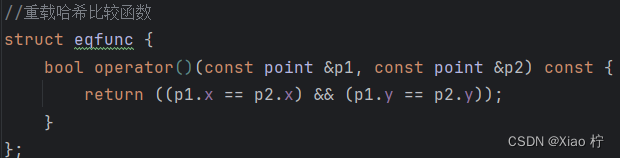
同时重载哈希比较函数,在进行分治法时发挥作用
2. 蛮力法
算法原理
不断遍历求出每个点之间的距离,并选择距离最小的两个点进行输出
流程示意
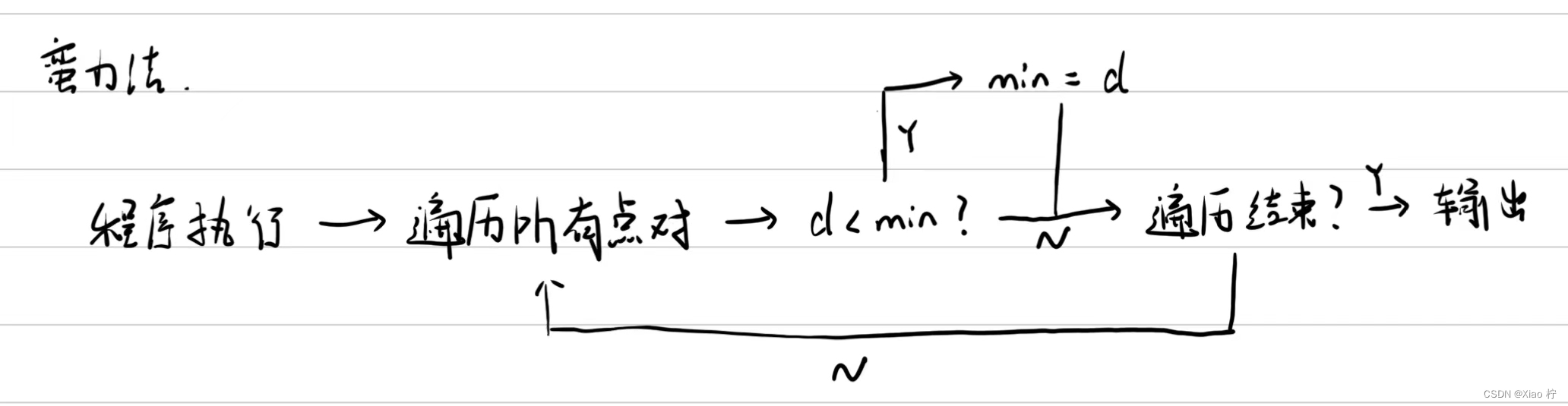
实验伪代码

时间复杂度分析
共内外两次循环,时间复杂度为O(n^2),可将其看作一个求n边无向完全图问题,即对于n个顶点每个顶点都连着n-1条边,共有边数为n(n-1)/2,也可得出时间复杂度为O(n^2)
3. 分治法
算法描述
根据问题描述,我们只需要在所有点对中求得一个两点之间的最短距离,而所有点对中,存在着一些明显就很远的点对,而对于这些点对的距离求解及比较完全是一种无用功,将造成时间和空间的双重浪费
为了简化蛮力法,降低无用比较次数,我们可以选择将所有点对组成的一个大整体拆分成几个小部分,进行分而治之,再合并求得其中的一个最小值,其即为我们需要求得的最短距离
算法内容
结合上述分析,我们可以使用分治法,利用分而治之的思想将问题实现简化,其算法关键内容包括:
a预处理: 将所有点对按照其横坐标进行排序,便于后续将点对均分为两部分,分别对其两个子问题进行求解
b基本情况base(递归返回条件):
若 n=1 return 无穷大
若 n=2 return 两点间距离
若 n=3 return 三间较小的距离
else n>3 则以该组坐标的下标中值进行再一次分块,mid=(l+ r)/2、midnum=arrmid.x,将规模为n的问题再次分为两个规模为n/2的子问题,分别求其最短距离,复杂度为O(1)
c 取两个子问题返回最短距离较小的那个,d=min(dl, dr)
d 合并子问题的点,找到所有横坐标范围再mid-d, mid +d中的点,并根据纵坐标的值对其点进行排序
e 对于mid-d, mid中的每一点,检查mid, mid +d中的点与它的距离,更新所获得的最近距离
