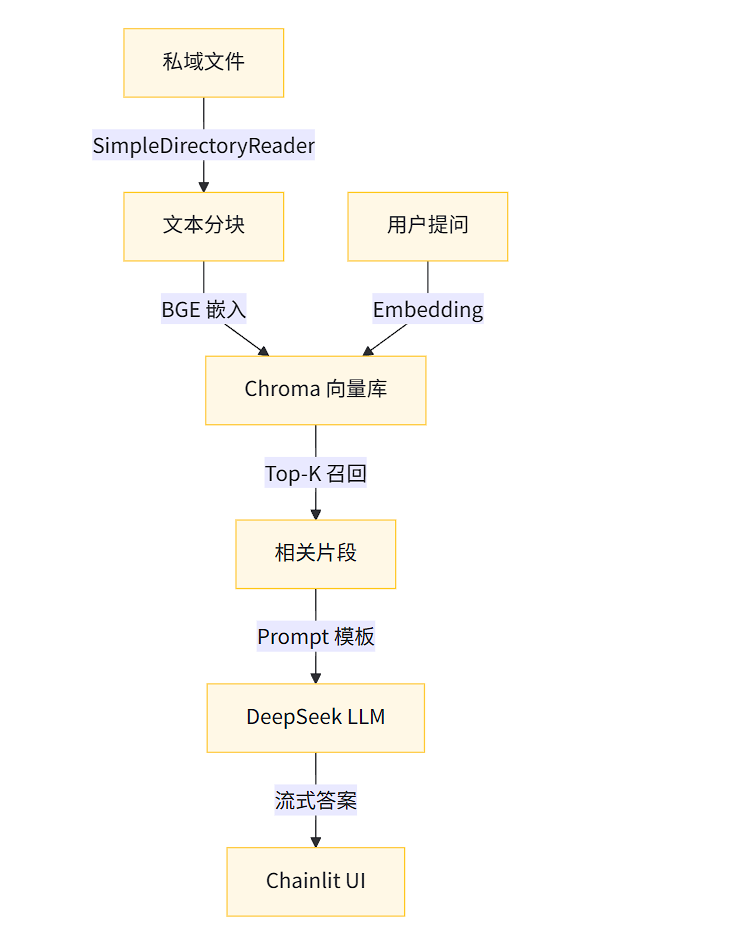
导读:30 min 完成「私域数据 + 大模型」问答系统
| 模块 | 技术选型 | 理由 |
|---|---|---|
| 文档解析 | LlamaHub | 300+ 格式开箱即用,无需自己写解析 |
| 文本分块 | LlamaIndex NodeParser | 自动保持语义完整,支持冗余重叠 |
| 向量化 | BAAI/bge-small-zh | 中文 SOTA,本地部署免费 |
| 向量库 | ChromaLite | pip 即用,零配置 |
| 大模型 | DeepSeek | 中文持平 GPT-3.5,注册送 500 万 token |
| 前端 | Chainlit | 3 行代码出聊天 UI,内置流式消息 |
知识点总览
- RAG 本质 :检索器
f(x)+ 生成器g(x),即 「先召回,再回答」 - Embedding 原理:把文字映射到高维向量,「语义相似 ≈ 欧氏距离近」
- 向量索引:HNSW(近似最近邻)→ 毫秒级召回,内存/磁盘双支持
- 分块策略 :
- 固定长度 vs 递归语义分割
- chunk_overlap 缓解边界信息丢失
- 提示工程 :
system_prompt + 上下文 + 用户查询三段论,防幻觉 - 流式生成:SSE(Server-Sent Events)→ 逐 token 推送,降低首响
- 多轮记忆:滑动窗口 + token 硬截断,避免超出模型上下文
- 可视化调试:Chainlit 自带「thought & observation」面板,RAG 中间步骤一目了然
1 项目骨架
rag-python/
├── data/ # 私域文件扔这里
├── index/ # 向量索引持久化
├── app.py # Chainlit 启动入口
├── build_index.py # 一次性构建索引
├── llms.py # DeepSeek 客户端封装
├── embeddings.py # BGE 本地嵌入
├── requirements.txt
└── README.md2 环境准备
bash
# 1. 创建虚拟环境(>=3.9)
conda create -n rag python=3.10 -y
conda activate rag
# 2. 一键安装依赖
pip install -r requirements.txtrequirements.txt(版本已锁,放心食用)
chainlit==1.1.0
llama-index==0.12.8
llama-index-llms-openai==0.3.0
llama-index-embeddings-huggingface==0.3.0
chromadb==0.5.0
pydantic==2.9.2⚠️ 踩坑记录:pydantic 2.10+ 会与 chainlit 的 dataclass 冲突,必须 2.9.2!
