一、关系型表和流处理表对比
| 关系型表/SQL | 流处理表 | |
|---|---|---|
| 处理的数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询(Query)对数据的访问 | 可以访问到完整的数据输入 | 无法访问所有数据,必须持续"等待"流式输入 |
| 查询终止条件 | 生成固定大小的结果集后终止 | 永不停止,根据持续收到的数据不断更新查询结果 |
二、动态表
- 当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的 SQL 查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为"动态表"(Dynamic Tables)
- 动态表是 Flink 在 T able API 和 SQL 中的核心概念,它为流数据处理提供了表和 SQL 支持。关系型表一般用来做批处理,面向的是固定的数据集,可以认为是"静态表";而动态表则完全不同,它里面的数据会随时间变化
三、持续查询

-
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的 SQL 查询也不可能执行一次就得到最终结果,所以对动态表的查询就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作"持续查询"(Continuous Query)
-
动态表查询的处理过程:
-
流(stream)被转换为动态表(dynamic table)
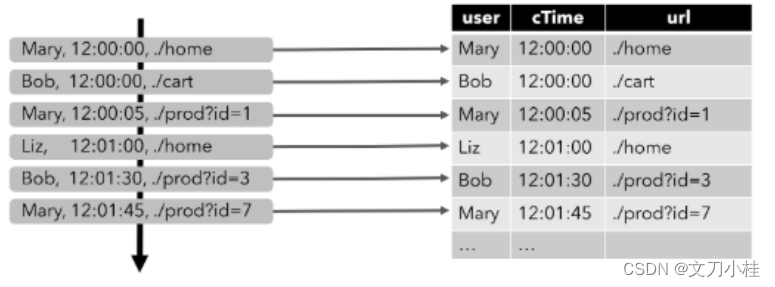
-
对动态表进行持续查询(continuous query),生成新的动态表
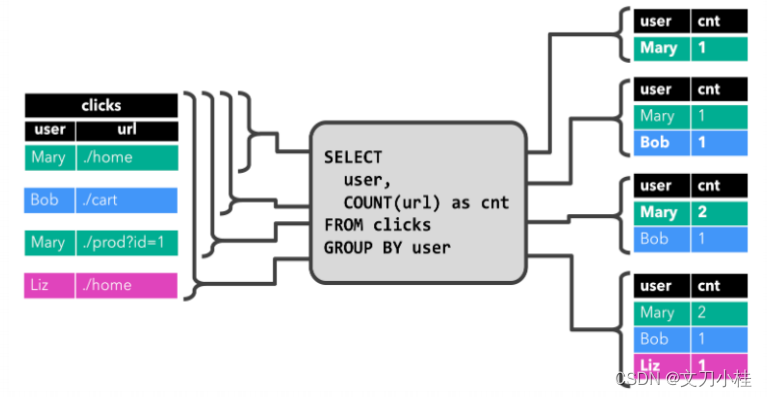
-
生成的动态表被转换成流
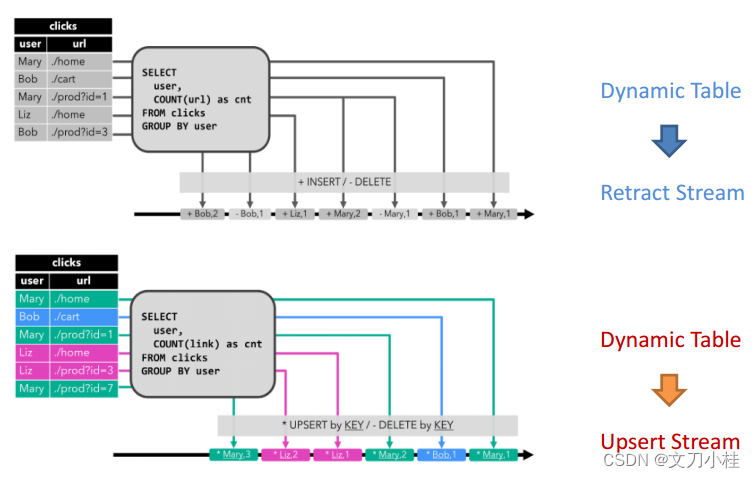
-