实验流程
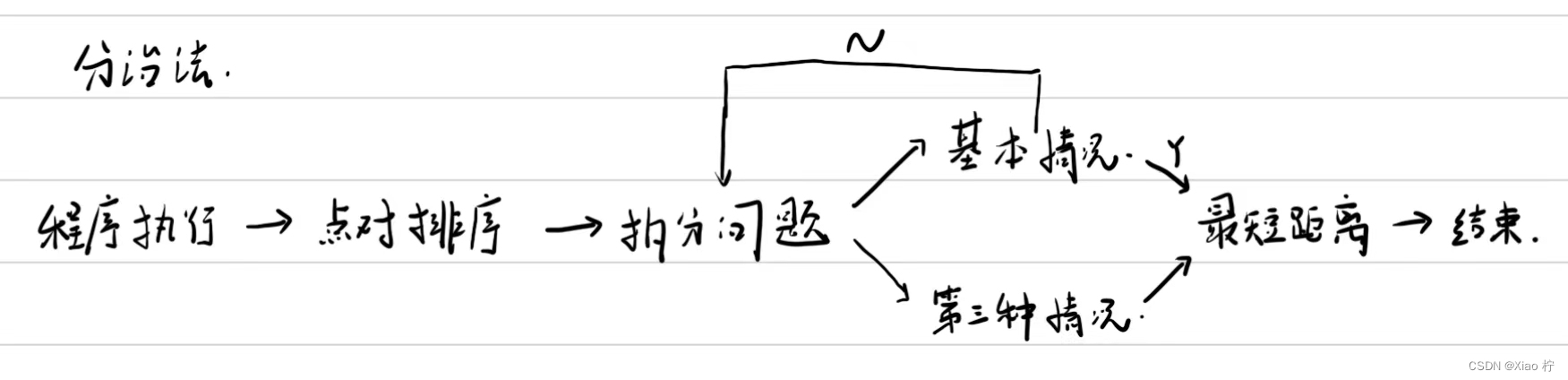
算法实现
将所有点按照x坐标进行排序,并将平面分为两个大致相等的点集


则此时,对于求任意两点p1,p2之间的距离,存在三种情况:
p1,p2 都位于左侧点集
p1,p2 都位于右侧点集
p1,p2 一个位于左侧点集,一个位于右侧点集
对于情况1和情况2,我们只需要不断进行递归并结合返回条件便可得到结果

以下为针对于情况3的求解:
递归得到两边点子集的最近点对距离,取最小值d,其中d=min(dl,dr),距离d来缩小我们查找的空间,中间点向外扩散,如果点与中间点的x左边之差,大于d,那么这个点及其往后的点,都不可能是最优的答案,缩小了查找空间

然而通过缩小查找空间来提高效率,其实是不稳定的,可能查找空间和原来一样,若继续通过蛮力法枚举查找,时间复杂度仍为O(n^2),达不到线性的复杂度
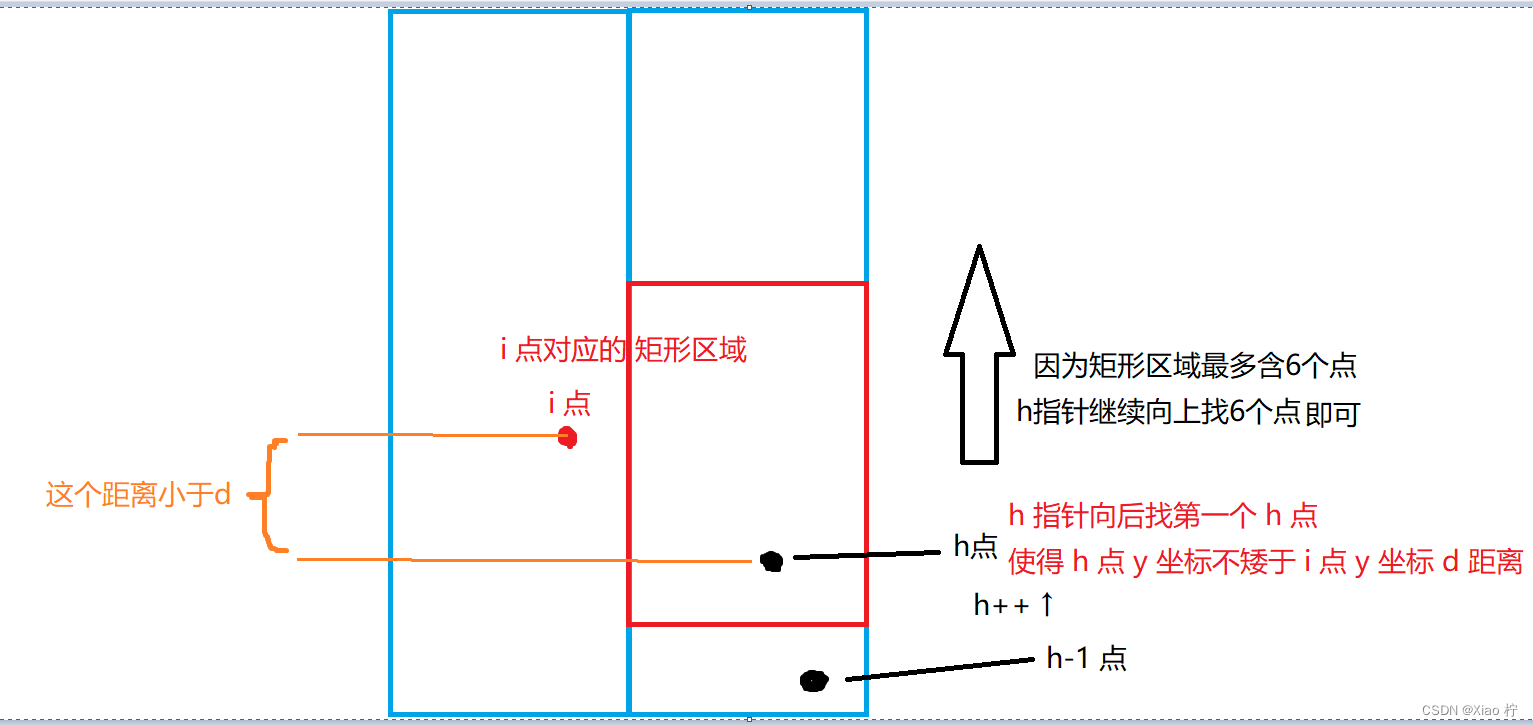
对于点对在L-d, L+d的数据,我们可以做出以下假设,对于对于左边区域的每一点p1要想在右边区域找到一点p2得 p1p2的距离<=d,这样的点p2必定存在于【以p1的y坐标为中心,上下延展d形成的d*2d的子矩形中】
证明:在一般情况及特殊情况下

通过遍历左边区域的所有点,划分出d*2d的矩形区域,然后检查6个点,更新答案即可,而这需要浪费O(n)的复杂度,则我们需要在O(1)的复杂度里找到d*2d的矩形区域,并求出最短距离
将左右的子区域的所有点对按照纵坐标进行排序,在对左侧区域所有点进行升序遍历时,设置指针h在右侧区域的点对向后查找,当左侧的点与查找到的右侧的点高度差小于d时,从h向后找六个点即可
由于左右区域的点均为升序排序,因此下一个左侧的点对应的指针h的下边界一定会变大,因此,h只需要在原来基础上继续进行比较,其比较最多的次数为右侧区域点集的大小,复杂度为O(1),而进行查找的操作为6次,其时间复杂度仍为O(1),所以,总的时间复杂度仍为O(n)
