一、SQL 优化
1. 插入数据
(1) 普通插入
① 采用批量插入(一次插入的数据不建议超过1000条)
sql
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');② 手动提交事务
sql
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;③ 主键顺序插入
sql
主键乱序插入:8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入:1 2 3 4 5 7 8 9 15 21 88 89(2) 大批量插入:
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令插入。
bash
# 客户端连接服务端时,加上参数 --local-infile(这一行在bash/cmd界面输入)
mysql --local-infile -u root -p
# 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
select @@local_infile;
# 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/load_user_100w_sort.sql' into table tb_user fields terminated by ',' lines terminated by '\n';2. 主键优化
(1) 数据组织方式:
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(Index organized table, IOT)
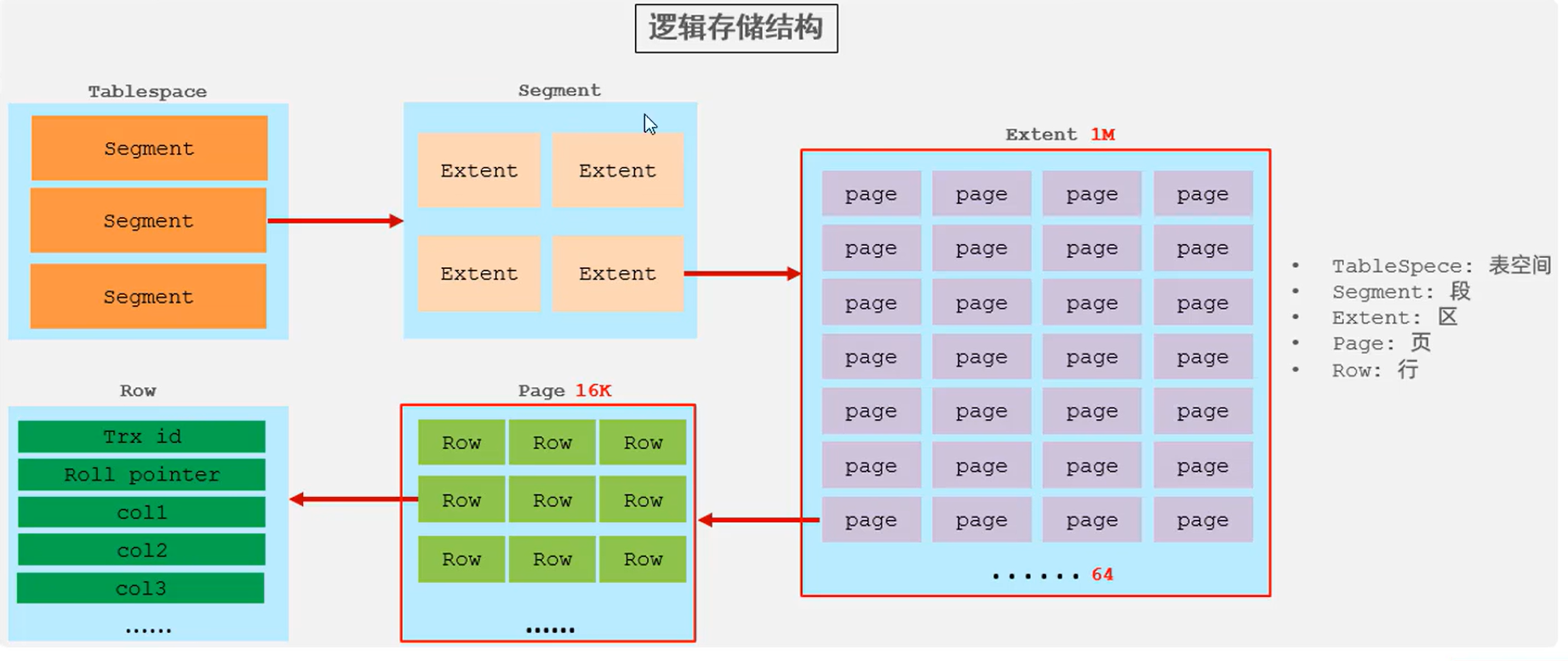
数据库的存储是:
表空间(Tablespace) → 段(Segment) → 区(Extent) → 页(Page) → 行(Row)
(2) 页分裂:
页可以为空,也可以填充一半,也可以填充100%,每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
① 触发场景:当你往表中插入数据时,InnoDB 会把数据存到对应的页里。如果当前页已经没有足够空间存新行(比如页的使用率快满了),就会触发 "页分裂"。
② 典型过程(以非自增主键插入为例)
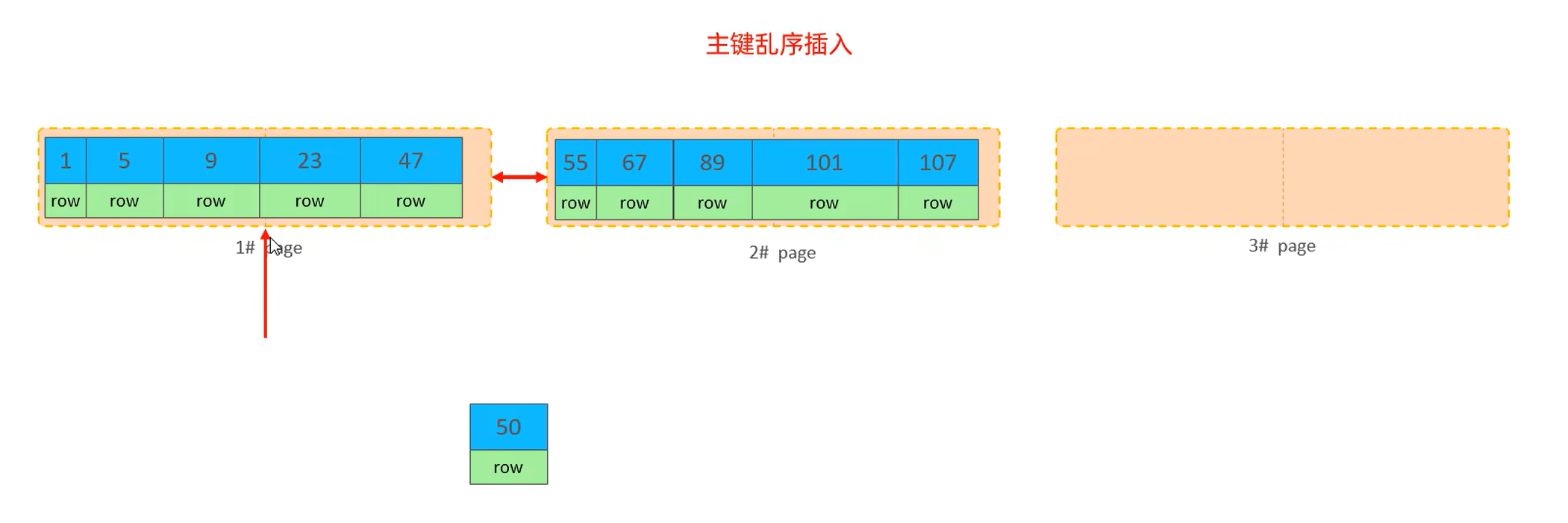
步骤 1:插入前的页状态
- 1# 页:存了主键
1、5、9、23、47的 5 条数据(页已经快存满了); - 2# 页:存了主键
55、67、89、101、107的 5 条数据; - 现在要插入 主键 = 50 的新行。
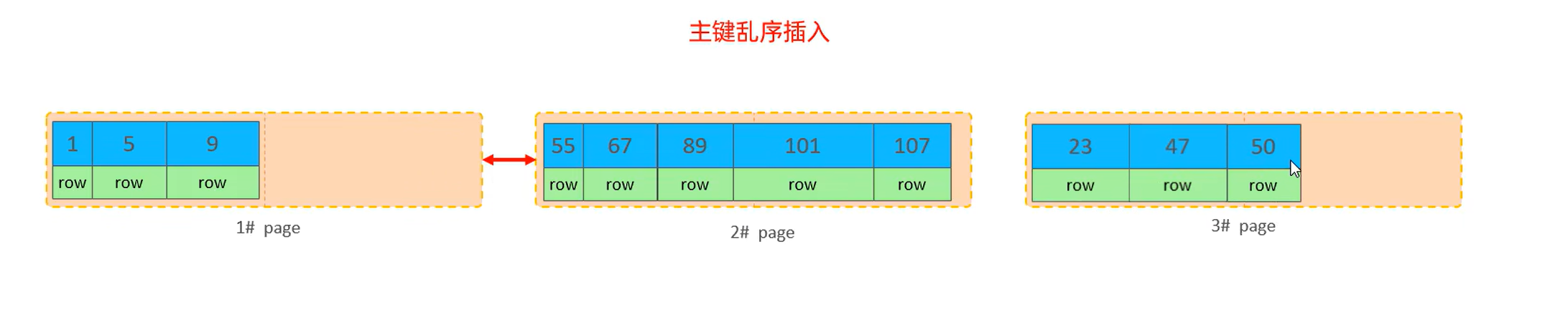
步骤 2:插入时的 "位置冲突"
主键是有序存储的,50 的大小介于 1# 页的最大主键(47)和 2# 页的最小主键(55)之间,所以50 应该存在 1# 和 2# 页之间。
但问题是:1# 页已经快存满了,没有空间放 50 这条新数据 → 触发页分裂。
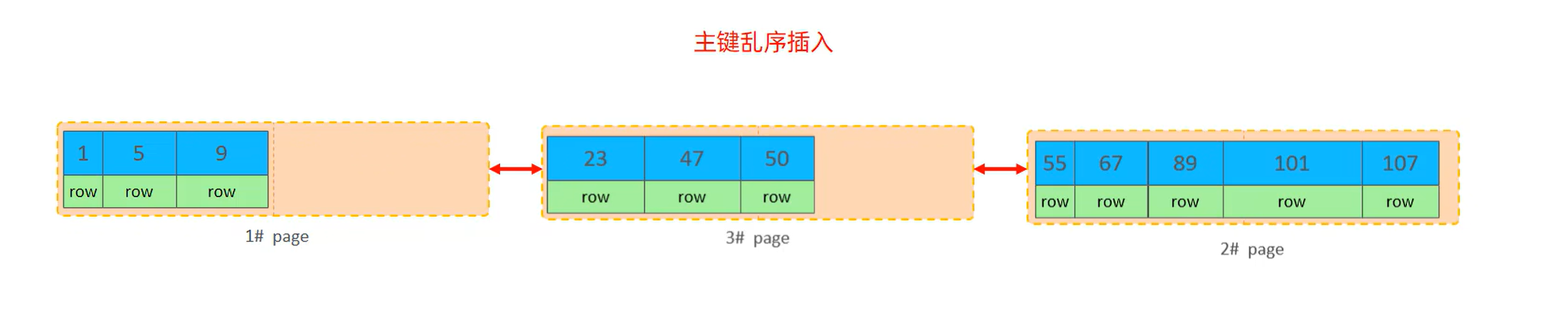
步骤 3:页分裂后的结果
分裂后:
- 1# 页:把原来的部分数据(23、47)移出去,只留
1、5、9; - 新建 3# 页:把移出的 23、47,加上新插入的 50,存在 3# 页(主键
23、47、50); - 2# 页:保持原来的
55、67、89、101、107不变。
(3) 页合并:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。当页中删除的记录到达 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前后)看看是否可以将这两个页合并以优化空间使用。
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或创建索引时指定
(4) 主键设计原则:
- 满足业务需求的情况下,尽量降低主键的长度。主键越长,每个 "索引页(Page)" 能存的主键数量就越少 → 索引树的层数会变多
