文章目录
- 一,使用dataclass模块
-
-
- [1. 先看"常规类"的痛点](#1. 先看“常规类”的痛点)
- [2. 再看"dataclass类"的简化逻辑](#2. 再看“dataclass类”的简化逻辑)
- [3. 两者效果完全等价](#3. 两者效果完全等价)
-
- [二,表示与比较(Representation and Comparisons)](#二,表示与比较(Representation and Comparisons))
- 三,@dataclass参数
-
- 1,sorting排序
- [2,处理不可变数据类(Immutable Data Classes)](#2,处理不可变数据类(Immutable Data Classes))
- 四,使用dataclass进行继承
- 五,总结
参考上一篇博客:https://blog.csdn.net/weixin_62528784/article/details/152805354?spm=1001.2014.3001.5501
本篇是对python中OOP的一些补充,随遇随记。
在 Python 中,数据类是一种仅设计用来存储数据值的类。它们与普通类没有区别,但通常不包含其他任何方法。它们通常用于存储将在程序或系统的不同部分之间传递的信息。
然而,在创建仅作为数据容器的类时,反复编写 init 方法会产生大量工作和潜在的错误。
dataclasses 模块,在 Python 3.7 中引入的一项功能,提供了一种无需编写方法即可更简便地创建数据类的方式。
这篇博客,目的就是如何利用这个模块快速创建新的数据类dataclass,这些类不仅带有 init ,还预实现了其他几种方法(注意是预),因此我们无需手动实现它们。
一,使用dataclass模块
假设我们要实现一个用于存储关于某群人数据的类。对于每个人,我们将有姓名、年龄、身高和电子邮件地址等属性。一个常规类的样子如下:

上面是普通的类的写法,现在我们想要使用dataclass模块;
首先我们需要导入dataclass,这样才能在创建的类中将其用作装饰器(decorator)。这样做时,我们不再需要编写 init 函数,只需指定类的属性及其类型。
以下是使用这种方法实现的相同 Person 类:
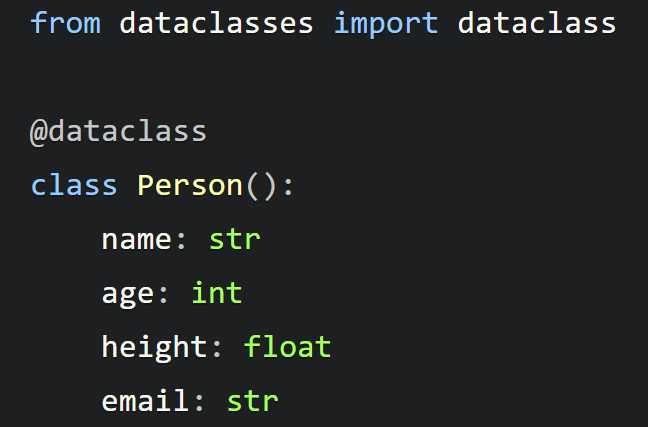
乍一看其实常规class和dataclass没有什么区别,但实际上dataclasses模块能够简化数据类创建。
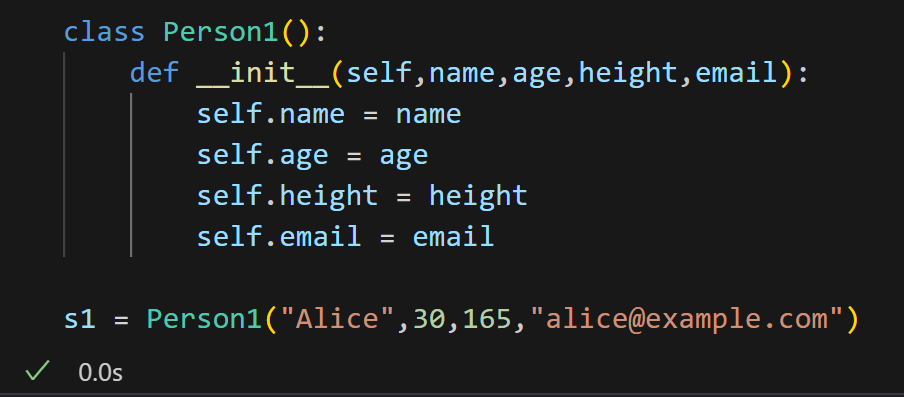
1. 先看"常规类"的痛点
常规定义 Person 类时,必须手动编写 __init__ 方法(构造方法):
- 作用:通过
self.属性名 = 参数的形式,将创建对象时传入的参数(如name、age)赋值给类的属性,让对象拥有这些数据。 - 问题:当属性较多时(比如再增加"性别""电话"),需要重复写大量
