
超万卡训练集群互联关键技术
****

大模型迈向万亿参数的多模态升级,万卡集群计算能力亟需飞跃。关键在于增强单芯片性能、提升超节点算力、融合DPU多计算能力,并追求算力能效比极致。这一系列提升将强有力支撑更大规模模型训练和推理,快速响应业务需求,推动技术进步。
InfiniBand与RoCE对比分析:AI数据中心网络选择指南
1、单芯片能力
超万卡集群中,单芯片能力包括单个GPU的计算性能和GPU显存的访问性能。在单个GPU计算性能方面,首先需要设计先进的GPU处理器,在功耗允许条件下,研发单GPU更多并行处理核心,努力提高运行频率。
其次,通过优化高速缓存设计,减少GPU访问内存延迟,进一步提升单GPU芯片运行效率。第三,优化浮点数表示格式,探索从FP16到FP8浮点数的表示格式,通过在芯片中引入新的存储方式和精度,在保持一定精度条件下,大幅提升计算性能。
最后,针对特定计算任务,可在GPU芯片上集成定制化的硬件加速逻辑单元,这种基于DSA(DomainSpecificArchitecture)的并行计算设计,可提升某些特定业务领域的计算速度。
为高效布放万亿模型数据于数万张GPU显存,需显存具备高带宽、大容量特性,确保计算单元高效访存、系统低能耗运行。推荐采用2.5D/3D堆叠的HBM技术,以缩短数据传输距离,降低访存延迟,显著提升GPU计算单元与显存的互联效率,从而优化GPU显存访问性能。
超万卡集群技术为智算中心提供卓越的单卡算力,为更大规模的模型训练和推理任务奠定坚实硬件基石,展现无限潜力。
2、超节点计算能力
针对万亿模型训练与推理,特别是在超长序列和MoE架构下,应着重提升巨量参数与数据样本的计算效率,满足All2All通信模式下的GPU卡间通信需求。建议超万卡集群改进策略聚焦在优化计算效率、增强GPU间通信能力等领域。
●加速推进超越单机8卡的超节点形态服务器
为应对万亿级参数量模型部署挑战,产业界应研发突破8卡限制的超节点服务器。通过增强GPU南向互联能力,提升张量并行与MoE并行效率,大幅缩短训练时长,实现大模型训练性能的整体优化,助力产业迈向新高度。
●加快引入面向Scale up的Switch芯片
建议在节点内集成支持Scale up的Switch芯片,以强化GPU南向互联效率和规模,提升张量并行与MoE并行的数据传输能力。如图2,集成Switch芯片能显著增强GPU间的P2P带宽,优化网络传输效率,满足大模型对GPU互联和带宽的高需求,为大规模并行计算提供坚实的硬件基础。

●优化GPU卡间互联协议
为提升通信效率,建议对GPU卡间互联协议进行全面优化与重构,特别是在All2All模式下。通过革新数据报文格式、引入CPO/NPO技术、强化SerDes传输速率、优化拥塞控制及重传机制,并结合多异构芯片C2C封装,大幅提升超万卡集群的GPU互联网络效率。此举将显著减少通信时延,实现带宽能力的质的飞跃,满足高频次、大带宽、低延迟的通信需求。
3、多计算能力融合
面对超万卡集群,智算中心数据交换需求激增,传统CPU处理网络数据效率低下且成本高昂。为提升效率,智算中心计算架构正转向DPU。DPU具备层级化可编程、低时延网络和统一管控特性,可卸载CPU、GPU中的数据处理任务,大幅扩展节点间算力连接,释放CPU、GPU算力,降低协作成本,从而发挥集群最大效能。
智算中心软硬一体化重构,构建计算、存储、网络、安全、管控五大引擎,标准化DPU片上驱动内核,引领未来计算新纪元。
计算引擎卸载优化I/O设备,加速数据与控制路径,节点标准化支持virtio-net和virtio-blk后端接口,实现设备驱动的通用化,摆脱厂商专用驱动的束缚,确保高效稳定的计算体验。
存储引擎在DPU上实现存储后端接口,支持TCP/IP及RDMA网络功能,无缝连接块、对象、文件存储集群。这一创新设计将全类型存储任务卸载至DPU,大幅提升存储效率,为数据处理提供强劲支撑。