- 插入数据时,尽量选择顺序插入,选择使用 AUTO_INCREMENT 自增主键
- 尽量不要使用 UUID 做主键或者是其他的自然主键,如身份证号。UUID 是随机生成的,插入时会像之前 "插入 50" 那样,随机插在页的中间位置 → 频繁触发页分裂,既耗性能又产生碎片;
- 业务操作时,避免对主键的修改
3. order by 优化
(1) Using filesort:
通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序
(2) Using index:
通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高
(3) 如果order by字段全部使用升序排序或者降序排序,则都会走索引,但是如果一个字段升序排序,另一个字段降序排序,则不会走索引,explain的extra信息显示的是Using index, Using filesort,如果要优化掉Using filesort,则需要另外再创建一个索引,如:create index idx_user_age_phone_ad on tb_user(age asc, phone desc);,此时使用select id, age, phone from tb_user order by age asc, phone desc;会全部走索引
sql
-- 创建索引
create index idx_user_age_phone on tb_user(age,phone);
-- 走索引
explain select id, age, phone from tb_user order by age desc, phone desc;
-- 不走索引,因为索引是 "先age,后phone" 排序的,而 order by 是 "先phone,后age"
explain select id, age, phone from tb_user order by phone, age;
-- 不走索引
explain select id, age, phone from tb_user order by age, phone desc;
-- 创建新的索引后,上面那句走索引
create index idx_user_age_pho_ad on tb_user(age asc, phone desc);(4) 总结:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则
- 尽量使用覆盖索引
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)
- 如果不可避免出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)
4. group by优化
(1) 在分组操作时,可以通过索引来提高效率
(2) 分组操作时,索引的使用也是遵循最左前缀法则的
sql
-- 创建索引
create index idx_user_pro_age_sta on tb_user(profession,age,status);
-- 走索引
explain select profession, count(*) from tb_user group by profession;
-- 不走索引,不满足最左前缀法则
explain select age, count(*) from tb_user group by age;
-- 走索引
explain select profession, age, count(*) from tb_user group by profession, age;
-- 走索引
explain select profession, age, count(*) from tb_user where profession = '软件工程' group by age;如索引为idx_user_pro_age_stat,则句式可以是select ... where profession order by age,这样也符合最左前缀法则
5. limit优化
(1) 常见的问题:
如limit 2000000, 10,此时需要 MySQL 排序前2000000条记录,但仅仅返回2000000 - 2000010的记录,其他记录丢弃,查询排序的代价非常大。
(2) 优化方案:
一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
(3) 例如:
sql
- 此语句耗时很长
select * from tb_sku limit 9000000, 10;
-- 通过覆盖索引加快速度,直接通过主键索引进行排序及查询
select id from tb_sku order by id limit 9000000, 10;
-- 下面的语句是错误的,因为 MySQL 不支持 in 里面使用 limit
-- select * from tb_sku where id in (select id from tb_sku order by id limit 9000000, 10);
-- 通过连表查询即可实现第一句的效果,并且能达到第二句的速度
select * from tb_sku as s, (select id from tb_sku order by id limit 9000000, 10) as a where s.id = a.id;4. count优化
(1) MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高(前提是不适用where);
(2) InnoDB 在执行 count(*) 时,需要把数据一行一行地从引擎里面读出来,然后累计计数。
(3) 优化方案:自己计数,如创建key-value表存储在内存或硬盘,或者是用redis
(4) count 的几种用法:
① 如果 count 函数的参数(count里面写的那个字段)不是NULL(字段值不为NULL),累计值就加一,最后返回累计值
② 用法:count(*)、count(主键)、count(字段)、count(1)
③ count(主键) 跟 count(*) 一样,因为主键不能为空;count(字段) 只计算字段值不为NULL的行;count(1)引擎会为每行添加一个1,然后就count这个1,返回结果也跟count(*)一样;count(null)返回0
(5) 各种用法的性能:
① count(主键):InnoDB引擎会遍历整张表,把每行的主键id值都取出来,返回给服务层,服务层拿到主键后,直接按行进行累加(主键不可能为空)
② count(字段):没有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加;有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加
③ count(1):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一层,放一个数字 1 进去,直接按行进行累加
④ count(*):InnoDB 引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加
按效率排序:count(字段) < count(主键) < count(1) < count(*),所以尽量使用 count(*)
5. update优化(避免行锁升级为表锁)
(1) InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
(2) 案例:
sql
-- 这句由于id有主键索引,所以只会锁这一行
update student set no = '123' where id = 1;
-- 这句由于name没有索引,所以会把整张表都锁住进行数据更新,解决方法是给name字段添加索引
update student set no = '123' where name = 'test';二、视图
1. 介绍
(1) 视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
(2) 通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
2. 语法
(1) 创建视图:
sql
