1. 外排序介绍
外排序(External sorting):是指能够处理极大量数据的排序算法。
通常来说,外排序处理的数据量过大,存储在外存中,不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。
外排序通常采用的是一种"排序-归并"的策略:
- 在排序阶段,先读入能放在内存中的数据量,将其排序输出到一个临时文件file_i,依次进行,将待排序数据组织为多个有序的临时文件:file1、file2、......。
- 在归并阶段,将这些临时文件组合为一个大的有序文件,也即排序结果。
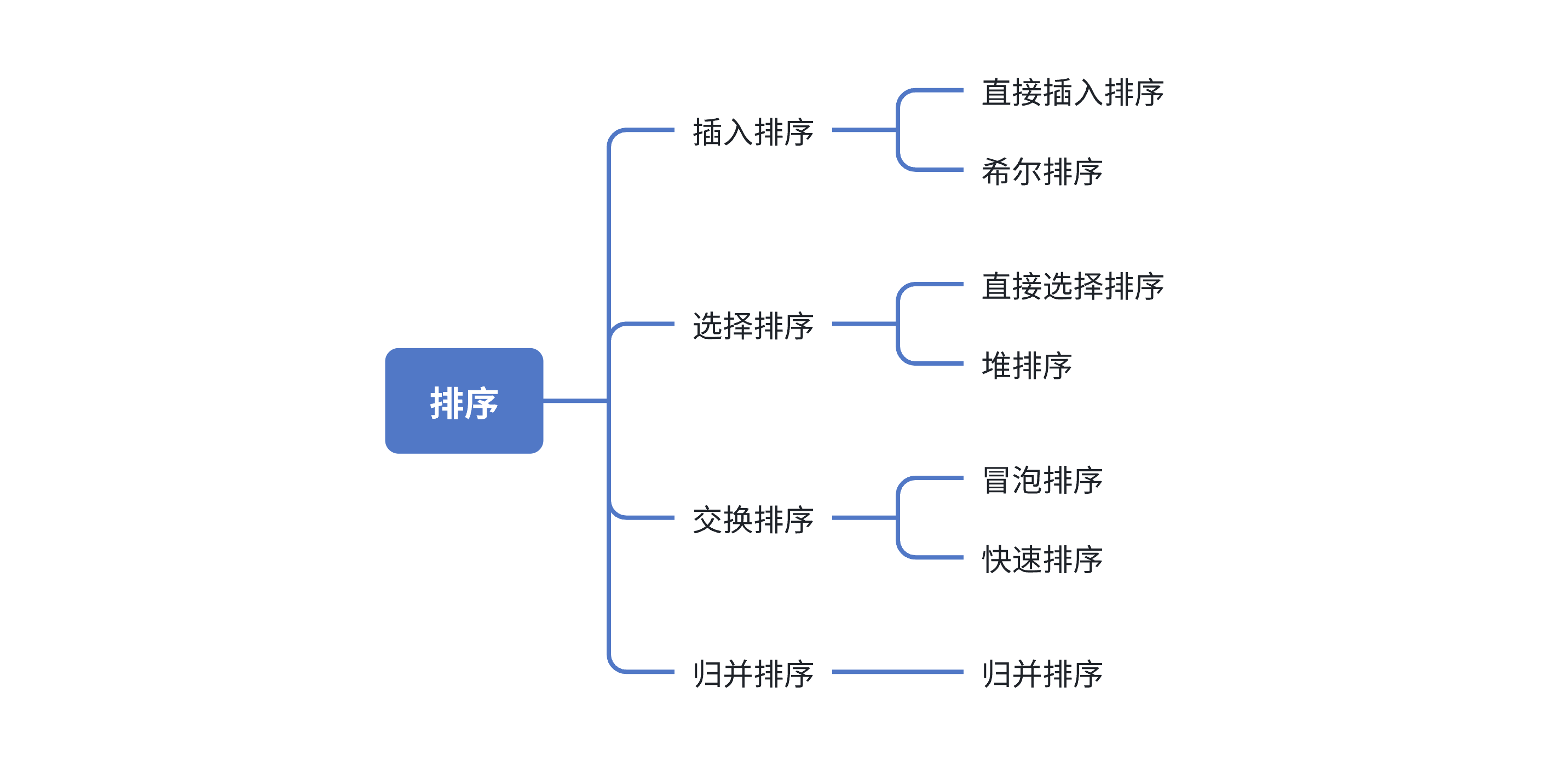
跟外排序对应的就是内排序,我们之前讲的常见的排序,都是内排序,他们排序思想适应的是数据在内存中,支持下标随机访问。
------去随机访问外存,存取速度就太慢了,所以堆排、快排、希尔、......等算法不适用作外排序
归并排序的思想不需要随机访问数据,只需要依次按序列读取数据。
所以归并排序既是一个内排序,也是一个外排序。
2. 外排序实现
2.1 创建随机数据文件的代码
cpp
// 创建N个随机数,写到⽂件中
void CreateNDate()
{
// 造数据
int n = 1000000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i) //创造100万个数据
{
int x = rand() + i;
//默认范围: rand()返回0到RAND_MAX的伪随机整数,RAND_MAX通常为32767(定义在stdlib.h中)
//+i能产生更大范围内的随机数
fprintf(fin, "%d\n", x);
}
fclose(fin);
}2.2 文件归并排序思路分析
理由1:归并排序,只要求归并的两个数组有序,而堆对两个数组的数据量没有要求。
理由2:上面的外排序的"排序-归并"策略其实不太好控制,不知道要创建多少个文件,每次对哪两个文件进行归并,都是不太方便控制的。
所以上面的外排序的"排序-归并"策略可以修改为如下思路:
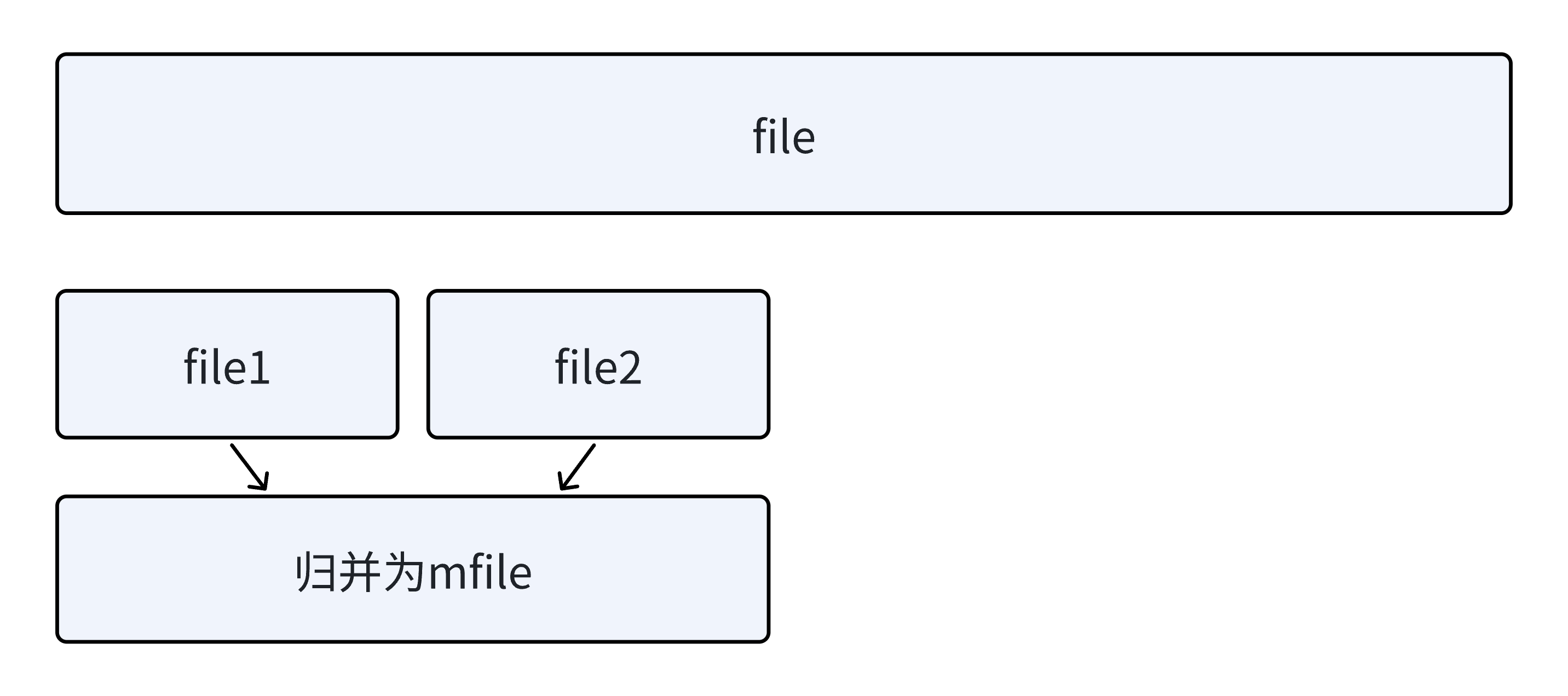
读取n个值排序后写到file1,再读取n个值排序后写到file2。
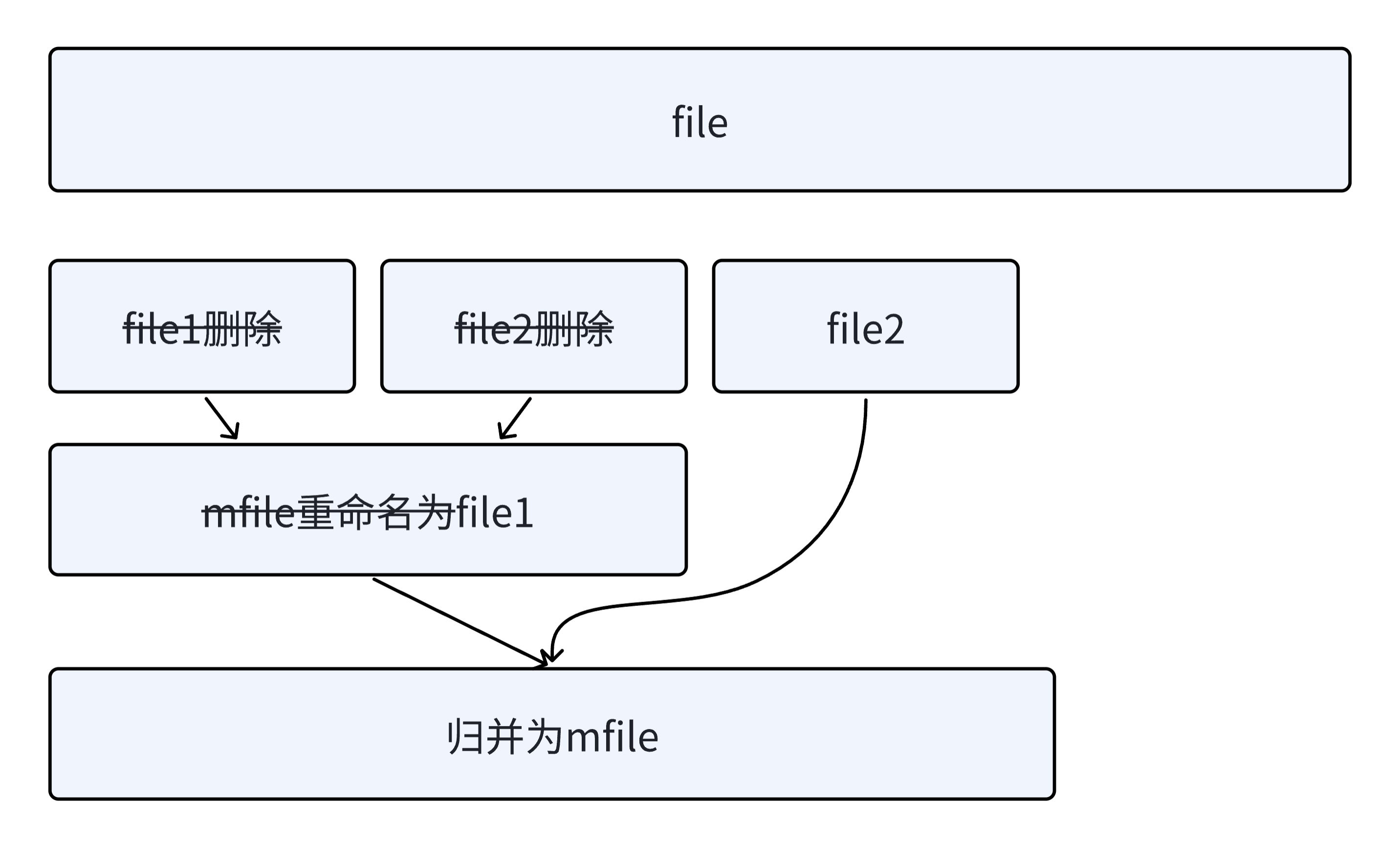
