AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
- 一文解析AI预测数据工程
- FITS:一个轻量级而又功能强大的时间序列分析模型
- DLinear:未来预测聚合历史信息的最简单网络
- LightGBM:更好更快地用于工业实践集成学习算法
- 面向多特征的AI预测指南
- 大模型时序预测初步调研【20240506】
- Time-LLM :超越了现有时间序列预测模型的学习器
- CV预测:快速使用LeNet-5卷积神经网络
文章目录
LeNet-5卷积神经网络
背景
在1990年代,亚恩乐村(Yannlecun)等人提出了用于手写数字和机器打印字符识别的神经网络,被命名为勒内-5(lecun,博图,本吉奥,&哈夫纳,1998)。勒内一5的提出,使得卷积神经网络在当时能够成功被商用,广泛应用在邮政编码、支票号码识别等任务中。
简介
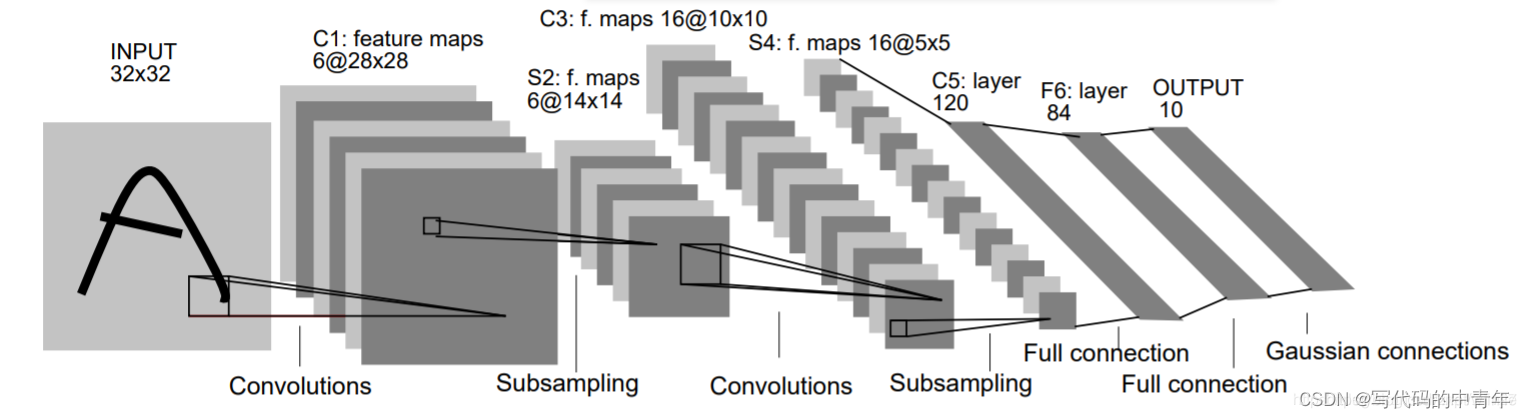
LeNet网络逐层结构:
图片输入:32x32x1第一层:卷积核(6个,5x5x1,步长:1),输出:28x28x6
最大池化层:卷积核(2x2,步长:2),输出:14x14x6
第二层:卷积核(16个,5x5x6,步长:1),输出:10x10x16
最大池化层:卷积核(2x2,步长:2),输出:5x5x16
拉直后输出:5 x5x16=400
全连接层1:120个节点
全连接层2:84个节点
输出层:10个节点
注:在进行卷积运算时,没有对输入进行填充。因此第一层的输出size=32-5+1=28,第二层的输出size=14-5+1=10
代码
python
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
# 1. 数据集准备
(x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
x = tf.expand_dims(x, -1) # 调整形状为(28, 28, 1)
y = tf.convert_to_tensor(y, dtype=tf.int32)
x_val = tf.convert_to_tensor(x_val, dtype=tf.float32) / 255.
x_val = tf.expand_dims(x_val, -1)
y_val = tf.convert_to_tensor(y_val, dtype=tf.int32)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)).batch(32)
# 2. 搭建网络
network = Sequential([
layers.Conv2D(6, kernel_size=3, activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Conv2D(16, kernel_size=3, activation='relu'),
layers.MaxPooling2D(pool_size=2, strides=2),
layers.Flatten(),
layers.Dense(120, activation='relu'),
layers.Dense(84, activation='relu'),
layers.Dense(10, activation='softmax')
])
network.build(input_shape=(None, 28, 28, 1))
network.summary()
# 3. 模型编译
optimizer = optimizers.Adam()
loss_fn = losses.SparseCategoricalCrossentropy(from_logits=True)
network.compile(optimizer=optimizer, loss=loss_fn, metrics=[metrics.Accuracy()])
# 4. 模型训练
epochs = 10
for epoch in range(epochs):
acc_meter = metrics.Accuracy()
for step, (x_batch, y_batch) in enumerate(train_dataset):
with tf.GradientTape() as tape:
out = network(x_batch)
loss = loss_fn(y_batch, out)
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
acc_meter.update_state(y_batch, tf.argmax(out, axis=1))
# 打印每个epoch的结果
print(f'Epoch {epoch + 1}, Loss: {loss.numpy()}, Accuracy: {acc_meter.result().numpy()}')
acc_meter.reset_states()