网络引擎将虚拟交换机卸载至DPU,通过标准流表和卸载接口,实现网络流量高效卸载,全面释放硬件性能。集成RDMA网络功能,显著降低多机多卡间通信时延,将多机间通信带宽提升至400G,构建节点间数据交换的"极速通道"。
安全引擎运用信任根与IPsec等加密协议,为系统和多租户网络提供强大防护,同时依托DPU实现高效卸载方案,确保数据安全无忧。
中国移动自2020年起,基于五大引擎蓝图,倾力打造自主知识产权的磐石DPU,并于2021年正式发布。经过移动云现网的精心打磨,我们持续升级磐石DPU,至2024年全面升级为ASIC架构。此举旨在通过软硬融合重构算力基础设施,重塑云计算技术新标准,引领算力时代技术革新,塑造新技术未来曲线。
融入磐石DPU芯片至智算中心,升级至CPU+GPU+DPU三平台支撑,将有效连接集群节点间的算力孤岛,突破技术架构的集群规模极限,实现超万卡集群的构建,为算力发展带来革命性突破。
4、极致算力能效比
制程工艺固定下,高性能芯片功耗上升,影响散热。面对功率密度激增,需同步优化制冷系统与GPU芯片,确保高效散热与稳定运行。
制冷系统挑战重重,8卡GPU服务器功耗远超通用型。面对GPU散热剧增,为提升计算密度与空间效率,超万卡集群宜采用高密度冷板式液冷机柜。一柜多机,空间利用率飞跃提升,远超传统风冷,是高效节能的明智之选。
在GPU芯片方面,为了提升GPU单芯片的能效比,应采取多领域的优化策略,实现高性能与低能耗之间的平衡。在芯片工艺领域,建议采用更加先进的半导体制造工艺,如7nm或更小的特征尺寸,以此降低晶体管的功耗,同时提升单芯片集成度。此外,应加强超万卡集群内GPU架构的创新设计,包括优化片上总线设计、改进流水线结构、优化电压和频率策略以及精确的时钟门控技术,从而在不同工作状态下实现最优的能耗效率。
在软件层面,超万卡集群应采用更加精细的监控和分析,实时跟踪GPU的运行数据,并不断优化算法和工作负载分配,以实现更加均衡和高效的算力利用。通过上述设计和优化,不仅能提高用户的计算体验,降低成本,也为智算中心可持续发展和绿色环保提出了可行方案。
5、高性能融合存储技术
超万卡集群应用多协议融合与自动分级存储技术,优化存储空间利用与数据流动,大幅提升智算数据处理效率,支持集群大规模扩展,赋能千亿至万亿级大模型训练,实现智算巅峰性能。
6、多协议融合
超万卡集群融合存储底座承载Al全流程业务数据处理,兼容Al全流程工具链所需的NFS(Network File System)、S3(Sample Storage Service)和并行客户端POSIX(Portable Operating System Interface)等协议,支持各协议语义无损,达到与原生协议一样的生态兼容性要求,在不同阶段实现数据零拷贝和格式零转换,确保前一阶段的输出可以作为后一阶段的输入,实现Al各阶段协同业务的无缝对接,达到"零等待"效果,显著提升大模型训练效率。
7、集群高吞吐性能
为满足超万卡集群大模型对高吞吐存储需求,我们采用全局文件系统技术,支持超3000节点扩展,提供百PB级全闪存储集群。通过优化闪存密度、网络、客户端和通信机制,实现10TB/s吞吐带宽、亿级IOPS,智能算力利用率提升20%以上。大模型恢复时间从分钟级缩短至秒级,确保高价值智算数据强一致性和99.9999%可靠性,全面赋能大模型训练。
8、大规模机间高可靠网络技术
超万卡集群网络涵盖参数面、数据面、业务面和管理面四大网络。其中,参数面网络需支持高带宽无损,保障节点间参数交换;数据面网络亦要求高带宽,优化节点对存储的访问。业务面与管理面则采用传统TCP部署。超万卡集群对参数面网络有四大严苛要求:大规模、零丢包、高吞吐、高可靠。
目前业界成熟的参数面主要包括IB(InfiniBand)和RoCE两种技术。面向未来Al大模型演进对网络提出的大规模组网和高性能节点通信需求,业界也在探索基于以太网新一代智算中心网络技术,包括由中国移动主导的全调度以太网(GlobalScheduled Ethernet,GSE)方案6和Linux Foundation成立的超以太网联盟(UltraEthernet Consortium,UEC),两者通过革新以太网现有通信栈,突破传统以太网性能瓶颈,为后续人工智能和高性能计算提供高性能网络。中国移动也将加速推动GSE技术方案和产业成熟,提升Al网络性能,充分释放GPU算力,助力Al产业发展。