file1和file2利用归并排序的思想,依次读取比较,取小的尾插到mfile,mfile归并为一个有序文件。
将file1和file2删掉,mfile重命名为file1。
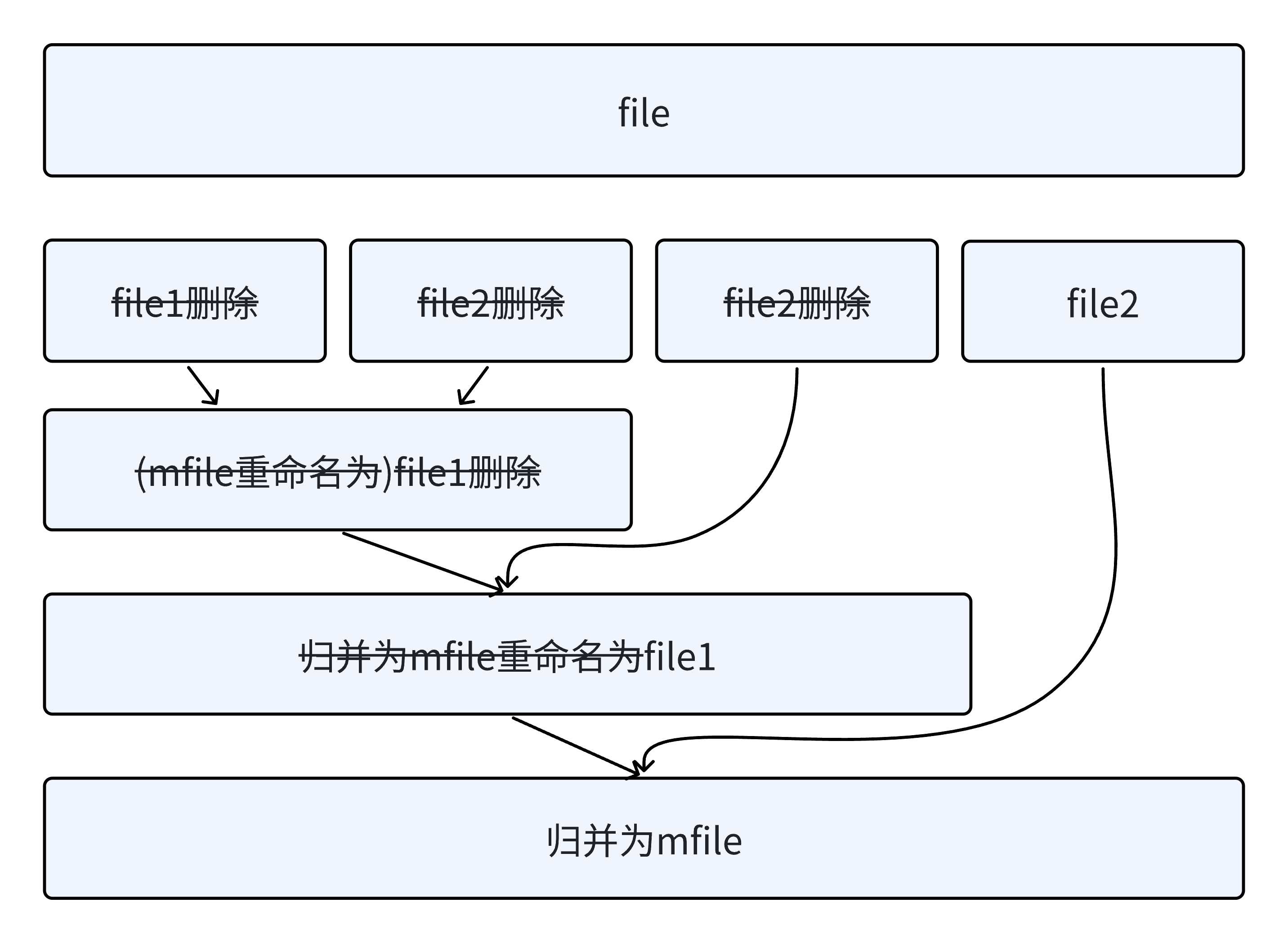
再次读取n个数据排序后写到file2。
继续走file1和file2归并,重复步骤2,直到文件中无法读出数据。
最后归并出的有序数据放到了file1中。
不断重复file1和file2归并。
2.3 文件归并排序代码实现
学习一个新函数------删除文件函数remove()。

学习一个新函数------重命名文件函数rename()。

cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
// 选出左右孩⼦中⼤的那⼀个
if (child + 1 < n && a[child + 1] > a[child])
++child;
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
// 建堆 -- 向下调整建堆 -- O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[end], &a[0]);
AdjustDown(a, end, 0);
--end;
}
}
// file1⽂件的数据和file2⽂件的数据归并到mfile⽂件中
void MergeFile(const char* file1, const char* file2, const char* mfile)
{
//打开文件1
FILE* fout1 = fopen(file1, "r");
if (fout1 == NULL)
{
printf("打开⽂件失败\n");
exit(-1);
}
//打开文件2
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("打开⽂件失败\n");
exit(-1);
}
//打开文件3
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
printf("打开⽂件失败\n");
exit(-1);
}
// 这里跟内存中数组归并的思想完全类似,只是数据在硬盘⽂件中⽽已