self.xxx = xxx的代码,既繁琐又容易因手误出错(比如参数名和属性名不一致)。
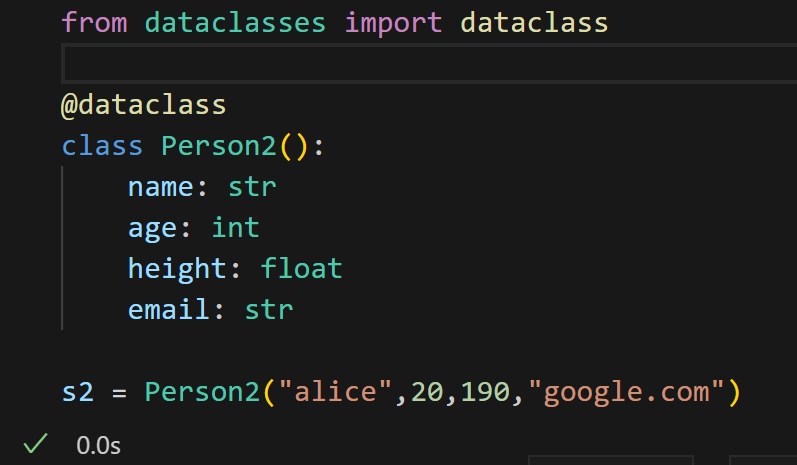
2. 再看"dataclass类"的简化逻辑
用 dataclasses 模块的 @dataclass 装饰器(一种"代码模板工具")后,核心变化是自动生成 __init__ 方法:
- 第一步:导入工具:
from dataclasses import dataclass,获取dataclass装饰器。 - 第二步:装饰类:在
class Person()上方加@dataclass,告诉Python"这个类是数据类,帮我自动生成构造方法"。 - 第三步:声明属性:直接写
name: str「属性名: 类型标注」的格式,无需写__init__:name: str表示"类有一个name属性,类型是字符串",age: int表示"age属性是整数",以此类推。- Python会根据这些声明,自动生成和常规类功能完全一致的
__init__方法,省去手动编写的麻烦。
3. 两者效果完全等价
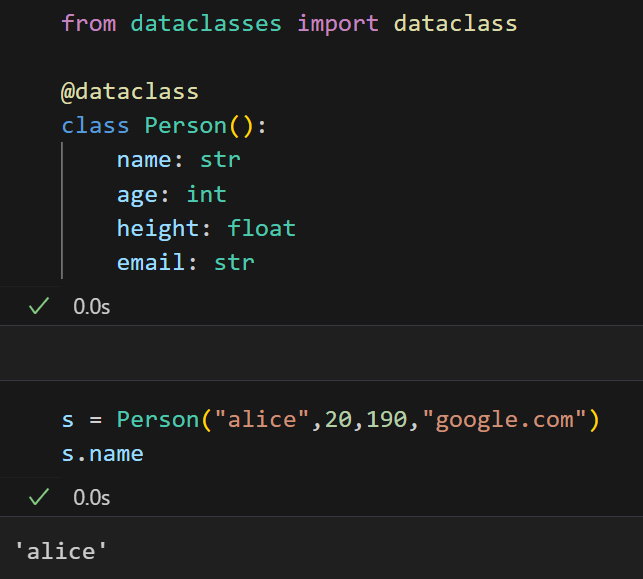
无论是常规类还是dataclass类,创建对象、使用属性的方式完全一样:
python
# 常规类创建对象
p1 = Person("张三", 20, 1.75, "zhangsan@xxx.com")
# dataclass类创建对象(写法相同)
p2 = Person("李四", 22, 1.80, "lisi@xxx.com")
# 访问属性(写法也相同)
print(p1.name) # 输出"张三"
print(p2.age) # 输出22本质是 dataclasses 帮我们"自动写了重复的 __init__ 代码",让开发者聚焦于"要存哪些属性、属性是什么类型",而非冗余的语法细节。
比较如下:

当然,我们也可以为类属性设置默认值:
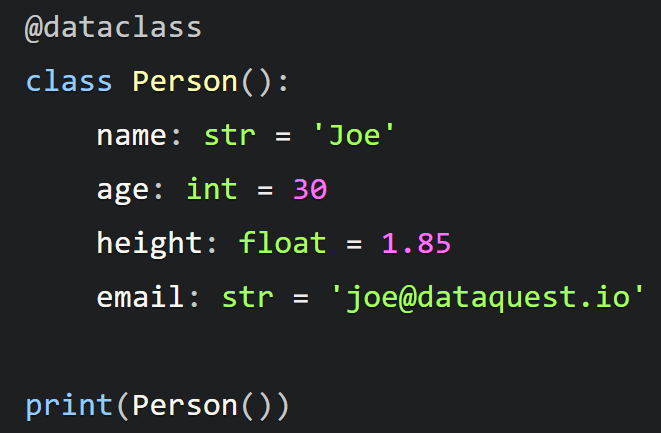
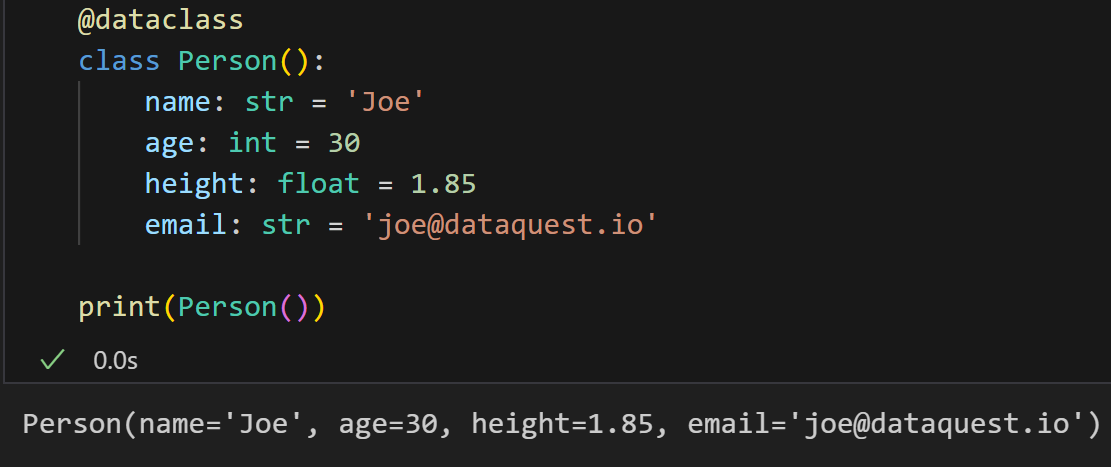
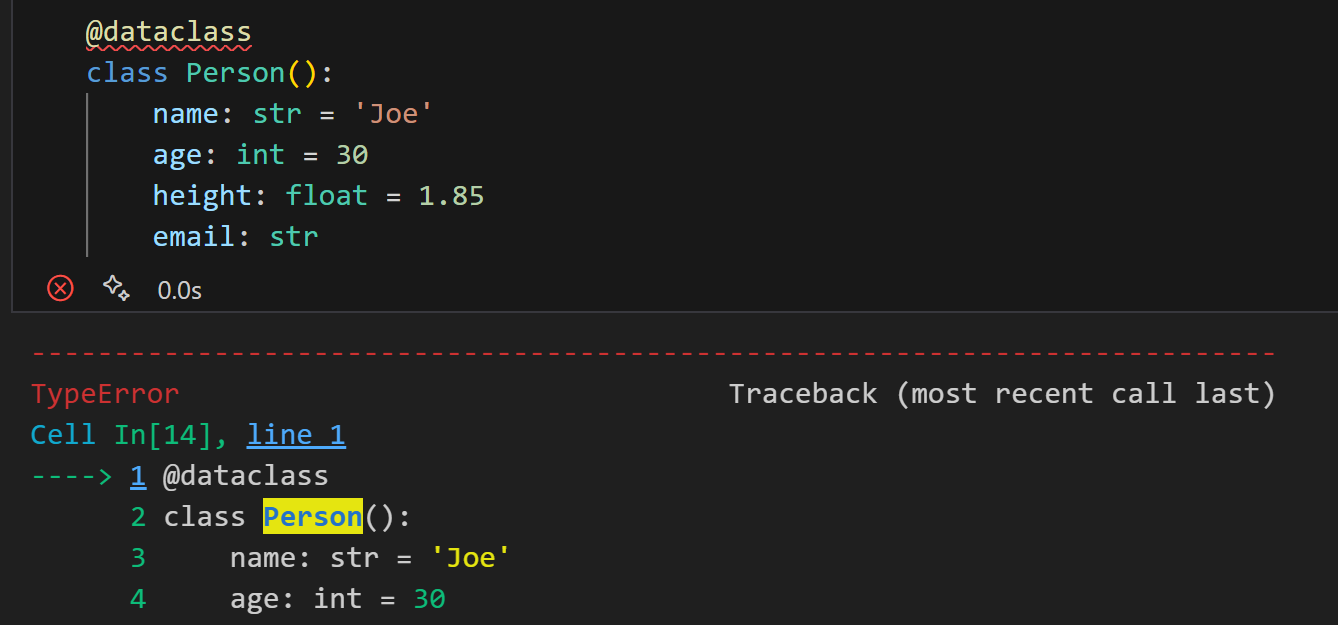
作为提醒,Python 在类和函数中都不接受在默认参数之后出现非默认参数,这样做会报错:

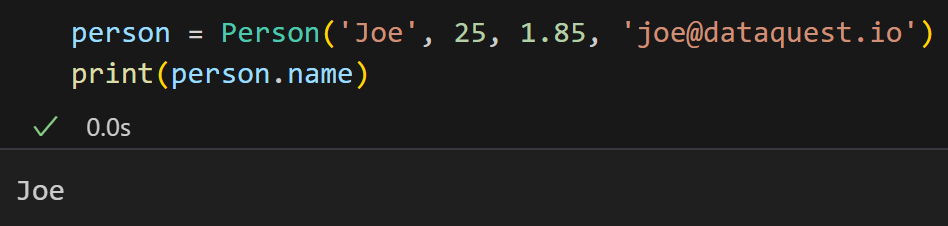
定义好类之后,就像标准类一样,可以轻松地实例化新对象并访问其属性:
到目前为止,我们使用了普通的数据类型,如字符串、整数和浮点数;我们还可以结合 dataclass 和 typing 模块来在类中创建任何类型的属性。例如,让我们向 Person 添加一个记录家庭住址的属性,比如说精确到经纬度的tuple数据,house_coordinates 属性:
