目录
[1.1 数据库是什么](#1.1 数据库是什么)
[1.2 为什么要有数据库](#1.2 为什么要有数据库)
[1.3 主流数据库](#1.3 主流数据库)
一、数据库的概念
1.1 数据库是什么
数据库(Database)一般指在磁盘或内存中按照数据结构来组织、存储和管理数据的计算机软件系统,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
1.2 为什么要有数据库
一般的文件确实提供了数据的存储功能,但是并没有提供非常好的数据内容管理能力。这使得程序员如果使用一般的文件来存储数据,那么则需要手动实现各种功能来进行数据管理。
用文件保存数据有以下几个缺点:
- 安全性无法保证
- 不便数据查询和管理
- 在程序中控制不方便
- 不利于存储海量数据
为了解决这些问题,数据库出现了。
数据库是一套对数据内容存储的解决方案,能够更加有效的管理数据。而MySQL作为最流行的关系型数据库,能够为我们提供各种数据存取的服务。
1.3 主流数据库
目前市面上主流的数据库有:
- SQL Server:微软的产品,适合中大型项目
- Oracle:甲骨文的产品,适合大型项目,业务逻辑复杂
- MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,主要用于电商、SNS、论坛,性能出色
- PostgreSQL:加州大学伯克利分校计算机系开发的关系型数据库,可以免费使用和修改
- SQLite:一款轻型数据库,是遵循ACID的关系型数据库管理系统,包含在一个相对小的C库中。主要用于嵌入式产品,占用资源非常低
- H2:用Java开发的嵌入式数据库,可以直接嵌入到应用项目中
前面提到,MySQL属于关系型数据库,这类数据库中表的结构遵循行列式结构
NoSQL(Not Only SQL)泛指非关系型数据库,例如redis、MongoDB等,基本都是内存级别的数据库,作为数据存储的中间件使用。
NoSQL出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。每个数据库都在自己的领域发挥不同的作用,例如redis在数据缓存领域经常被采用。
现在的主流后端存储服务基本是以MySQL为主,NoSQL为辅搭建的
二、在Linux中使用MySQL
对MySQL有了基本的了解后,我们尝试使用MySQL,建立数据库和表结构,再插入一些数据
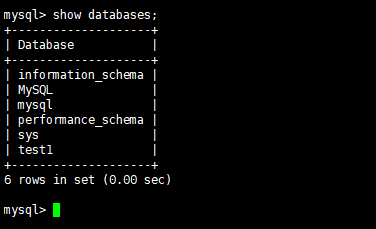
(1)查看当前服务器的数据库
登入MySQL后输入*show databases;*即可查看当前服务器有哪些数据库
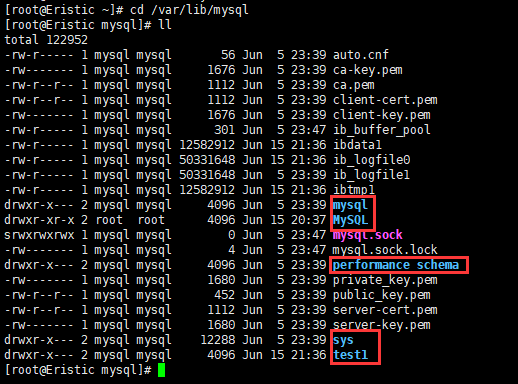
这些数据库都存放在配置文件的默认保存路径当中,输入vim /etc/my.cnf 即可打开配置文件

进入该路径,查看当前路径下的所有文件
(2)建立数据库
输入 create database 库名; 即可创建一个数据库

再次查看存储目录中的文件:
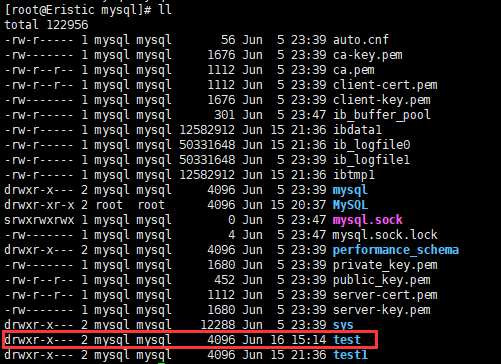
可以看到这个就是我们刚刚创建出来的数据库
所以这些数据库本质就是Linux下的一个目录
(3)建立表结构
要想在一个数据库中建立表结构,首先得进入这个数据库
输入 use 库名; 进入该数据库

