1.需求背景
爬取松产品中心网站下的家电说明书。这里以冰箱为例:松下电器-冰箱网址
网站分析:
第一步:
点击一个具体的冰箱型号,点击了解更多,会打开此型号电器的详情页面。
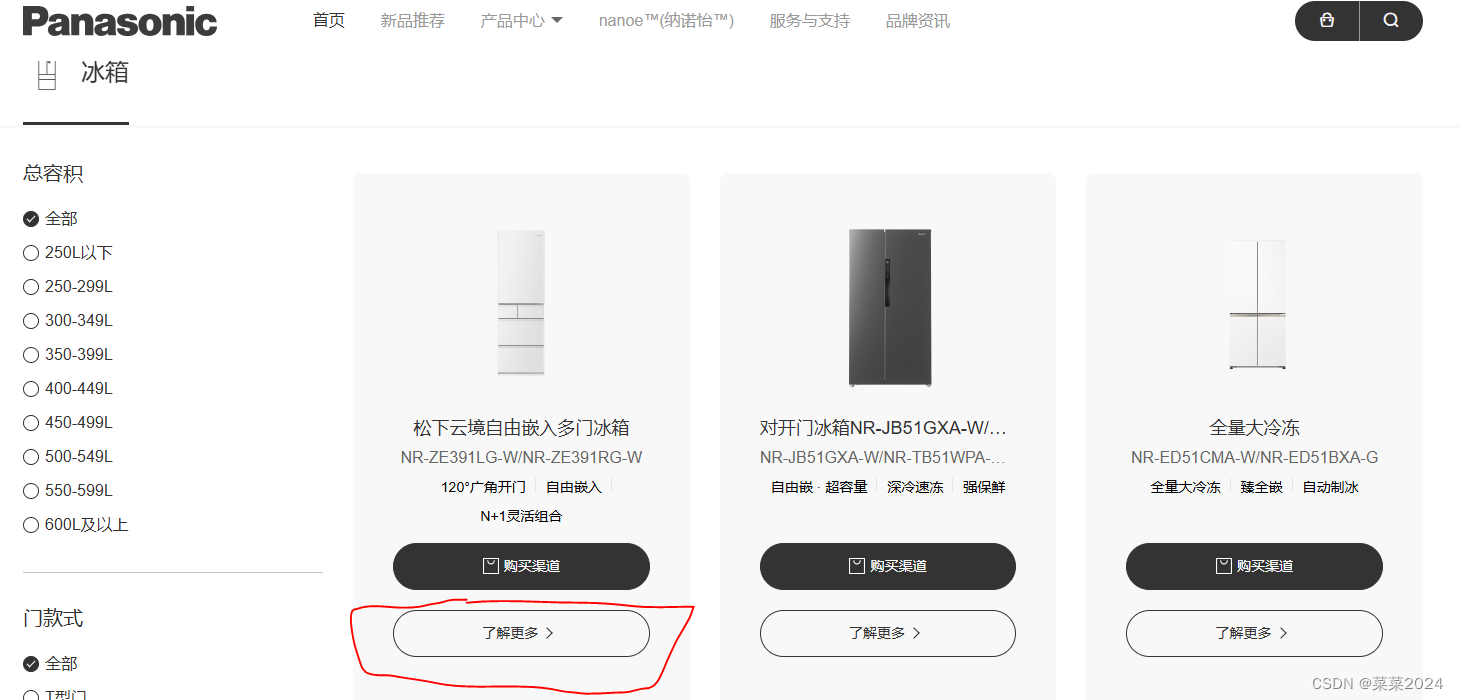
第二步:在新打开的详情页面中说明书下载标识
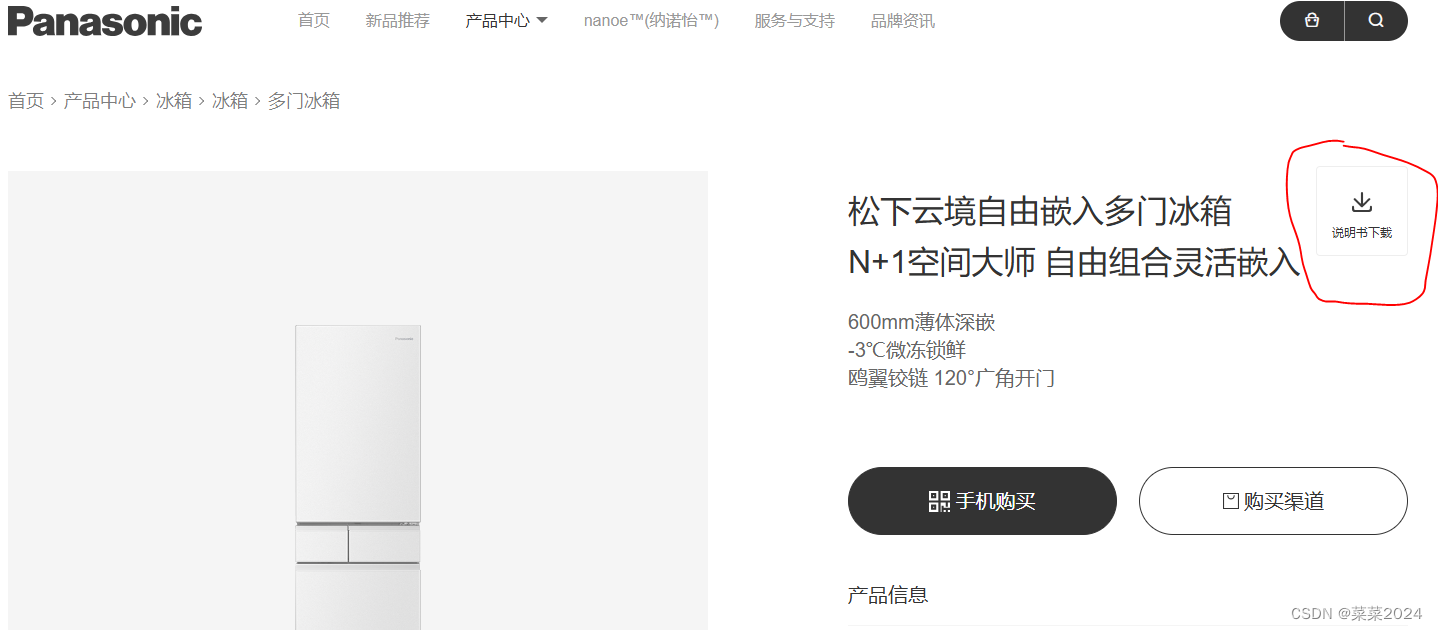
第三步:点击说明书下载,将下载此说明书
2.实现思路与核心步骤
由以上操作,我们知道了模拟用户点击的具体步骤,大致得到了一个整体思路。
主要难点:
- 如何在整个页面中定位到某一个具体的电器型号,如何遍历依次得到此页面所有型号
- 打开新页面,如何切换到新打开的窗口
- 如何定位到新打开窗口的说明书下载按钮
- 下载完成后如何切换回到原始的页面,进行下一个电器的点击
- 多个页面,如何进行翻页
2.1 得到新页面的链接
依次解决:
1.按F12,打开开发者模式,点击如图所示的1,检查,点击了解详情2,会自动定位显示如图3所示。

发现3标识的href就是此型号的详情页面。所以可以编写函数得到此链接。
这里也有两种方式:
方式一:使用Selenium模拟用户点击,使用xpath定位得到此href
方式二:使用requests直接得到此页面中的所有href链接,发现具体型号的链接时带有product,依据此进行筛选。
本文使用方式二:
python
def get_allurl(url):
'''
得到url下,所有以.html结尾的href标签下的链接
:param url:
:return:
'''
result_link = []
html_content = requests.get(url).text
soup = BeautifulSoup(html_content, "html.parser")
# 由开发者模式下可以看出,我们需要的href标签时a,且时以.html为结尾
link_nodes = soup.find_all('a', href=lambda href: href and href.endswith('.html'))