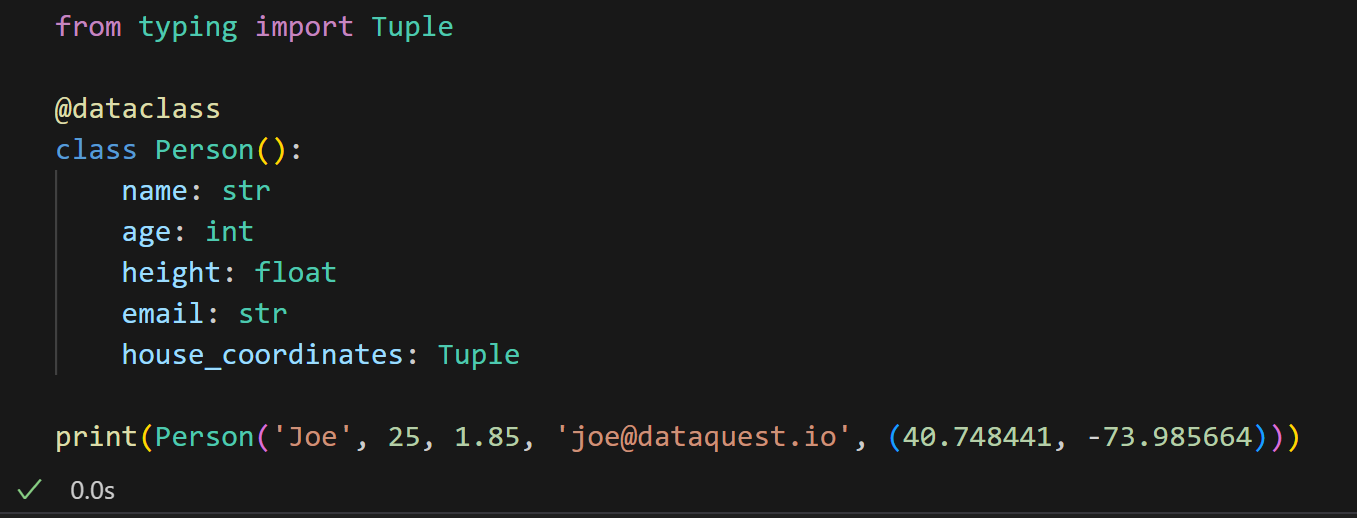

遵循同样的逻辑,我们可以创建一个数据类来保存 Person 类的多个实例:
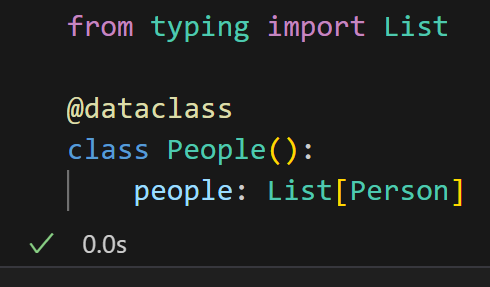
请注意,在 People 类中定义的 people 属性是一个 Person 类的实例列表。例如,我们可以像这样实例化一个 People 对象:
plain
joe = Person('Joe', 25, 1.85, 'joe@dataquest.io', (40.748441, -73.985664))
mary = Person('Mary', 43, 1.67, 'mary@dataquest.io', (-73.985664, 40.748441))
print(People([joe, mary]))
这使我们能够将属性定义为任何我们想要的数据类型,也可以是多种数据类型的组合。
二,表示与比较(Representation and Comparisons)
正如我们之前提到的, dataclass 不仅实现了 init 方法,还包括其他几个方法,其中包括 repr 方法。在一个常规类中,我们使用这个方法来显示类中对象的表示形式。
plain
__repr__ 是类的特殊方法,核心作用是返回对象的 "官方字符串表示",
主要用于开发者调试(比如查看对象具体信息),
而非给普通用户展示(面向用户展示通常用 __str__ 方法)比如说一个常规的类:
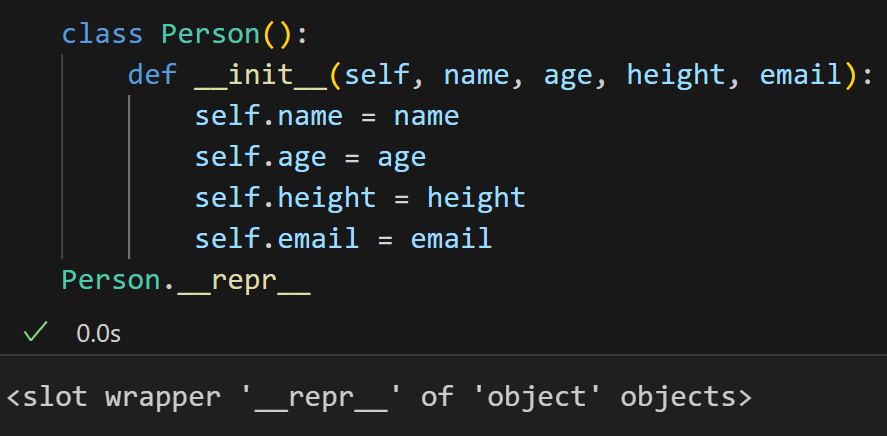
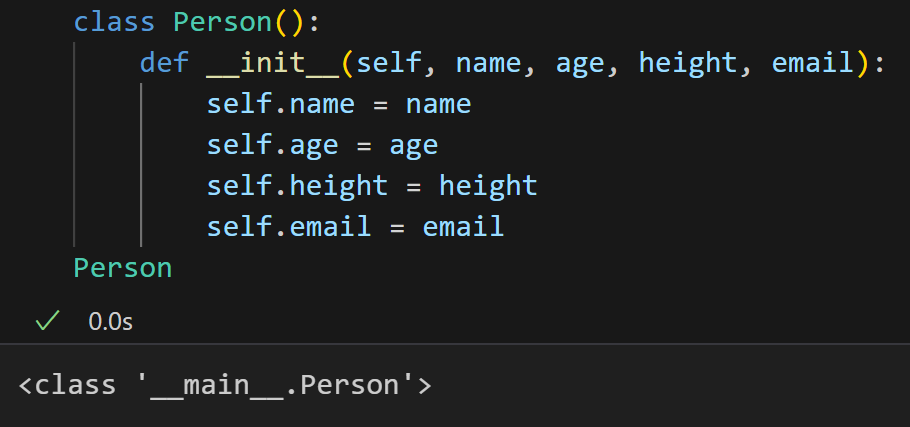
我们具体来看一个实例对象,是Person类的对象object,然后内存地址也给出来了。
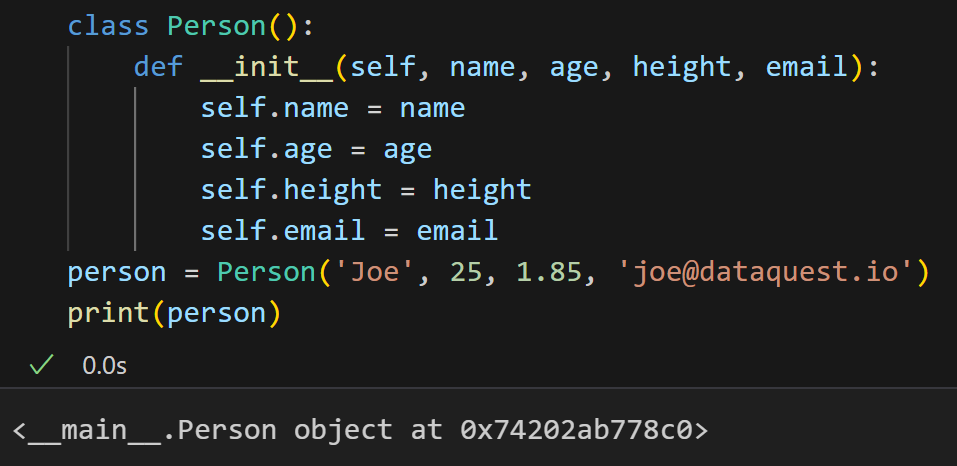
但是这个表示形式实在是不雅观,也不容易一下子看懂。
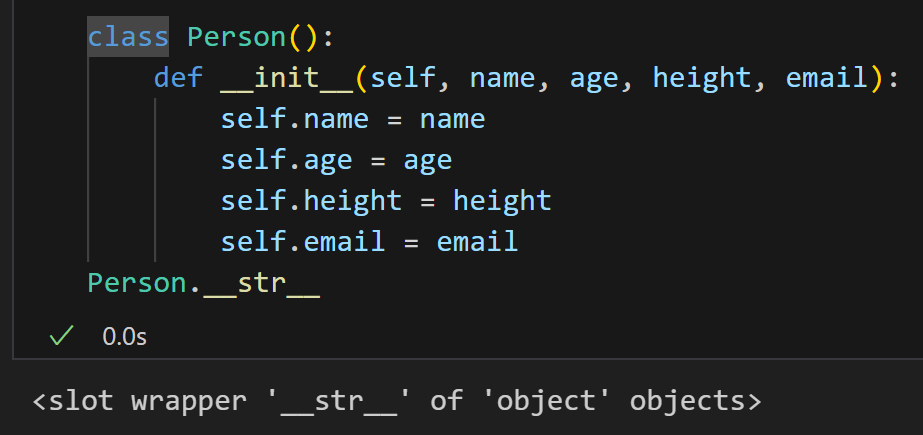
所以我们可以自己来写一个str方法:
下面的就是我们在调用对象时,我们所通常定义的方法。
plain
class Person():
def __init__(self, name, age, height, email):
self.name = name
self.age = age
self.height = height
self.email = email
def __repr__(self):
return (f'{self.__class__.__name__}(name={self.name}, age={self.age}, height={self.height}, email={self.email})')
person = Person('Joe', 25, 1.85, 'joe@dataquest.io')