// 依次读取file1和file2的数据,谁的数据⼩,谁就往mfile⽂件中去写
// file1和file2其中⼀个⽂件结束后,再把另⼀个⽂件未结束⽂件数据,
// 依次写到mfile的后⾯
int num1, num2;
int ret1 = fscanf(fout1, "%d\n", &num1);
int ret2 = fscanf(fout2, "%d\n", &num2);
while (ret1 != EOF && ret2 != EOF)
{
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
else
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
while (ret1 != EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
//1.函数外创建数组,作为参数传递给这个函数来操作的方式------外部free
//int ReadNDataSortToFile(const char* file, int* a, int n, const char* file1)
//2.函数内创建数组,自己创建自己操作的方式------需要自己free(注意在if语句里面的free!!!)------两处if
// 从源文件中读取N个数据到1个小文件中
// 返回读取到的数据个数
// 参数:源文件名(用于正确打开)、N、宿文件名
//int ReadNDataSortToFile(const char* file, int n, const char* file1)
// 缺陷:每次重新打开源文件读,都从起始位置开始------不符合要求
// 参数:源文件指针、N、宿文件名
int ReadNDataSortToFile(FILE* fout, int n, const char* file)
{
int x = 0;
// 函数内创建数组的方式
int* a = (int*)malloc(sizeof(int) * n);
if (a == NULL)
{
perror("malloc error");
return 0;
}
// 1.读取n个数据到内存中
//int j = 0;
//for (int i = 0; i < n; i++)
//{