for node in link_nodes:
tem_url=node.get("href")
result_link.append(tem_url)
return result_link2.2 模拟用户进行点击下载
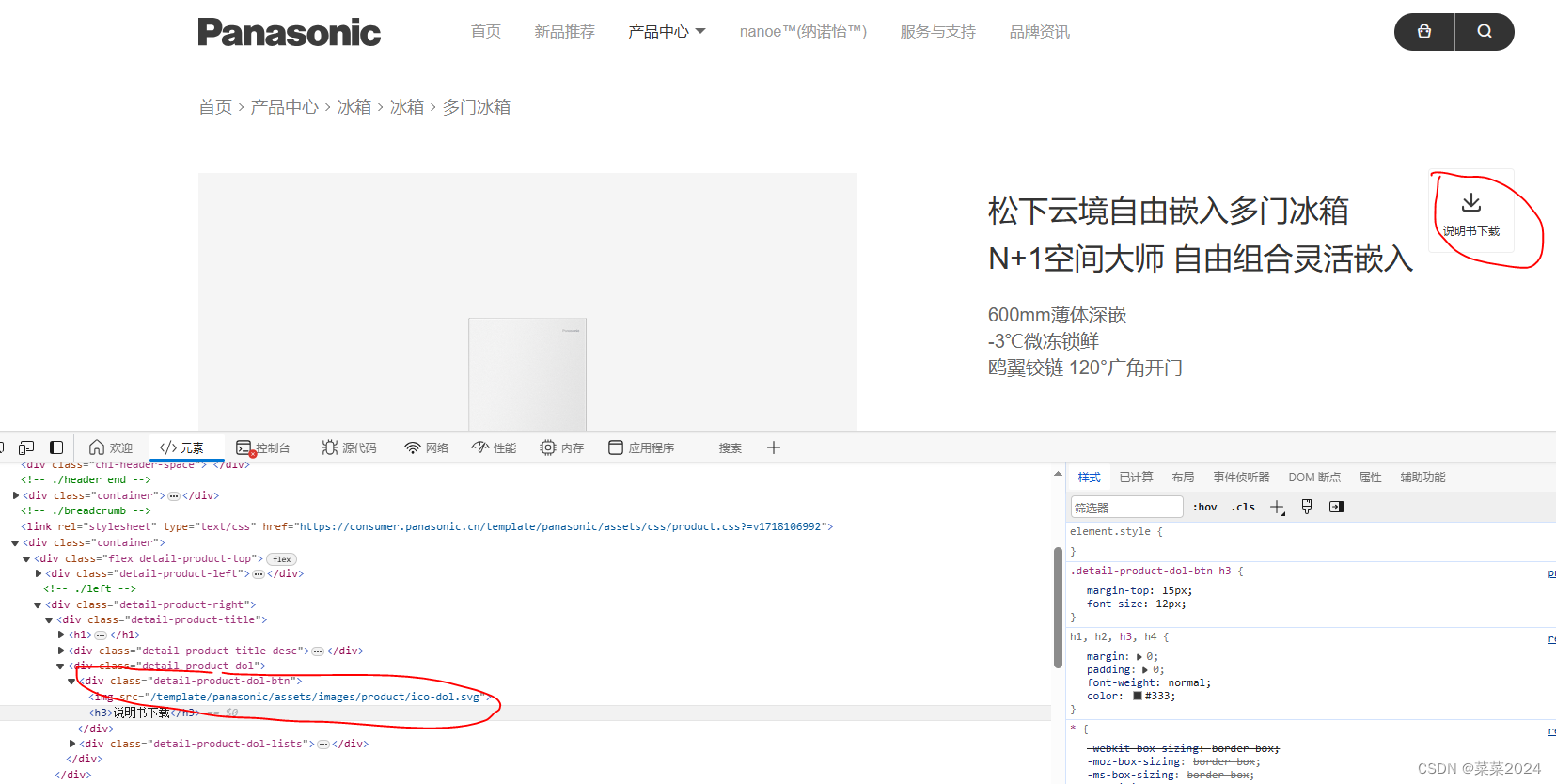
进入此页面,发现此网站下的链接并不是直接以.pdf为结尾的链接,而是有封装了一层,所以只能通过模拟用户点击的方式。

同时需要点击两次,首先第一次时说明书下载,出来具体型号,我们这里只选第一个NR-ZE391LG-W这个位置。
点击这些位置,得到其对应的XPATH
代码实现如下:
python
def clik_url(url):
# 初始化WebDriver
driver = webdriver.Chrome()
# 导航到包含链接的网页
driver.get(url)
# 为了防止有的型号不包含说明书,不存在对应的xpath路径,出现错误,终止程序
# 这里使用了try except
try:
# 找到说明书下载按钮的Xpath ='/html/body/div[5]/div/div[2]/div[1]/div/div[1]'
click_element = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable((By.XPATH, '/html/body/div[5]/div/div[2]/div[1]/div/div[1]'))
)
# 点击说明书下载
click_element.click()
# 页面加载完成后会出现具体型号,比如图中的NR-ZE391LG-W,找到此位置
res=WebDriverWait(driver, 5).until(
EC.visibility_of_element_located((By.XPATH, '/html/body/div[5]/div/div[2]/div[1]/div/div[2]/ul/li/a'))