print(person)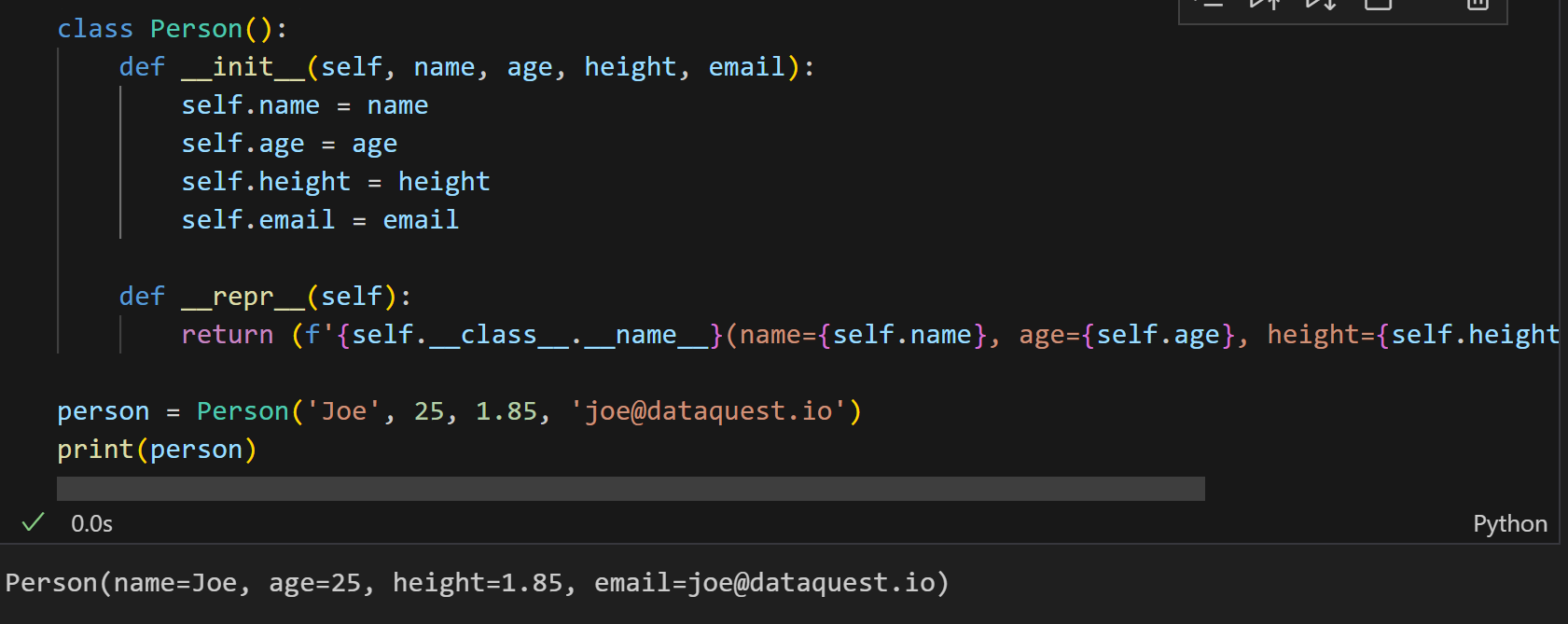
在两相比较之下,我们可以清楚地发现,普通的class类需要我们自己去定义并实现repr方法。
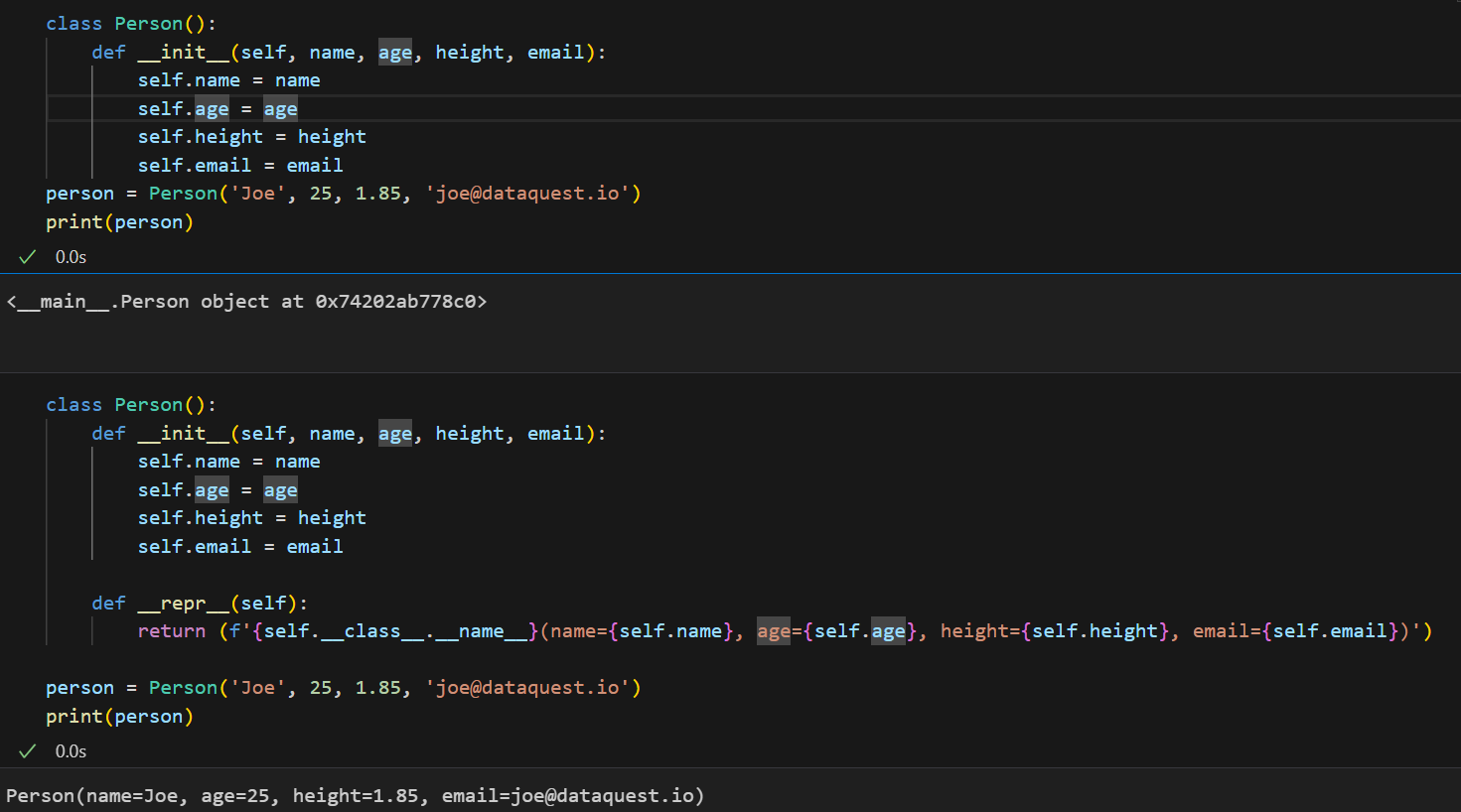
而,在使用 dataclass 时,无需编写任何内容,也就是预实现了美观的str方法:
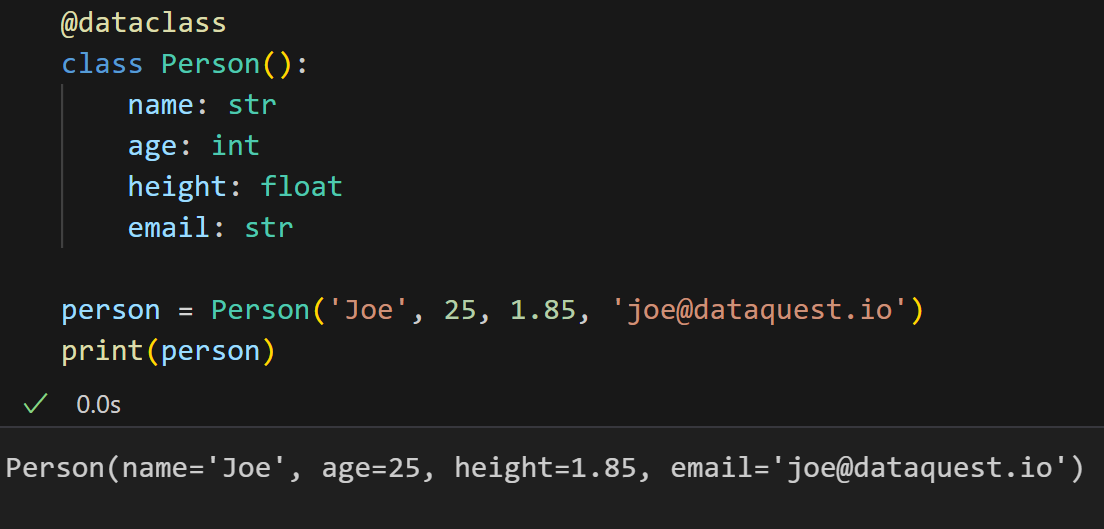
如果我们想要自定义类的表示形式,可以随时覆盖它:
plain
@dataclass
class Person():
name: str
age: int
height: float
email: str
def __repr__(self):
return (f'''This is a {self.__class__.__name__} called {self.name}.''')
person = Person('Joe', 25, 1.85, 'joe@dataquest.io')
print(person)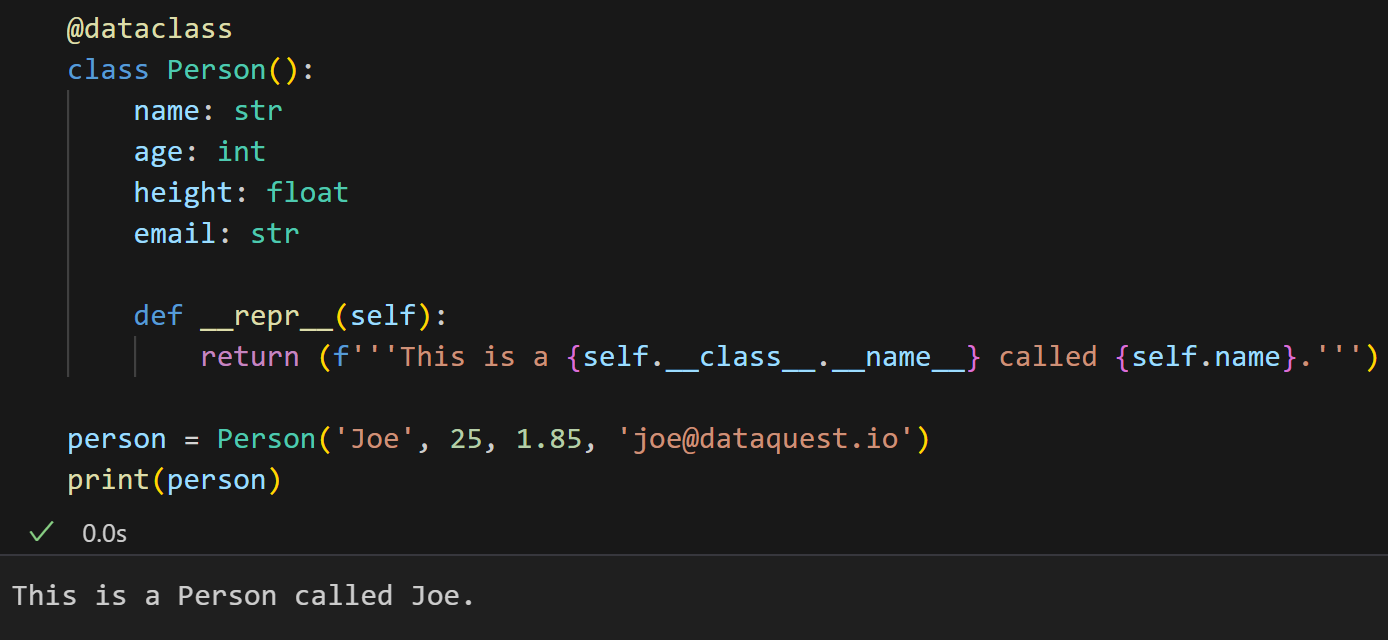
在比较方面, dataclasses 模块使我们的生活更简单。例如,我们可以像这样直接比较两个类的实例(两个实例都使用了默认属性):
plain
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = 'joe@dataquest.io'
print(Person() == Person())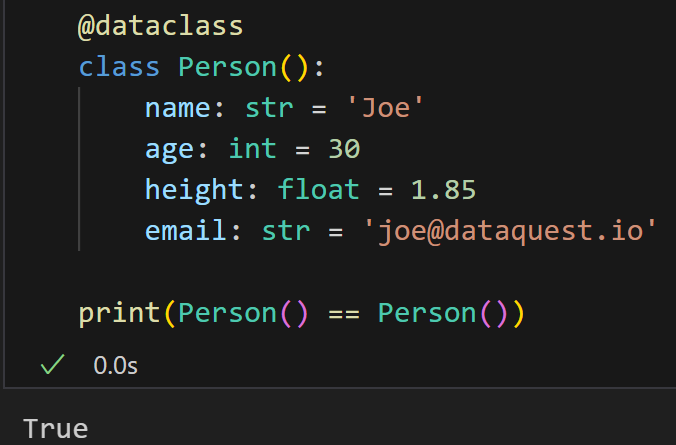
但是这种比较方法在普通类中无法简单实现,需要编写eq方法:
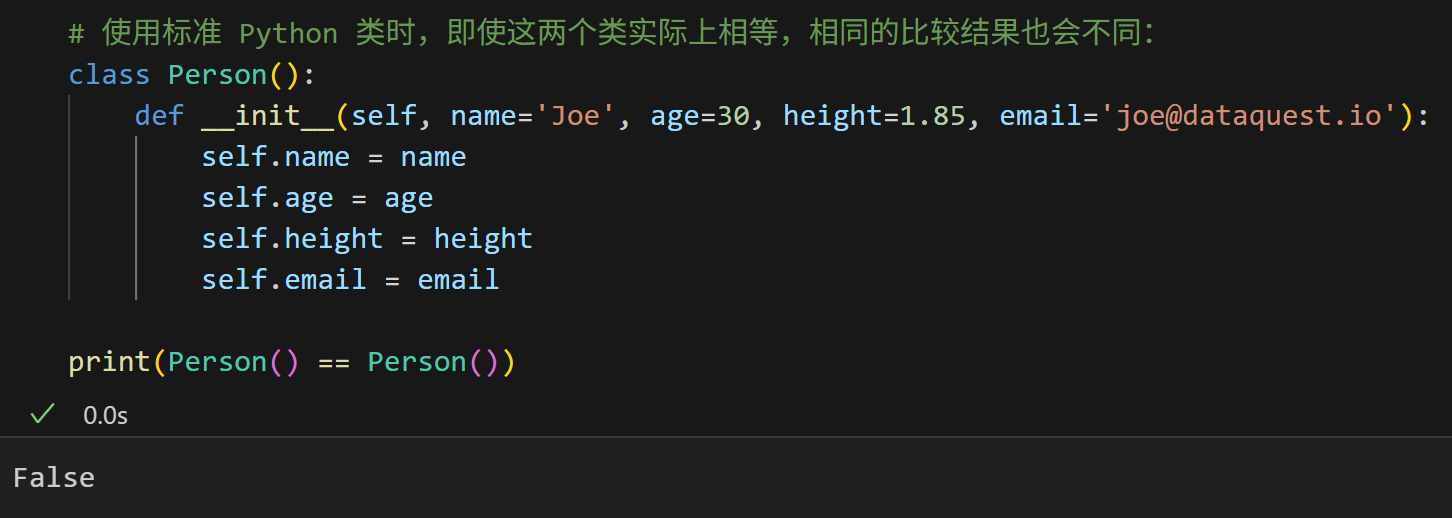
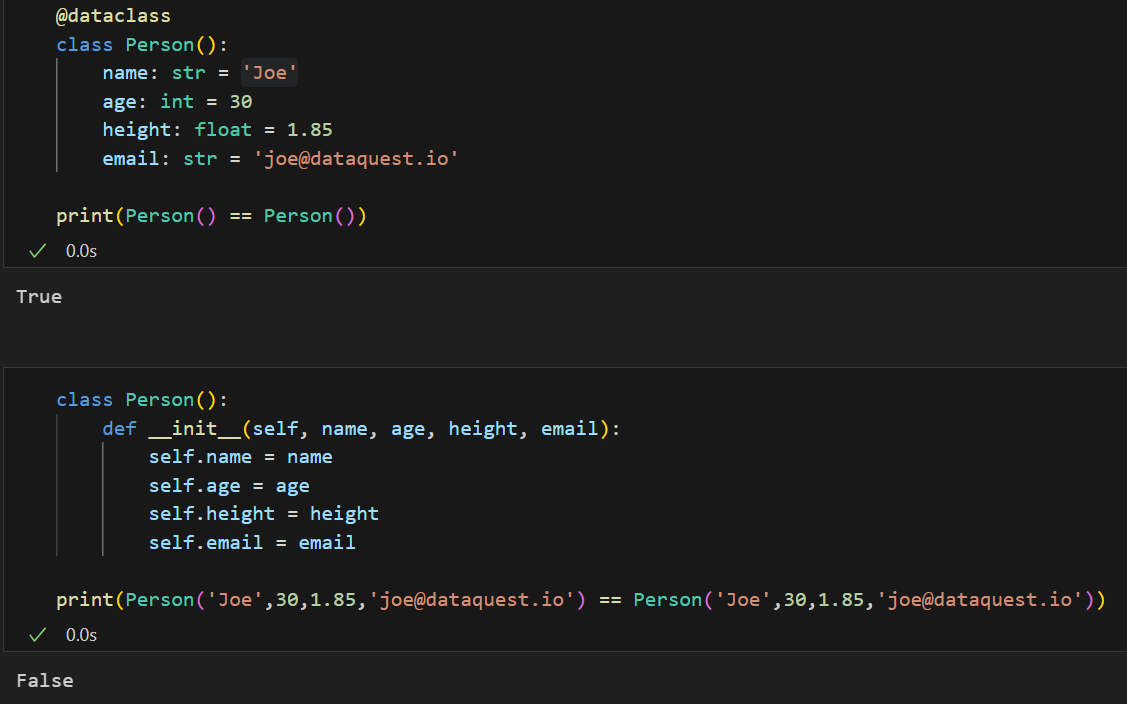
在这种情况下,比较是有效的,因为 dataclass 在后台创建了一个 eq 方法,该方法执行比较。如果没有装饰器@dataclass,我们将不得不自己创建这个方法。
如果没有使用 dataclass 装饰器,该类不会测试两个实例是否相等。因此,默认情况下,Python 将使用对象的 id 来进行比较。
关于内存地址函数id的使用,可以参考之前的博客:https://blog.csdn.net/weixin_62528784/article/details/144705158。
并且,正如我们看到的那样,它们是不同的:
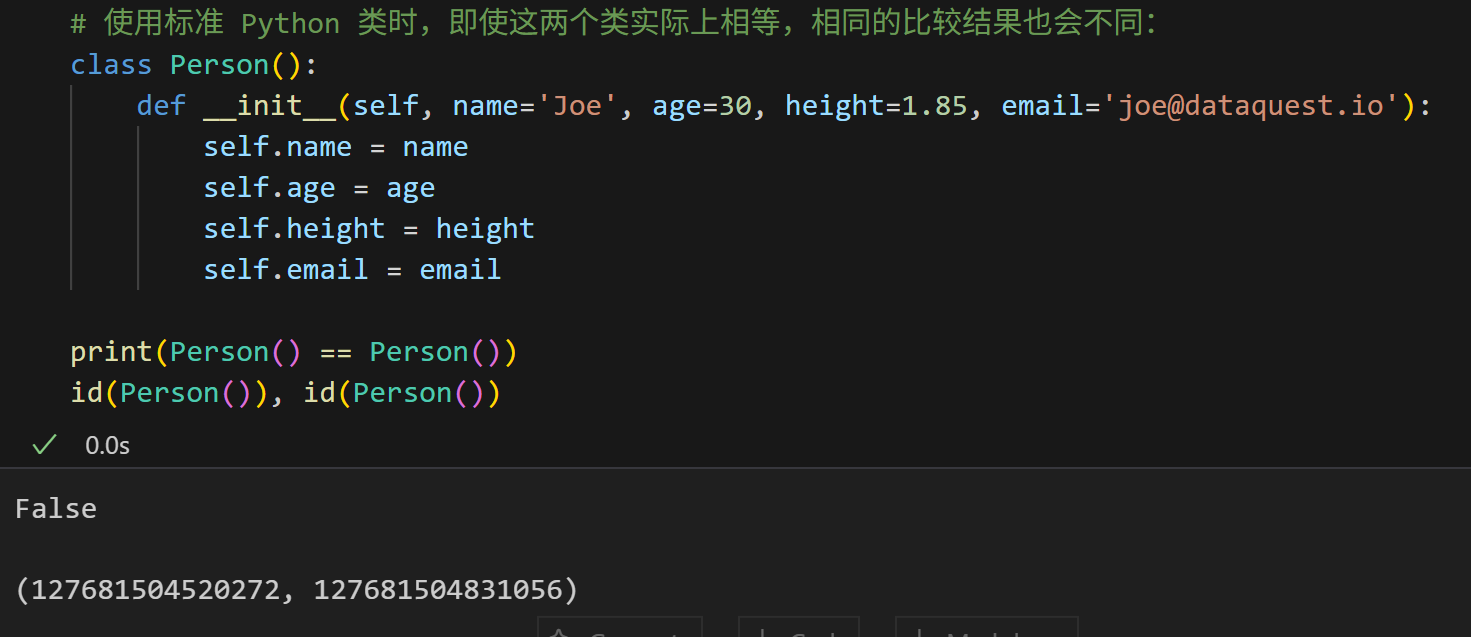
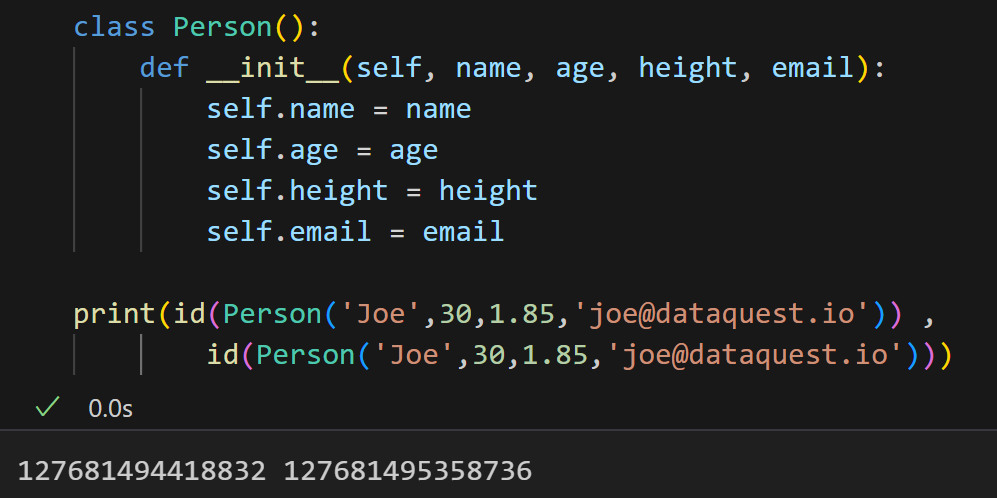
所有这一切都意味着我们需要编写一个 eq 方法来进行这个比较:
plain
class Person():