输入 create table 表名(列名1 元素类型, 列名2 元素类型......); 即可创建一张指定结构的数据库表
然后输入 show tables; 即可查询当前数据库中有哪些表结构
例如:

观察之前Linux下的目录,可以发现:
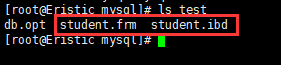
所以在数据库中建表,本质就是在Linux下创建对应的文件
数据库本质都是文件,只不过这些文件不由程序员直接操作,而是由数据库服务帮我们进行操作
(4)向表中插入数据
输入 insert into 表名(列名1,列名2...) values(数据1,数据2...); 即可向表中插入数据
例如:

输入 select * from 表名; 即可查看表中的所有数据
例如:

三、MySQL架构
MySQL是一个开源的可移植数据库,几乎能在当前所有的操作系统上运行,如Unix/Linux、Windows、Mac、Solaris。
虽然各种系统在底层实现方面各有不同,但是MySQL基本能保证在各个平台上的物理体系结构的一致性。其架构示意图如下:
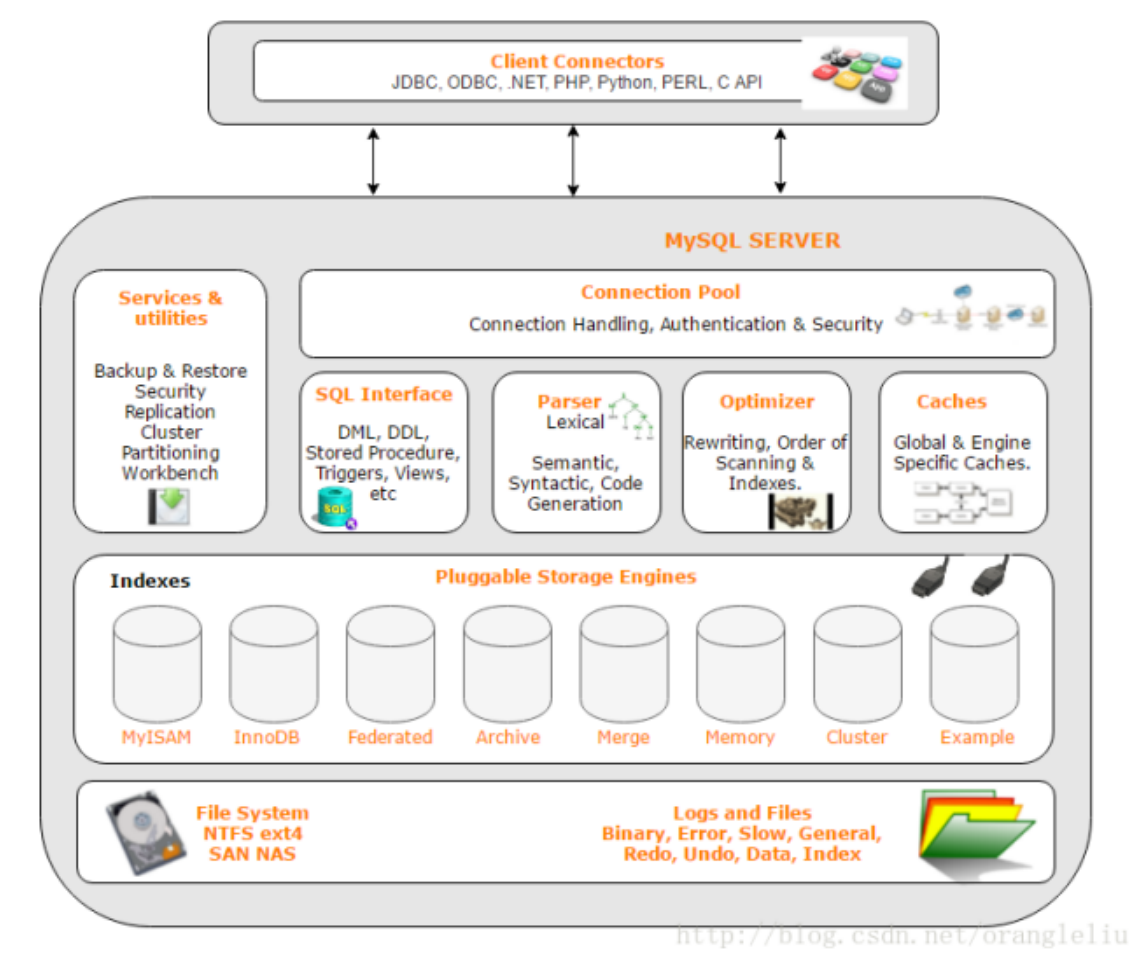
Client Connectors:MySQL的客户端,我们目前用的是命令行式的二进制程序,后面还可以用C++语言直接连接MySQL或者用MySQL的图形化界面来访问
MySQL SERVER的主要功能分为三层:
第一层(链接池),帮助我们进行链接管理和鉴别用户合法身份等
中间层可以对我们下达的SQL指令进行语法分析、词法分析和优化,并按照协议传达给下一层
第三层对应一个个存储引擎,作用有点像计算机中的驱动。从上层接收处理后的语句,然后访问指定的数据库、文件和表结构,对数据进行增删查改