9、大规模组网
针对Al服务器规模,推荐采用Spine-Leaf两层或胖树(Fat-Tree)组网策略以优化参数面网络架构。
如图3所示,Spine-Leaf两层组网模型中,每组由8台Leaf交换机及相连的AI服务器构成。推荐多轨连接方式,即各AI服务器的网口依次连接至对应的Leaf交换机,确保高效通信。Spine交换机与Leaf交换机间实现Fullmesh全连接,确保网络稳定。此外,Leaf交换机上下行收敛比设定为1:1,保障数据流通畅无阻。此设计确保了网络扩展性与性能的双重优化。
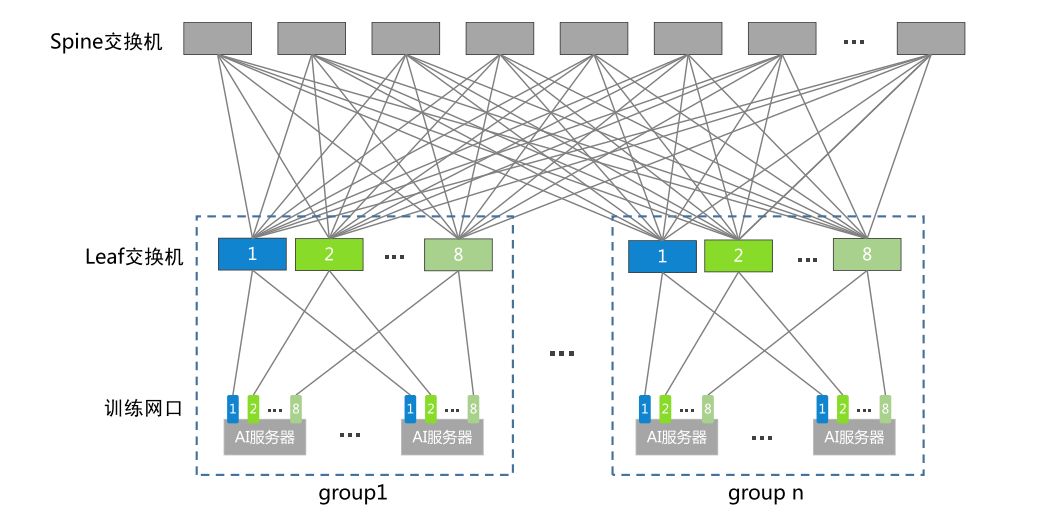
胖树(Fat-Tree)组网由Leaf交换机、Spine交换机和Core交换机组成,如图4所示。每8台Leaf交换机和下挂的Al服务器做为一个group,8台Leaf交换机又和上面N台Spine交换机组成一个pod,胖树组网以pod为单位进行扩展。在胖树组网中,Spine交换机和Leaf交换机之间采用Fullmesh全连接,所有Spinel都Full-Mesh连接至第一组Core,所有Spine2都Full-Mesh连接至第二组Core,依次类推。Spine交换机和Leaf交换机上下行收敛比都为1:1。

10、高容错高效能平台技术
智算平台,作为智算中心的核心,承载模型训练、推理与部署,统一纳管、调度、分配算力基础设施,实现全生命周期管理。该平台云化管控laaS资源,如计算、存储、网络,并通过云原生容器技术,精准满足智算业务需求,包括资源纳管分配、Al任务调度、拓扑感知调度及训练全链路监控,展现其卓越的综合性能。
11、断点续训高容错能力
大模型训练面临的主要挑战在于确保训练的连续性。硬件、软件、网络等故障频发,对耗时耗资的训练进程构成严重威胁。为克服这些困难,业界普遍采用自动故障检测与训练重启技术,并在训练过程中周期性保存checkpoint。一旦故障发生,训练即可从最近的checkpoint无缝重启,确保训练的高效与稳定。

平台运维监控能力可精准检测超万卡集群的软硬件故障,并预警。但故障导致模型训练中断时,需人工介入。我们将迅速排查故障,隔离并重启容器pod资源,重新初始化并行训练的集合通信,加载最新checkpoint信息,并重新编译算子库,确保训练任务无缝恢复。
在断点续训过程中,checkpoint是模型中断训练后恢复的关键点,因此checkpoint密集程度、保存和恢复的性能尤为重要,checkpoint本身的耗时与模型的大小成正比,当模型参数达到百亿甚至千亿时,checkpoint的时间开销通常在几分钟到十几分钟之间。
此时,训练任务需要暂停,使得用户难以频繁进行checkpoint操作,因此为保证训练效率,会适当拉长checkpoint保存周期。然而,一旦发生中断,之前损失的迭代次数在恢复时需要重新计算,需要花费更长的时间。
为解决该问题,需要尽量降低checkpoint流程的开销,既能大幅降低训练暂停时间,也能支持高频的checkpoint来减少容错时浪费的迭代步数。业界通常采用checkpoint多级存储的方式,构建基于更高10性能的内存介质构建存储系统,相比于磁盘或者网络文件存储系统,checkpoint在内存空间的保存可以大幅缩短训练暂停等待时间。
同时,结合业务需求定期地将checkpoint异步写入到持久化的存储系统中,异步流程不干扰正常的训练。当发生故障导致训练任务重启时,由于内存系统中的checkpoint数据并未丢失,新启动的训练进程可以直接读取内存系统中的checkpoint数据来加载模型和优化器状态,从而省去了读取网络存储系统的IO开销。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-