)
# 此位置包含了一个以.pdf为结尾的href链接,是我们需要找的。
if res:
new_url=res.get_attribute('href')
# get_pdf(new_url)
print(new_url)
time.sleep(2)
driver.quit()
return new_url
else:
print("none")
time.sleep(2)
driver.quit()
return None
except:
time.sleep(2)
driver.quit()
pass此函数返回了pdf的具体链接,由此链接就可以直接获取到pdf文件
2.3 获取pdf文件
由以上得到的pdf链接,获取保存为pdf文件。例如:
https://home.panasonic.cn/support/attachments/auld/manual/NR-ZE391LG-W.pdf
python
def get_pdf(url,output_dir):
'''
url是一个后缀为.pdf的链接,点击就可以下载pdf文件,此函数保存pdf到output_dir路径
:param url:
:param output_dir:
:return:
'''
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 下载文件
try:
response = requests.get(url, stream=True)
response.raise_for_status()
except:
return
# 提取文件名(这里需要根据你的URL结构或链接的href属性来提取)
# 假设文件名是URL的最后一部分(不包括查询参数)
filename = os.path.basename(urlparse(url).path)
# 将文件保存到本地
with open(os.path.join(output_dir, filename), 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
print(f'Downloaded: {filename}')3. 整体流程和代码实现
python
def get_allurl(url):
······如上所示······
return result_link
def get_pdf(url,output_dir):
······如上所示······
def clik_url(url):
······如上所示······
return new_url
# 函数开始入口
def page_res(page_url,output_dir):
# 1.点击到电饭煲的主页面,返回这个页面下所有的以.html结尾的网址
prod_urls = get_allurl(page_url)
# 2.遍历网址,进行pdf下载
for i in range(len(prod_urls)):
print(prod_urls[i])
# 有一些.html的网页也不含pdf,发现含的都带有product字样,所以进行过滤
if 'product' in str(prod_urls[i]):
# 3.点击得到新出现的pdf链接
pdf_url = clik_url(prod_urls[i])
if pdf_url:
# 4.进行pdf文件下载
get_pdf(pdf_url, output_dir)
print("本页下载已完成")如果想要获取更多页面的冰箱型号,可以观察到不同页面的url是由规律的,直接for循环遍历页面就行了。
4.总结
1.使用获取所有链接再进行筛选的方式,代替了模拟用户点击以此定位具体位置,进行点击
2.在新打开的页面中没有直接暴露pdf链接,需要点击说明书下载按钮才能得到pdf链接,点击一次,显示pdf链接之后,并没有继续采用用户点击的方式,而是直接获取(这与网站有关,有点还是不会显示出来,只有点击才会出现)
因为没用采用点击,也不存在页面切换的问题。相比于全部Selenium模拟用户点击,少了许多步骤。