// if (fscanf(fout, "%d", &x) == EOF) //读取到j个数据
// break;
// a[j++] = x;
//}
// 直接使用while循环
int i = 0;
while (i < n && fscanf(fout, "%d", &x) != EOF)
{
a[i++] = x; //读取到i个数据
}
// ⼀个数据都没有读到,则说明⽂件已经读到结尾了
if (i == 0)
{
free(a);
return i;
}
// 2.在内存中对N个数据排序------堆排序、快排、......
HeapSort(a, i);
// 3.将内存中的N个已排序数据输出到1个小文件中。
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
free(a);
printf("打开⽂件%s失败\n", file);
exit(-1);
}
for (int j = 0; j < i; j++)
fprintf(fin, "%d\n", a[j]); //写一个数据,换一行
free(a);
fclose(fin);
return i;
}
// MergeSortFile的第二个是每次取多少个数据到内存中排序,然后写到⼀个⼩⽂件进⾏归并
// 这个n给多少取决于我们有多少合理的内存可以利⽤,相对⽽⾔n越⼤,更多数据到内存中排序后,
// 再走文件归并排序,整体程序会越快⼀些。
void MergeSortFile(const char* file, int n)
{
//3个辅助文件·文件名
const char* file1 = "file1";
const char* file2 = "file2";
const char* mfile = "mfile";
//打开源文件
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
printf("打开⽂件%s失败\n", file);
exit(-1);
}
int i = 0;
int x = 0;
// 分割成⼀段⼀段数据,内存排序后写到,⼩⽂件,
//int* a = (int*)malloc(sizeof(int) * n);
//if (a == NULL)
//{
// perror("malloc fail");
// return;
//}
