//计数排序:
void CountSort(int* a, int n)
{
//求最大和最小值
int max = a[0];
int min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int ragem = max - min + 1;
//计数的数组
int* count = (int*)calloc(ragem, sizeof(int));;
if (count == NULL)
{
perror("calloc fail");
return;
}
//计数
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;
}
int j = 0;
//排序
for (int i = 0; i< ragem; i++)
{
while (count[i]--)
{
a[j++] = i+ min;
}
}
}

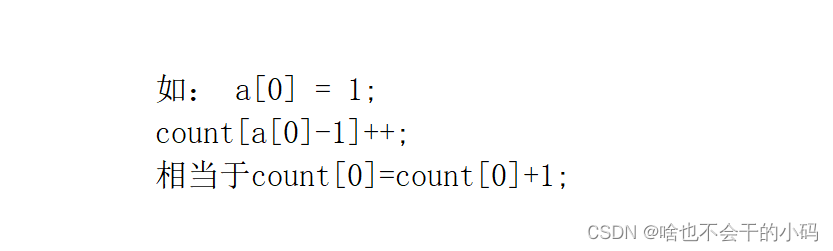



 拜 拜 喽
拜 拜 喽 