算法实验伪代码
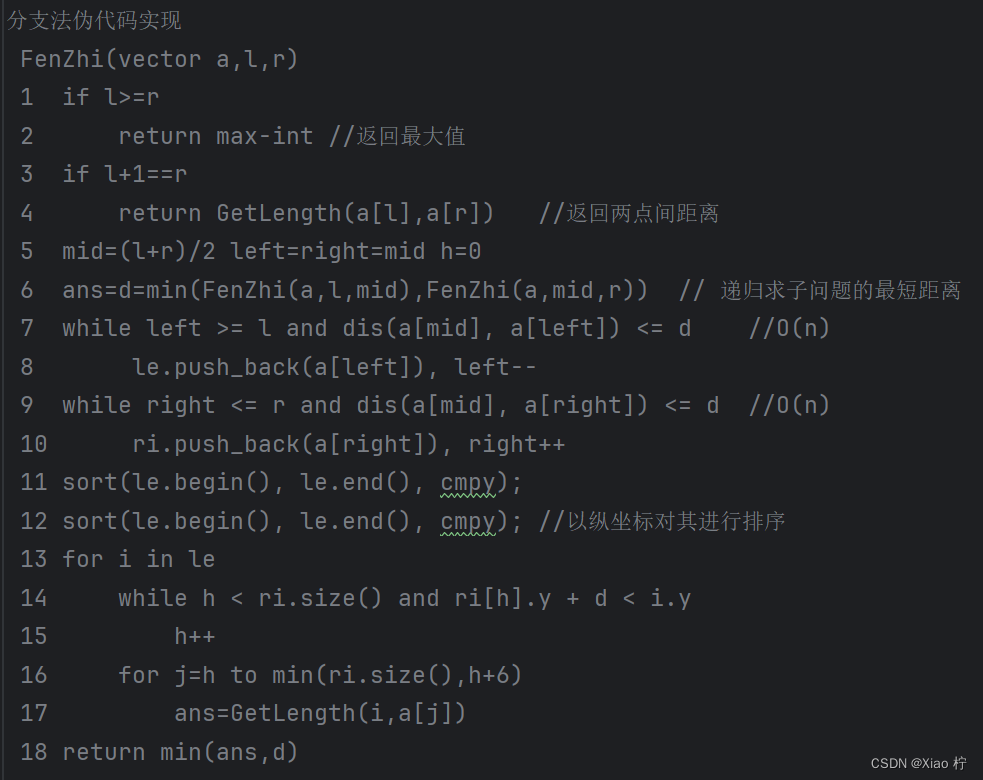
算法复杂度分析
递推式如下:T(n) = 2T(2/n) + n*log(n)

算法的改进
在未进行递归的情况下,时间复杂度最大为O(n*logn), 而产生这样的复杂度是由于在解决第三种情况时,需要对数据进行排序,此时排序时间复杂度便达到了O(n*logn),若效仿归并排序,每次二分递归之后,我们对数组归并,因为递归排好了左右子区间,这样归并后,数组就是对y有序的了,不用消耗额外的时间再排序了,可以使合并子问题的代价变为O(n)级别
改进实现
更改返回条件-当有两个点时,需要对其进行比较
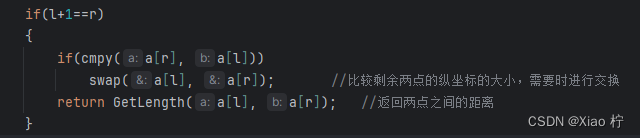
在对子问题进行求解完成后,需要对进行合并,其合并过程为根据mid将数组分为的两个子数组,分别从最右边和中间开始,依次向左进行排查,小则左移(具体排序过程与合并排序一致)
算法复杂度分析

六、实验结果和分析
算法正确性测试
测试之前做了1万(10086)次验证,生成随机数据,比对两种分治法与暴力法的结果(暴力法保证正确),结果三种方法结果全部相等,排除算法bug导致时间误差,生成的每组数据被复制若干份,保证每次每个算法用到的数据是同一批,排除数据随机生成导致的时间误差
蛮力法结果及效率分析
算法运行时间
|------|-------|--------|--------|--------|---------|
| 数量级 | 10000 | 20000 | 30000 | 40000 | 50000 |
| 实际时间 | 4.529 | 18.431 | 42.64 | 72.776 | 115.044 |
| 理论时间 | 4.529 | 18.116 | 40.761 | 72.464 | 113.225 |
可得下表
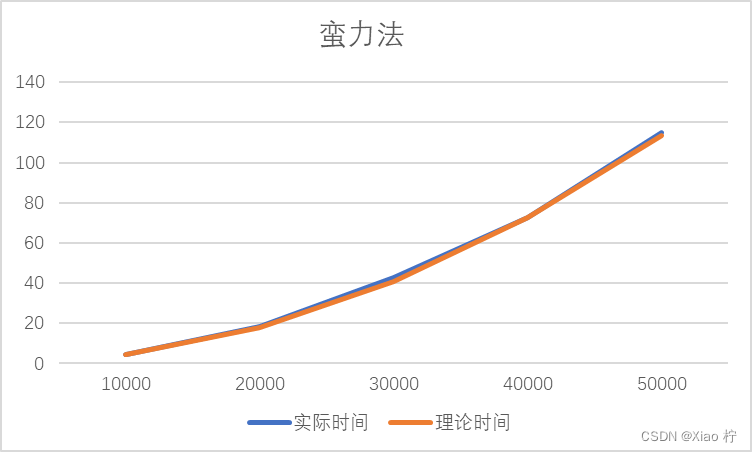