3 获取 DeepSeek API Key
- 打开 deepseek.com → 注册 → 控制台 → 创建 API Key
- 复制 key,仅创建时可见,丢失需重新创建
- 免费额度:500 万 token(足够演示 10 万次问答)
4 封装 DeepSeek & BGE
python
# llms.py
from llama_index.llms.openai import OpenAI
def deepseek_llm():
"""DeepSeek 聊天封装,与 OpenAI 接口 100% 兼容"""
return OpenAI(
api_key="sk-你的key", # 替换成自己的
model="deepseek-chat",
api_base="https://api.deepseek.com/v1",
temperature=0.7,
max_tokens=1024,
streaming=True, # 支持流式
)
python
# embeddings.py
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
def bge_small_zh():
"""中文语义表征 SOTA,本地缓存避免重复下载"""
return HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5",
cache_folder="./embed_cache",
embed_batch_size=32, # 根据内存调整
)5 一行命令构建索引
把任意文件(PDF/Word/Excel/PPT/网页)扔进 data/ 目录,执行:
bash
python build_index.py脚本内容(含分块、嵌入、持久化):
python
# build_index.py
from llama_index.core import (
VectorStoreIndex, SimpleDirectoryReader, Settings, StorageContext)
from llms import deepseek_llm
from embeddings import bge_small_zh
Settings.llm = deepseek_llm() # 构建索引时无需 LLM,但 LlamaIndex 需要实例
Settings.embed_model = bge_small_zh()
def build():
docs = SimpleDirectoryReader(
input_dir="data",
recursive=True, # 支持子目录
filename_as_id=True # 用文件名当 id,方便溯源
).load_data(show_progress=True)
index = VectorStoreIndex.from_documents(
docs,
transformations=[ # 可选:自定义分块
SentenceSplitter(
chunk_size=512,
chunk_overlap=50,
)
]
)
index.storage_context.persist(persist_dir="index")
print("✅ 索引完成,共 {} 个节点".format(len(index.ref_doc_info)))
if __name__ == "__main__":
build()知识点:
SentenceSplitter按句号/问号/感叹号切分,再拼接成 512 token,保证语义完整!
6 Chainlit 聊天主程序
python
# app.py
import chainlit as cl
from llama_index.core import Settings, StorageContext, load_index_from_storage
from llama_index.core.chat_engine import ContextChatEngine
from llama_index.core.memory import ChatMemoryBuffer
from llms import deepseek_llm
from embeddings import bge_small_zh
@cl.on_chat_start
async def start():
"""会话生命周期入口:初始化模型 + 加载索引 + 创建引擎"""
Settings.llm = deepseek_llm()
Settings.embed_model = bge_small_zh()
# 加载已持久化的向量索引
storage_context = StorageContext.from_defaults(persist_dir="index")
index = load_index_from_storage(storage_context)
# 带记忆的聊天引擎
memory = ChatMemoryBuffer.from_defaults(token_limit=2048)
chat_engine = index.as_chat_engine(
chat_mode="context", # RAG 模式
memory=memory,
similarity_top_k=3, # 召回 3 段上下文
system_prompt=(
"你是企业知识助手,只能使用提供的上下文回答,禁止编造。若上下文无答案,请明确说明。"),
)
cl.user_session.set("chat_engine", chat_engine)
await cl.Message(content="📚 知识库已加载,快来问我任何问题吧!").send()
@cl.on_message
async def main(message: cl.Message):
"""每条用户消息都会触发此函数,流式返回答案"""
chat_engine = cl.user_session.get("chat_engine")
msg = cl.Message(content="", author="Assistant")
# LlamaIndex 异步接口
res = await cl.make_async(chat_engine.stream_chat)(message.content)
for token in res.response_gen:
await msg.stream_token(token)
await msg.send()启动:
bash
chainlit run app.py -w浏览器自动打开 http://localhost:8000,界面如下:
左侧:聊天窗口
右侧:「Thought & Observation」调试面板,可查看召回片段、token 用量7 效果演示
- 上传《员工手册.pdf》
- 输入「年假几天?」
- 机器人返回: 根据《员工手册》第 12 条,年假 5-15 天,具体年限见下表......
并高亮引用片段,支持点击跳转原文!
8 性能&调优锦囊
| 现象 | 排查思路 | 快速修复 |
|---|---|---|
| 答案碎片化 | chunk_size 过小 | 调到 512~1024,加 overlap=50 |
| 召回为 0 | 向量维度不一致 | 确保 embed_model 与建索引时相同 |
| 首响慢 | 未流式 | 确认 streaming=True + chainlit 异步 |
| 中文乱码 | PDF 编码异常 | 先 PyMuPDF 转 TXT,再丢 data |
| 显存爆满 | 嵌入批量大 | 降 embed_batch_size=8 或换 bge-micro-zh |
9 从 Demo 到生产:扩展路线
| 功能 | 技术点 |
|---|---|
| 多轮对话持久化 | ChatMemoryBuffer → Redis |
| 权限登录 | Chainlit 原生 @cl.password_auth |
| 多模态问答 | llama-index-multi-modal-llms 支持图文 |
| 实时爬虫 | llama-index-readers-web 定时索引 |
| 企业级向量库 | Milvus / PGVector / OpenSearch |
| 模型量化 | llama-cpp-python + gguf 4bit 本地跑 |
| 容器部署 | 官方 chainlit/docker 镜像一键上架 |
运行步骤:
bash
git clone https://github.com/yourname/rag-python-chainlit.git
cd rag-python-chainlit
conda env create -f environment.yml
chainlit run app.py -w10 总结
跟着本文,你已完成:
✅ 环境搭建 → ✅ 数据索引 → ✅ 语义检索 → ✅ 流式问答 → ✅ 可视化调试