因为数据有种类的差别,有文档型的、二进制型的等等,针对不同种类的数据需要不同的存储方案,所以需要多种存储引擎
例如MyISAM比较适合对大文本进行读取,InnoDB有很丰富的索引支持,方便我们进行快速的搜索查找。这两个也是最常用的两个引擎
最底下依赖的就是对应的文件系统,把数据以二进制的形式存储到特定的目录下,构建特定的普通文件
所以MySQL是处于操作系统提供的文件系统之上的一套存储解决方案。
四、SQL语句分类
用户在数据库上执行的大部分工作都由 SQL 语句完成,例如我们之前建库、建表、插入数据时使用的SQL语句
SQL语句主要分为五类:
- DDL(Data Definition Language):数据定义语言,用来维护存储数据的结构,例如create,drop,alter
- DML(Data Manipulation Language):数据操纵语言,用来对数据进行操作,例如insert,delete,update
- DQL(Data Query Language):数据查询语言,例如select
- DCL(Data Control Language):数据控制语言,主要负责权限管理和事务,例如grant,revoke,commit,rollback
五、存储引擎
存储引擎是数据库管理系统如何存储数据、如何为存储的数据建立索引以及如何更新、查询数据的实现方法。
MySQL的核心就是插件式存储引擎,这些存储引擎位于最底层,负责与操作系统进行交互。
要查看有哪些存储引擎,可以输入 show engines;
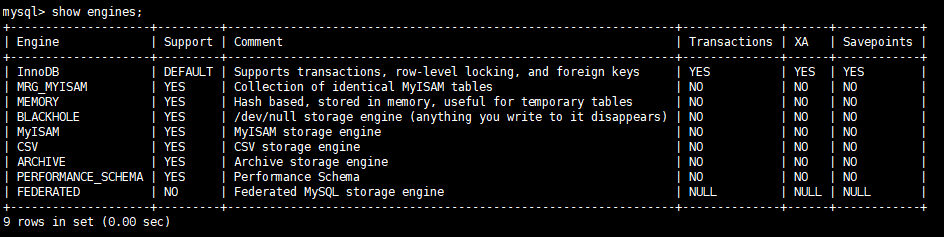
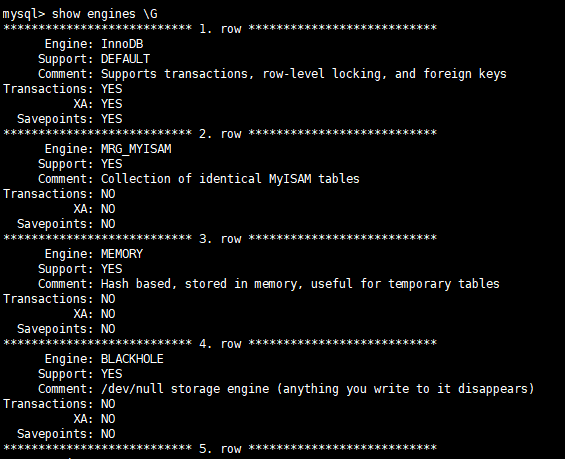
或者 show engines \G
完.