对于暴力穷举,由于算法未进行任何简化且算法执行次数与时间复杂度不随数据分布与数量级有任何变化,故整体拟合效果非常好,证明暴力法的时间复杂度为O(n^2)的结论正确。从图像上,图像符合n^2函数的趋势,从数据上,规模扩大k倍时,时间开销扩大k^2倍
对于大规模数据,当数据规模为十万时,蛮力法消耗的时间已经达到了358.188秒,效率极差;当数据规模进一步扩大为1百万时,消耗的时间以及达到了近十个小时(35770.2秒),已经几乎达到了不可算点
分治法结果及效率分析
算法运行时间
|------|-------|-------|-------|-------|-------|
| 数量级 | 10000 | 20000 | 30000 | 40000 | 50000 |
| 实际时间 | 0.023 | 0.055 | 0.076 | 0.099 | 0.127 |
| 理论时间 | 0.023 | 0.053 | 0.086 | 0.122 | 0.158 |
可得下表
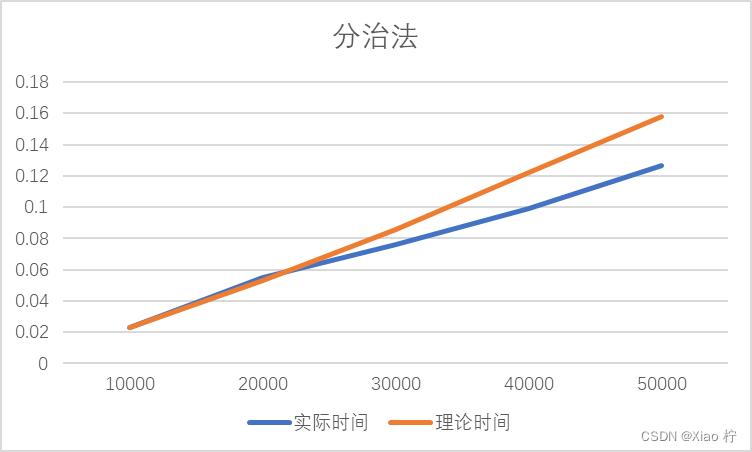
可见,实际消耗时间与理论值整体拟合效果较好,也满足其时间复杂度为O(n*logn^2)
大规模数据下的分治法
|------|--------|--------|--------|---------|---------|
| 数量级 | 100000 | 200000 | 500000 | 1000000 | 2000000 |
| 实际时间 | 0.299 | 0.583 | 1.489 | 3.164 | 6.733 |
| 理论时间 | 0.299 | 0.672 | 1.942 | 4.306 | 9.497 |
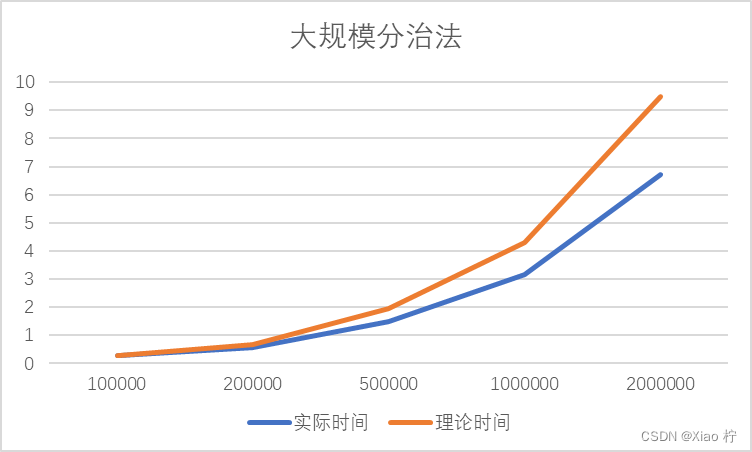
可见对于大规模数据,分治法也有十分优异的性能
蛮力法与分治法的比较
|-----|-------|--------|-------|--------|--------|
