一、前言
在进行项目开发中,我们为了提高接口的性能,通常会上缓存,不管是本地缓存还是分布式缓存。使用缓存确实能提高我们接口的响应速度,但是怎么保证缓存和数据库的一致性又是我们比较关注的一个点。因为缓存数据不一致,最直接的结果是会导致业务逻辑错误,这是我们不能接受的。
二、缓存与数据库不一致的场景
1. 数据库操作成功,缓存操作失败
数据库的操作和缓存的操作是存在一定的时间差,比如删除一条数据时,通常是先在数据库中删除,然后再缓存中删除。这两个操作是没有办法保证原子性的,也就是有可能一个操作成功,一个操作失败。这样必然会存在不一致的情况。
2.两个线程同时写数据库,然后更新缓存(写-写并发)
| 线程1 | 线程2 |
|---|---|
| 更新数据库,更新为10 | |
| 更新数据库,更新为60 | |
| 更新缓存,更新成60 | |
| 更新缓存,更新成10(出现不一致) |
3. 一个线程读数据,写缓存,一个线程写数据,更新缓存(读-写并发)
这种场景下,读线程先查缓存,发现没有,然后去读数据库,然后把数据写到缓存中。这期间可能有一个写线程,更新了数据库和缓存。
| 读线程 | 写线程 |
|---|---|
| 读缓存,缓存中没有数据 | |
| 读数据库,读到的结果为30 | |
| 更新数据库和缓存,更新为10 | |
| 写缓存,更新为30(出现不一致) |
三、如何解决不一致的问题
为了保证数据库和缓存的一致性,首先是要数据库和缓存的双写,再配合上一下过期策略,定期清空缓存中的数据,然后去加载最新的数据。
下面是常用的解决缓存不一致的方案:
1.设置缓存过期时间
非热点数据,我们需要设置过期时间,通过设置缓存的过期时间,可以减少缓存和数据库不一致的时间窗口。缓存过期后,从数据库重新加载最新的数据,确保数据的新鲜度和准确性。
2.先更新数据库后删除缓存--并发不高
在更新数据的时候最简单的处理方式是删除缓存。有很多是更新缓存,更新缓存也可以,但不是最优的选择。因为,很多场景下缓存中不仅仅是一个简单的字符串,有可能是一个复杂的数据结构(JSON或Map)。
如果是更新的化,需要先把缓存查出来,进行反序列化,然后取出其中一个字段进行更新,再进行序列化,最后再更新到缓存中去。可以看到更新是很复杂的,也容易出错。另外一方面,如果两个线程同时更新,可能会出现不一致的情况。所以说,删除缓存是最优的选择。
3.延迟双删--高并发场景
所谓的延迟双删,是先删除缓存,再更新数据库,最后再删一次数据库。
对比上面的方案,在更新数据库之前多了一次删除缓存。那么为什么要多一次删除缓存?
这是因为数据库的操作和缓存的操作不是一个原子操作,可能会存在失败的情况。如果缓存删除成功了,数据库更新成功没有问题,可能会增加cache miss,但是如果数据库更新成功,而缓存删除失败了,就会产生不一致的情况。高并发场景下,其它的线程来读取的都是脏数据,不是最新的数据。
所以,第一次删除缓存,是为了避免缓存和数据库操作不能作为一个原子操作,而带来的不一致的问题,可能产生脏读的问题。
那么为什么第二次删除需要延迟删除呢?
其实在高并发场景下,我们先删除了缓存,会放大前面提到的读写并发导致不一致的场景。就是写线程删除缓存后,又被一个读线程写入旧值了。那么我们就需要在写线程删缓存,写数据库后,延迟一段时间再删除一次缓存,来解决这个问题。一般延迟1~2s删除即可。
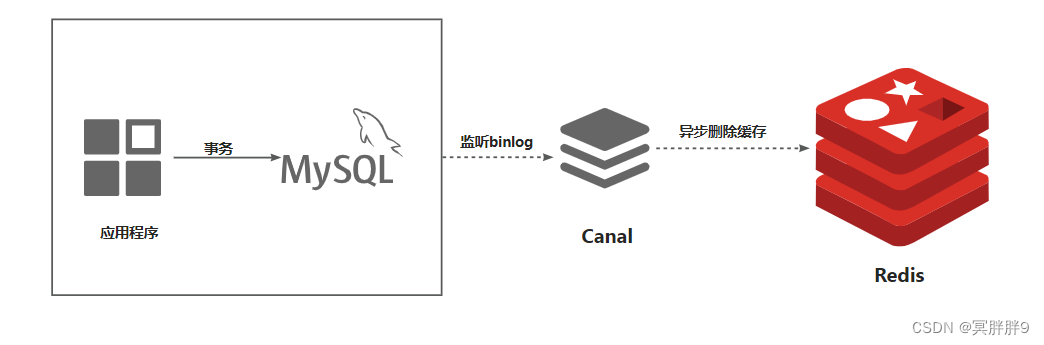
4.监听数据库binlog,异步删除缓存
前面几种方案,在我们的业务代码中会耦合很多删除缓存的逻辑,使得我们维护变得困难,也会降低我们系统的吞吐量和响应速度。
所以,这种方案在代码中只会有我们的业务逻辑,不用关心缓存的清理,可以提高系统的性能 。但是,这种方案是异步删除缓存的,通常是监听到binglog发生变化,然后使用消息中间件发送消息,有一个应用监听消息去删除对应的缓存。异步就意味着会有一定的延迟,我们需要评估能不能接受一定的延迟。