def __init__(self, name='Joe', age=30, height=1.85, email='joe@dataquest.io'):
self.name = name
self.age = age
self.height = height
self.email = email
def __eq__(self, other):
if isinstance(other, Person):
return (self.name, self.age,
self.height, self.email) == (other.name, other.age,
other.height, other.email)
return NotImplemented
print(Person() == Person())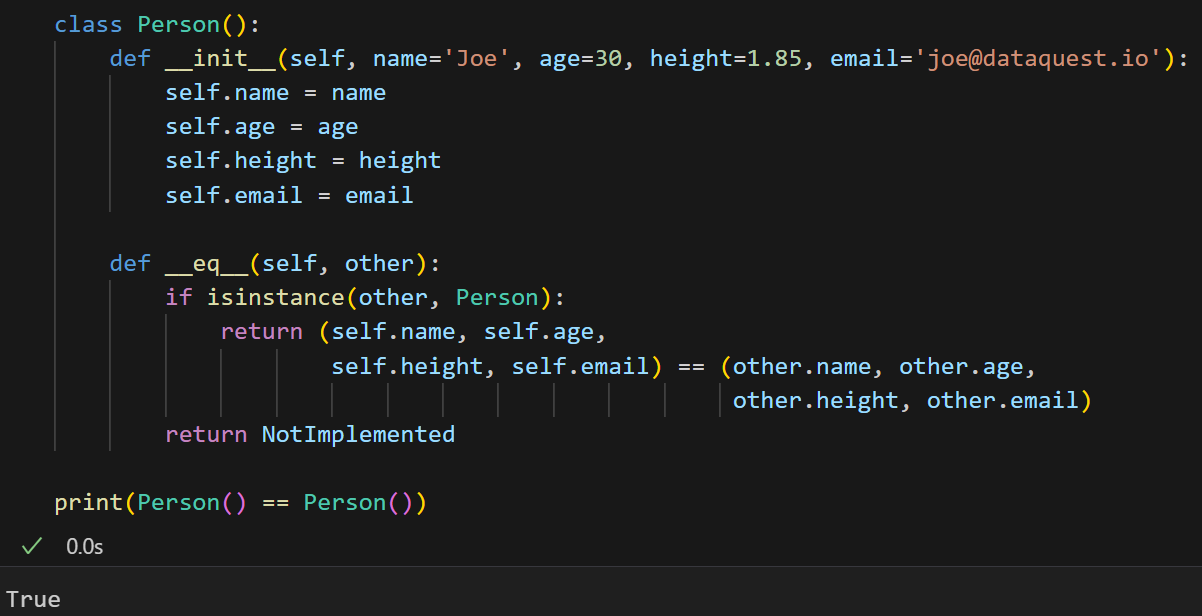
现在我们看到这两个对象彼此相等,但我们不得不编写更多代码才能得到这个结果,这就是有没有使用dataclass的区别。
三,@dataclass参数
如上所述,在使用 dataclass 装饰器时, init 、 repr 和 eq 方法将为我们自动实现。所有这些方法的创建都是由 dataclass 的 init 、 repr 和 eq 参数控制的。这三个参数默认为 True 。如果其中一个在类内部被创建,则该参数将被忽略。
我们接着看一下其他的参数:
order :它能够对类进行排序。默认值为 False ,在后面我们再提一下细节。
frozen :当 True 时,类实例内部的值在创建后不能被修改。默认值为 False 。
其余的一些细节参考官方文档:https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass。
1,sorting排序
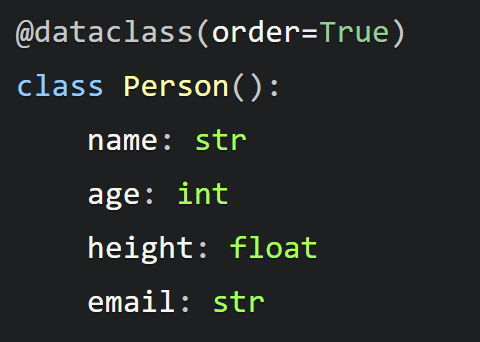
在处理数据时,我们经常需要对数值进行排序。在我们的场景中,我们可能需要根据某个属性对不同的人进行排序。为此,我们将使用上述提到的dataclass装饰器的order参数,该参数能够在类中实现排序:
plain
@dataclass(order=True)
class Person():
name: str
age: int
height: float
email: str当 order 参数设置为 True 时,它会自动生成 lt (小于)、 le (小于或等于)、 gt (大于)和 ge (大于或等于)方法,用于排序。
举一个例子,用两个实例化的对象来比较一下:
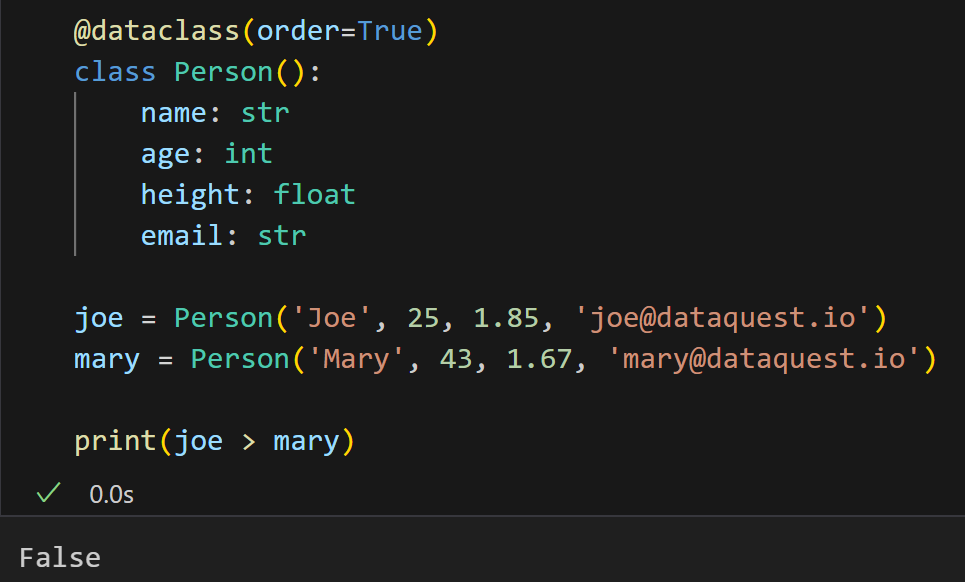
这是什么比较逻辑呢?
常规来想,如果我们忽略class、instance的复杂结构,只看这些待比较的属性值的话:
比如说我们把这两个对象比较看作是比较两个属性元组数据,