| 数量级 | 10000 | 20000 | 30000 | 40000 | 50000 |
| 分治法 | 0.023 | 0.055 | 0.076 | 0.099 | 0.127 |
| 蛮力法 | 4.529 | 18.431 | 42.64 | 72.776 | 115.04 |
可得下图

从上表和上图可以明显的看出,当数据规模足够大的时候,分治法的平均效率要远高于蛮力法,而当数据量较少时,二者并无多大差异,甚至由于分治法需要不断调用、开辟空间,其效率会低于蛮力法
普通分治与优化分治法的比较
对两种分治法进行数据规模从一万到一个亿的测试,得到以下结果:
|------|---------|---------|---------|---------|---------|
| 数量级 | 1000000 | 2000000 | 4000000 | 6000000 | 8000000 |
| 普通分治 | 3.237 | 6.831 | 14.763 | 22.935 | 30.461 |
| 优化分治 | 3.272 | 6.972 | 14.272 | 22.136 | 28.471 |
得到下表
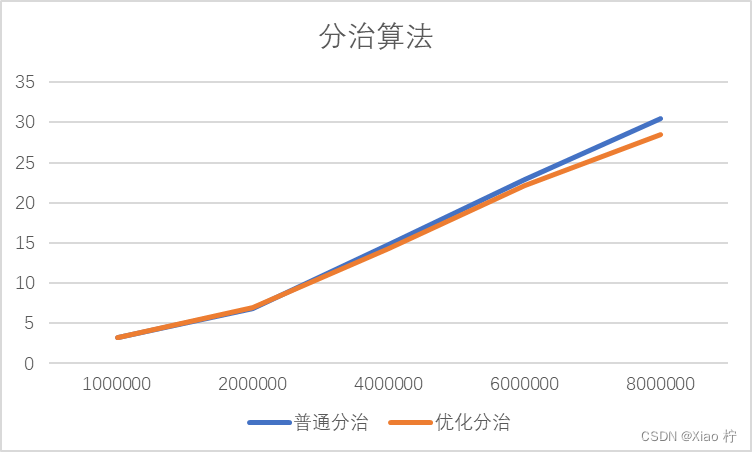
两种方法均能较好的处理大规模数据问题,且二者消耗的时间相差不大
从数据变化及二者对比我们可以看出,当数据规模较小时,未优化的分治法比优化后的算法效率甚至还快一点,主要是因为优化后的算法需要开辟较多的内存空间进行存储数据,会消耗过多的时间,而当数据规模变大时,这种影响便可被忽略掉,因此,随着数据规模逐渐变大,优化后的分治算法的优势便逐渐展现出来
七、实验结论
算法的优化
在实验的过程中,我发现求两点之间距离的函数是最频繁使用的,而获取距离的操作为调用sqrt函数,也要经历做差、平方、求和以及再开方的步骤,在这个途中需要消耗时间,因此,倘若省去开方,直接比较距离的平方值,最终在返回的值上开方,也可以实现目的从而在一定程度上节省常数运算的时间