// 分别读取前n个数据排序后,写到file1和file2⽂件
//ReadNDataSortToFile(fout, a, n, file1);
//ReadNDataSortToFile(fout, a, n, file2);
// 在ReadNDataSortToFile里面创建数组也是一样的
ReadNDataSortToFile(fout, n, file1);
ReadNDataSortToFile(fout, n, file2);
while (1)
{
// 归并:把file1和file2⽂件归并到mfile⽂件中
MergeFile(file1, file2, mfile);
// 删除file1和file2
//remove(file1)
//remove(file2)
// 规范化编程:
if (remove(file1) != 0 || remove(file2) != 0)
{
perror("Error deleting file");
return;
}
// 将mfile重命名为file1
//rename(mfile, file1)
// 规范化编程:
if (rename(mfile, file1) != 0)
{
perror("Error renaming file");
return;
}
// 读取N个数据到file2,继续⾛归并
// 如果⼀个数据都没读到,则归并结束了
if (ReadNNumSortToFile(fout, a, n, file2) == 0)
break;
}
printf("%s⽂件成功排序到%s\n", file, file1);
fclose(fout);
//free(a); 被调函数内自己创建、自己使用、自己释放,就不需要主调函数创建+传参+释放
}
// 创建N个随机数,写到⽂件中
void CreateNDate()
{
// 造数据
int n = 1000000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = rand() + i;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
int main()
{
//CreateNDate();
MergeSortFile("data.txt", 100000);
return 0;
}