那么又是常规想法,首先是比较元组数据中的第一个:
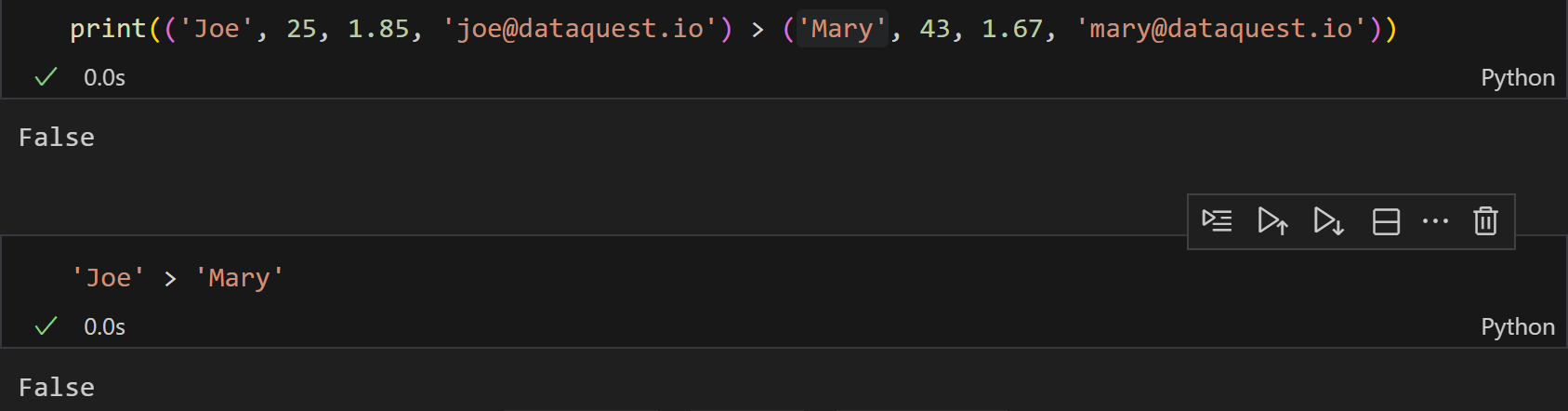
可以说是猜对了,比较的逻辑就是简单的unicode编码值的比较,
ord、chr函数的使用,参考之前的博客:
https://blog.csdn.net/weixin_62528784/article/details/144705158
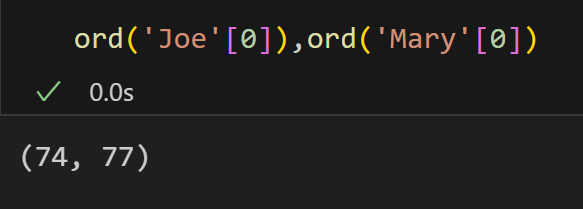
如果名称相同,它将移动到每个元组的下一个元素。目前,它正在按字母顺序比较对象。尽管这在一定程度上可能取决于我们处理的问题,但我们希望能够控制对象将如何排序。
要实现这一点,我们将利用 dataclasses 模块的另外两个特性。
第一个是 field 函数。该函数用于单独自定义数据类的一个属性,这使我们能够定义新的属性,这些属性将依赖于另一个属性,并且只有在对象实例化后才会被创建。
在我们的排序问题中,我们将使用 field 来在我们的类中创建一个 sort_index 属性。该属性只能在对象实例化后才能被创建,并且是 dataclasses 用于排序的依据:
plain
from dataclasses import dataclass, field
@dataclass(order=True)
class Person():
sort_index: int = field(init=False, repr=False)
name: str
age: int
height: float
email: str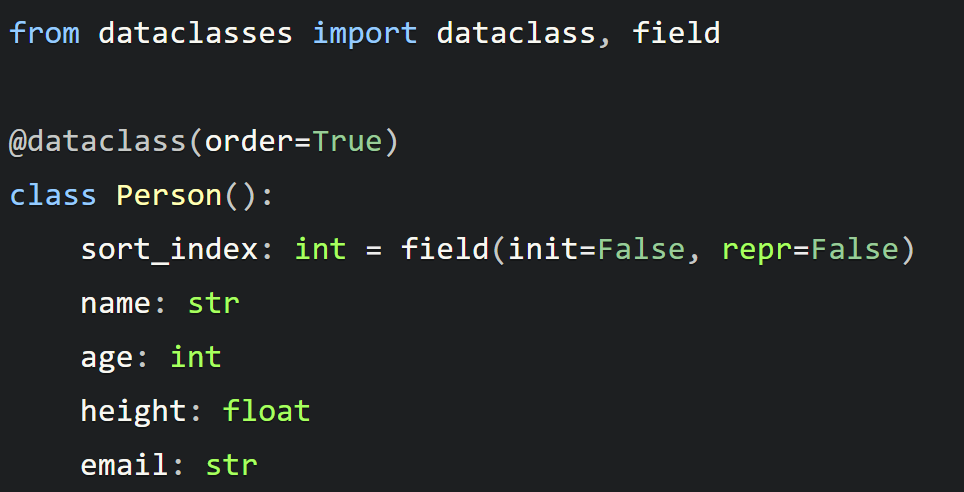
我们传递的两个 False 参数表明该属性不在 init 中,并且在调用 repr 时不应显示。 field 函数中还有其他参数,我们同样可以在官方文档中查看。
在引用这个新属性后,我们将使用第二个新工具: post_int 方法。顾名思义,此方法在 init 方法之后立即执行。我们将使用 post_int 来定义 sort_index ,时间就在在对象创建之后。以一个例子来说明,比如我们想要根据年龄大小来比较人们。方法如下:
就是指定我们如果要比较两个类的话,要依据什么属性进行比较,
而不是按照我们前面展示的例子那样随机从第一个属性往后进行比较。
plain
@dataclass(order=True)
class Person():
sort_index: int = field(init=False, repr=False)
name: str
age: int
height: float
email: str
def __post_init__(self):
self.sort_index = self.age比如说我上面这里指定按照age进行比较,
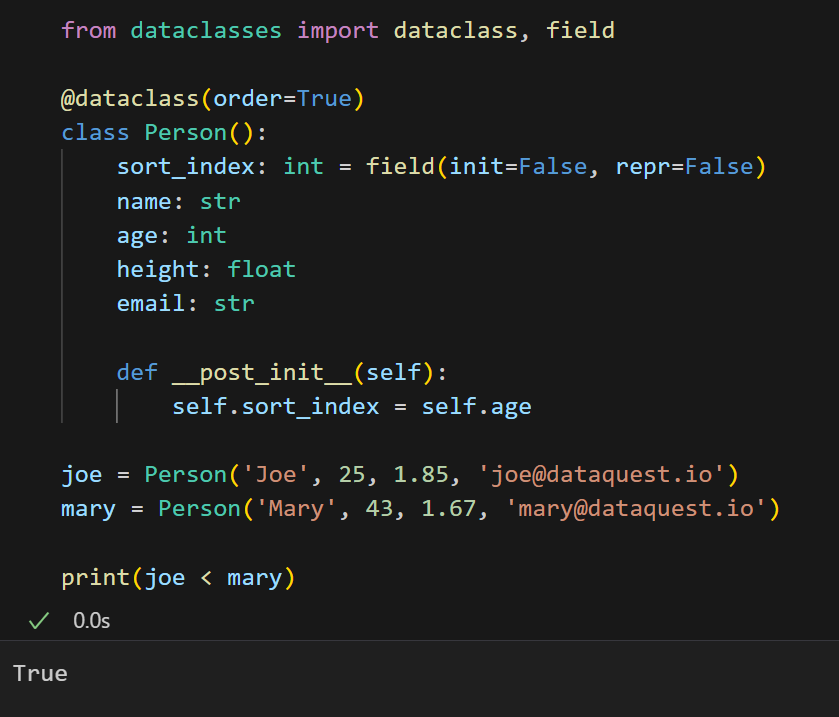
如果是按照身高的数据,就是:
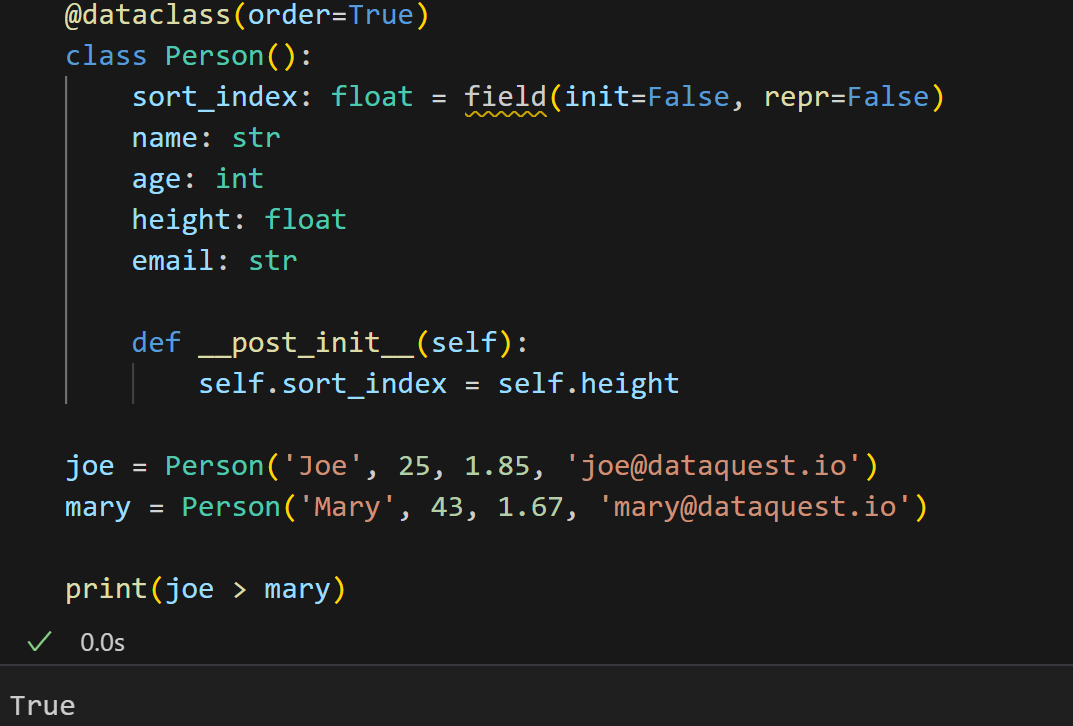
注意,我们上面这里将sort_index设置成了float。
有了上面的方法,我们能够在数据类中实现排序,而无需编写多个方法。
参考:
https://docs.python.org/3/library/dataclasses.html#dataclasses.dataclass
2,处理不可变数据类(Immutable Data Classes)
我们之前提到的 @dataclass 的另一个参数是 frozen 。当设置为 True 时, frozen 不允许我们在对象创建后修改其属性。
使用 frozen=False ,我们可以轻松地执行此类修改:
这个其实就是默认的frozen=False(不显示申明frozen参数时)
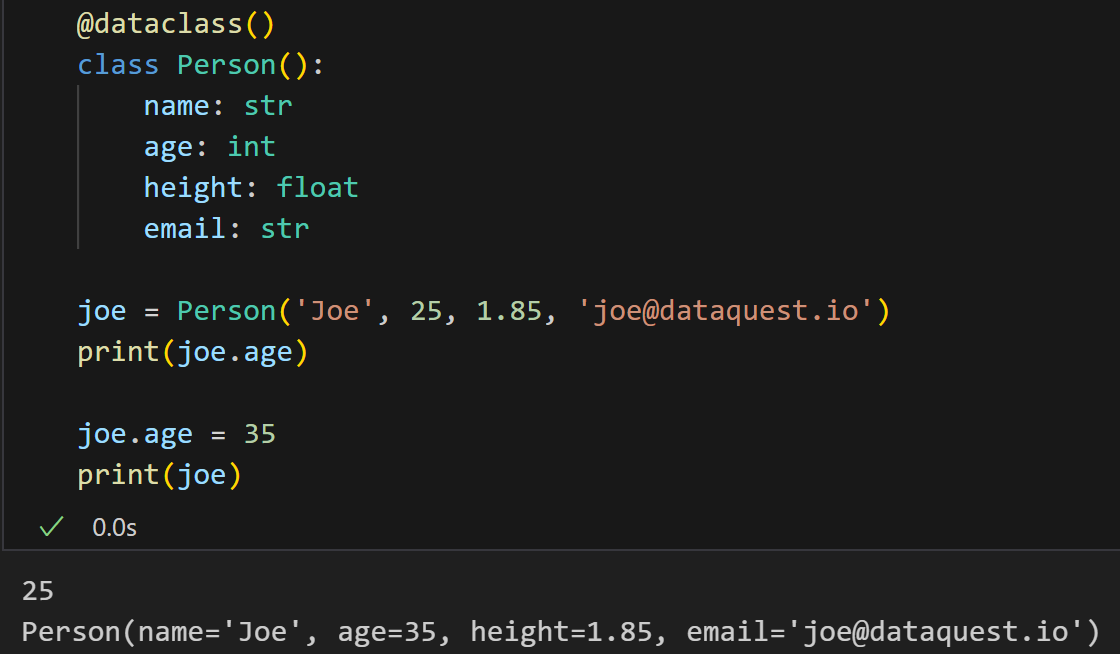
我们创建了一个 Person 对象,然后没有任何问题地修改了 age 属性。
可以联系上一篇博客OOP中给类、对象实例动态赋值属性或方法那部分。
然而,当设置为 True 时,任何尝试修改对象都会抛出错误:
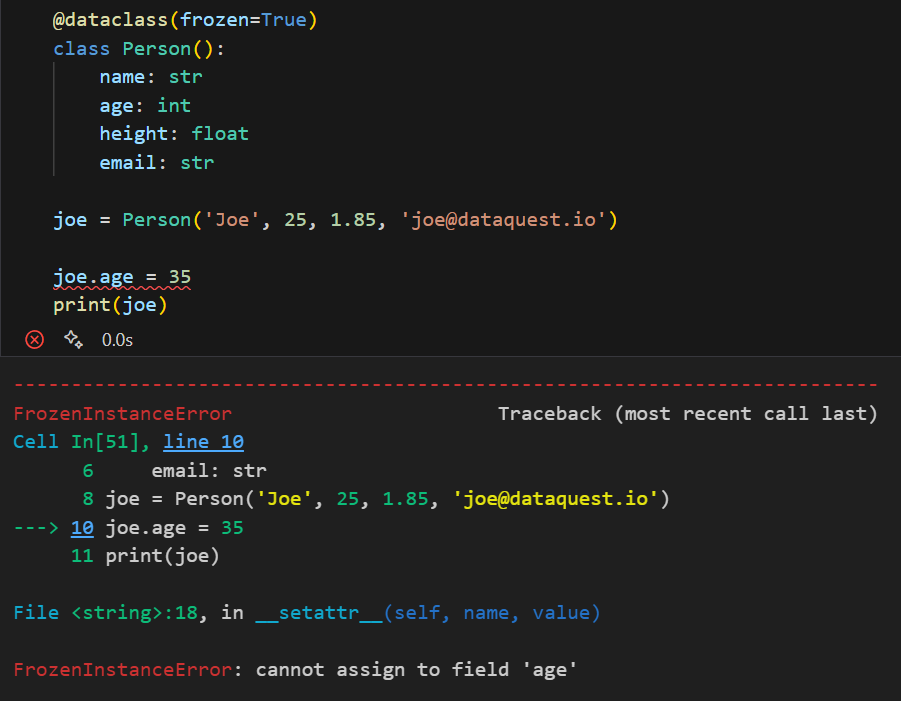
请注意,错误信息显示为 FrozenInstanceError 。
有一个技巧可以修改不可变数据类的值。如果我们的类包含一个可变属性,即使类被冻结,这个属性也可以改变。这个需求可能看起来不合理,但是可以举一个例子:
比如说前面构建的peopel类,用于存储person类实例对象。
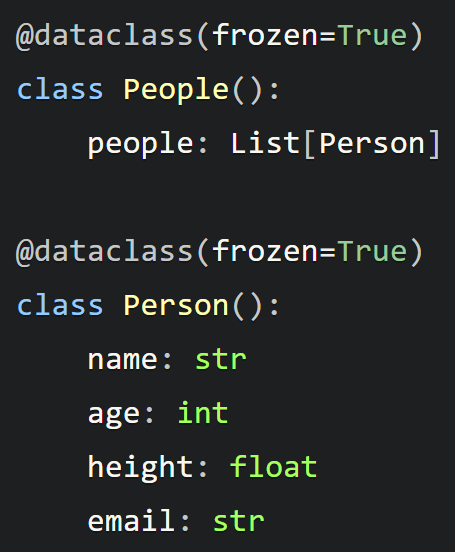
然后我们创建了两个 Person 类的实例,并使用它们来创建一个名为 two_people 的 People 类的实例:
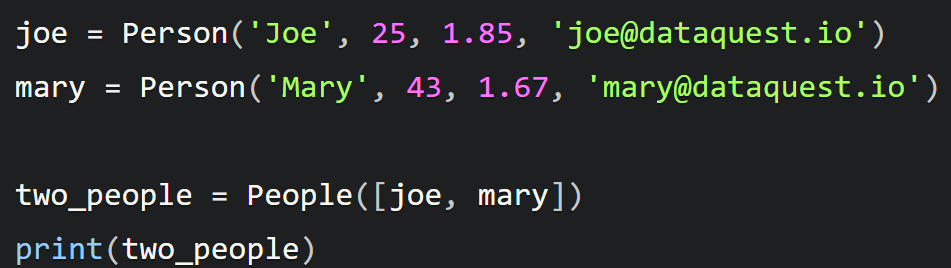
plain
@dataclass(frozen=True)
class People():
people: List[Person]
@dataclass(frozen=True)
class Person():
name: str
age: int
height: float
email: str
joe = Person('Joe', 25, 1.85, 'joe@dataquest.io')
mary = Person('Mary', 43, 1.67, 'mary@dataquest.io')
two_people = People([joe, mary])
print(two_people)people 类中的 People 属性是一个列表。我们可以轻松地在 two_people 对象中通过切片等机制访问这个列表中的值:
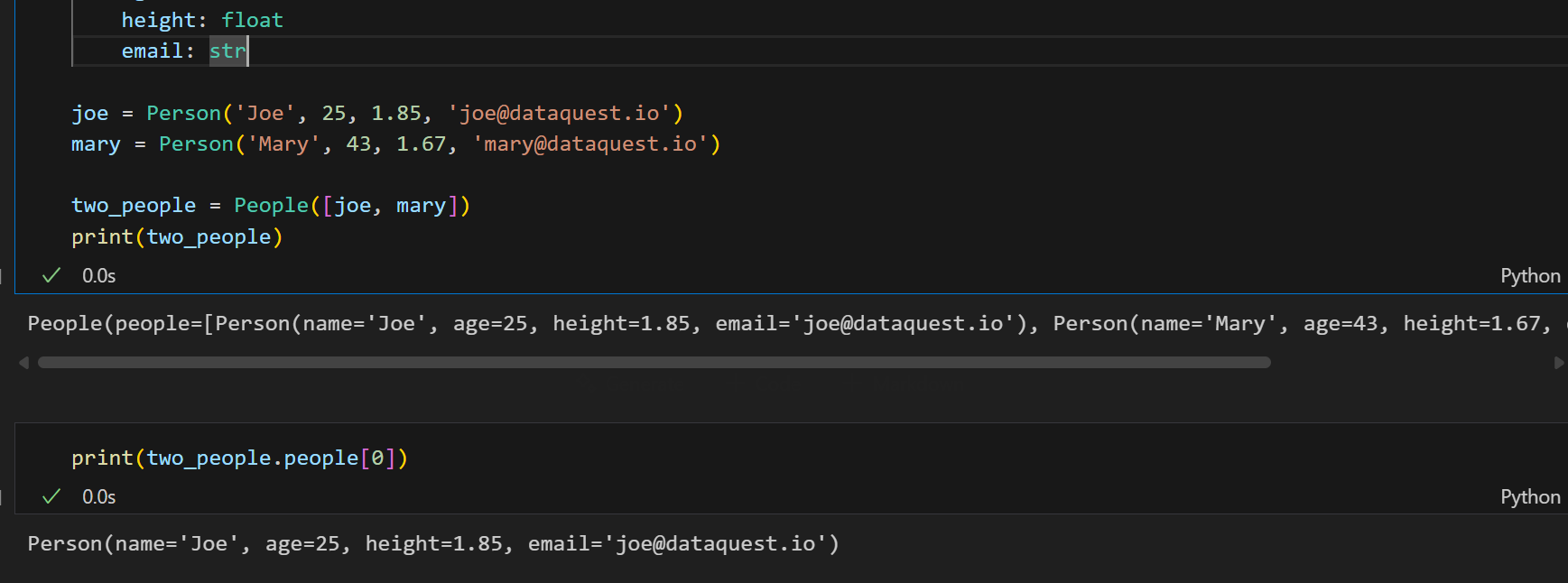