以蛮力法为例,优化前后消耗时间如下表所示:
|-----|-------|--------|--------|--------|---------|
| 数量级 | 10000 | 20000 | 30000 | 40000 | 50000 |
| 未优化 | 4.529 | 18.431 | 42.64 | 72.776 | 115.044 |
| 优化后 | 3.902 | 15.158 | 34.747 | 62.33 | 98.299 |
可见,优化后比优化前节省了大约20%的时间
算法过程的可视化
通过python的matplotlib库的pyplot子库进行图形的绘制,在递归的同时记录栈状态,递归结束之后使用图形的方式输出递归的过程,比如边界的划分,子问题的合并,以及点的选择
八、实验收获
实验心得
在测试递归程序的时候,一定要保证合并操作的正确性,递归的答案可以先用暴力法代替,然后观察合并的结果是否和暴力法结果一致
遇到问题的时候要想,能否通过数学的方法,压缩问题的解,使得求解范围缩小,甚至变为常数,比如通过划分d*2d的矩形来压缩求解的空间
代码的常数开销也很重要,代码常数开销过大,可能会导致预测的时间出现偏差,编程时应该尽量减小常数的开销
图形界面可视化可以更加清晰的展示一个算法的实现过程,有助于加深对算法的理解
遇到的问题
在实验过程中,发现分治法的时间消耗非常大!

经过代码排查,发现是由于分治函数参数中,我没有选择引用,而是每次调用都需要开辟额外的空间进行存储,严重拉低了程序运行的速度,改善和:
在对分治法进行优化时,想要在递归时同时对左右两侧的点进行以纵坐标为标准的合并排序,在排序完成进行两个子数组合并时

采用了以上向量自带的合并方法,结果发现,优化后的分治法并不比优化前的效率好,查询资料后,发现该方法的算法复杂度仍为O(nlogn),因此采取此方法并不能对整体的算法复杂度有很好的一个优化效果