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION(2) 查询视图:
① 查看创建视图语句:
sql
SHOW CRETE VIEW 视图名称;② 查看视图数据:
sql
SELECT * FROM 视图名称...;(3) 修改视图:
① 方式一:
sql
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION② 方式二:
sql
ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [WITH[CASCADED | LOCAL] CHECK OPTION](4) 删除视图:
sql
DROP VIEW [IF EXISTS]视图名称 [,视图名称](5) 案例:
sql
-- 创建视图
create or replace view stu_v_1 as select id, name from student where id <= 10;
-- 查询视图
show create view stu_v_1;
select * from stu_v_1;
-- 修改视图
create or replace view stu_v_1 as select id, name, no from student where id <= 10;
alter view stu_v_1 as select id, name from student where id <= 10;
-- 删除视图
drop view if exists stu_v_1;3. 检查选项
(1) 视图的检查选项:
① 当使用 WITH CHECK OPTION 子句创建视图时,MySQL 会通过视图检查正在更改的每个行,例如:插入,更新,删除,以使其符合视图的定义。MySQL 允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。
② 为了确定检查的范围,mysql 提供了两个选项:CASCADED 和 LOCAL,默认值为CASCADED。
- cascaded: 在对创建时含有该字段的视图,插入数据时,该视图依赖的视图都会加上检查,需要所有条件都满足才能够插入成功。
- local: 在对创建时含有该字段的视图,插入数据时,对于该视图依赖的视图中含有检查语句的条件进行检查判断。
(2) with cascaded check option 的案例:
sql
-- 创建视图,但不加 with check option
create or replace view stu_v_1 as select id, name from student where id <= 20;
-- 插入成功,会存入基表中(基表无约束),而且会显示在stu_v1视图中
insert into stu_v_1 values(5,'Tom');
-- 插入成功,虽然id=25不满足stu_v1的id <=20,但插入操作会成功(数据会存入student基表,但不会显示在stu_v1视图中),插入成功。
insert into stu_v_1 values(25,'Tom');
create or replace view stu_v_2 as select id, name from stu_v_1 where id >= 10 with cascaded check option;
-- 插入失败,因为不满足stu_v_2的条件:id >= 10
insert into stu_v_2 values(7,'Tom');
-- 插入失败,因为不满足基表stu_v1的条件:id <= 20
insert into stu_v_2 values(26,'Tom');
-- 插入成功
insert into stu_v_1 values(8,'Tom');① 向无WITH CHECK OPTION的视图 插入数据时,只要满足基表(student)的约束,插入会成功(但不满足视图筛选条件的行,不会显示在视图中)。
② 向有WITH CHECK OPTION的视图 插入数据时,必须满足当前视图 + 所有底层视图的筛选条件 (cascaded是级联检查所有底层视图),否则插入失败。
(3) with local check option 的案例:
sql
-- 创建视图
create or replace view stu_v_4 as select id, name from student where id <= 15 with local check option;
-- 插入成功,id = 5 满足 stu_v4 的 id <= 15,数据存入基表并且会显示在 stu_v4 中
insert into stu_v_4 values(5,'Tom');
-- 插入失败,16 > 15 不满足 stu_v_4 的 Local 约束,会被直接拦截
insert into stu_v_4 values(16,'Tom');
create or replace view stu_v_5 as select id, name from stu_v_4 where id >= 10 with local check option;
-- 插入成功
insert into stu_v_5 values (13,'Tom');
-- 插入失败,因为不满足 stu_v_4 的约束 id <= 15
insert into stu_v_5 values (17,'Tom');
insert into stu_v_5 values (18,'Tom');
create or replace view stu_v_6 as select id, name from stu_v_5 where id < 20;
-- 插入成功,stu_v_6 无 check option,但插入会触发底层的 stu_v_5 的 local 约束
-- 14 >= 10 满足 stu_v_5 的条件,14 <= 15 满足 stu_v_4 的条件
insert into stu_v_6 values (14,'Tom');(4) 总结
① 没有 CHECK OPTION:不会检查当前视图的WHERE条件,即使数据不满足该条件,也能成功存入基表 ;但后续查询该视图时,这条不满足条件的数据不会在视图结果中显示
② 有 check option:会按LOCAL/CASCADED的规则检查对应范围的WHERE条件(当前视图 / 底层视图),不满足条件则插入 / 更新操作直接失败,数据既不会存入基表,自然也不会在视图中显示
4. 更新及作用
(1) 视图的更新:
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系 。如果视图包含以下任何一项,则该视图不可更新:
- 聚合函数或窗口函数(SUM()、MIN()、MAX()、COUNT()等
- DISTINCT
- GROUP BY
- HAVINGA
- UNION 或者 UNION ALL
(2) 作用:
**① 简单:**视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
**② 安全:**数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见到的数据。
**③ 数据独立:**视图可帮助用户屏蔽真实表结构变化带来的影响。
(3) 案例:
sql
-- 1.为了保证数据库表的安全性,开发人员在操作tb_user表时,只能看到的用户的基本字段,屏蔽手机号和邮箱两个字段。
create view tb user view as select id,name,profession, age,gender,status,createtime from tb_user;
select *from tb user view;
-- 2.查询每个学生所选修的课程(三张表联查),这个功能在很多的业务中都有使用到,为了简化操作,定义一个视图。
create view tb_stu_course_view
select s.name student_name, s.no student_no, c.name course_name
from student s, stuent_course sc, course c
where s.id = sc.studentid and sc.courseid = c.id;
-- 以后每次只需要进行查询视图即可
select * from tb_stu_course_view;