因此,尽管 Person 和 People 类都是不可变的,但列表不是,这意味着我们可以更改其中的值:
这个其实从逻辑上来讲,person类是不可变的,但是list数据类型我们都知道在python中是可变数据类型(就是可以增删修改之类操作);
所以我们本质上其实并没有对person实例进行操作,而是将person实例对象作为元素值,对一个list数据类型进行了操作;
而这个list数据其实是people类的属性,而people类也是我们定义不变frozen的。
这里再讲的通俗一点:就是需要区分这个操作到底修改的是什么,是可变数据类型,
还是不可变类的属性。
- 不可变类(frozen=True)的限制:仅禁止"修改属性引用",不限制"属性内部元素"
当frozen=True时,限制的是"对象创建后修改其属性",具体表现为无法直接替换属性的引用(比如不能把People类的people属性从"列表A"改成"列表B"或"字典"),否则会抛出FrozenInstanceError。但这种限制不会穿透到属性内部------如果属性是列表这类可变类型,修改列表内部的元素(如替换、新增、删除元素),本质上没有改变"people属性指向该列表"的引用关系,因此不触发限制。 - 列表的可变性:独立于类的不可变规则
Python中列表(list)是天生的可变类型,其可变性由自身数据结构决定,与它是否被赋值给"不可变类的属性"无关。People类的people属性被定义为List[Person](列表类型),即便People类被设置为frozen=True,列表本身仍保留"修改内部元素"的特性。比如执行two_people.people[0] = 新Person实例时,只是替换了列表第0位的元素值,two_people.people依然指向原来的列表,并未违反"不可变类不能修改属性引用"的规则。 - 未修改不可变类的实例本身
从操作对象来看,整个过程中并未对Person或People的实例属性做任何修改:既没有试图更改Person实例的name、age等属性(这会触发FrozenInstanceError),也没有替换People实例的people属性引用。这种操作的本质是"用新的Person实例替换列表中的旧元素",属于对"可变列表"的操作,而非对"不可变类实例"的操作,因此完全符合frozen=True的限制逻辑。
另外注意,类的所有属性也应该是不可变的,以便安全地与不可变数据类进行操作。
四,使用dataclass进行继承
dataclasses 模块也支持继承,这意味着我们可以创建一个使用另一个dataclass数据类属性的dataclass数据类。仍然使用我们的 Person 类,我们将创建一个新的 Employee 类,该类继承自 Person 的所有属性。
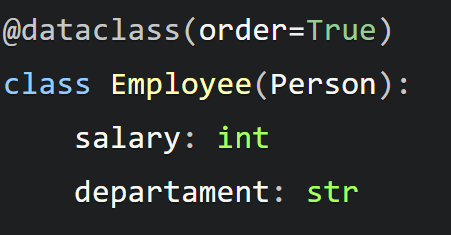
现在我们可以使用 Person 类的所有属性来创建一个 Employee 类的对象:
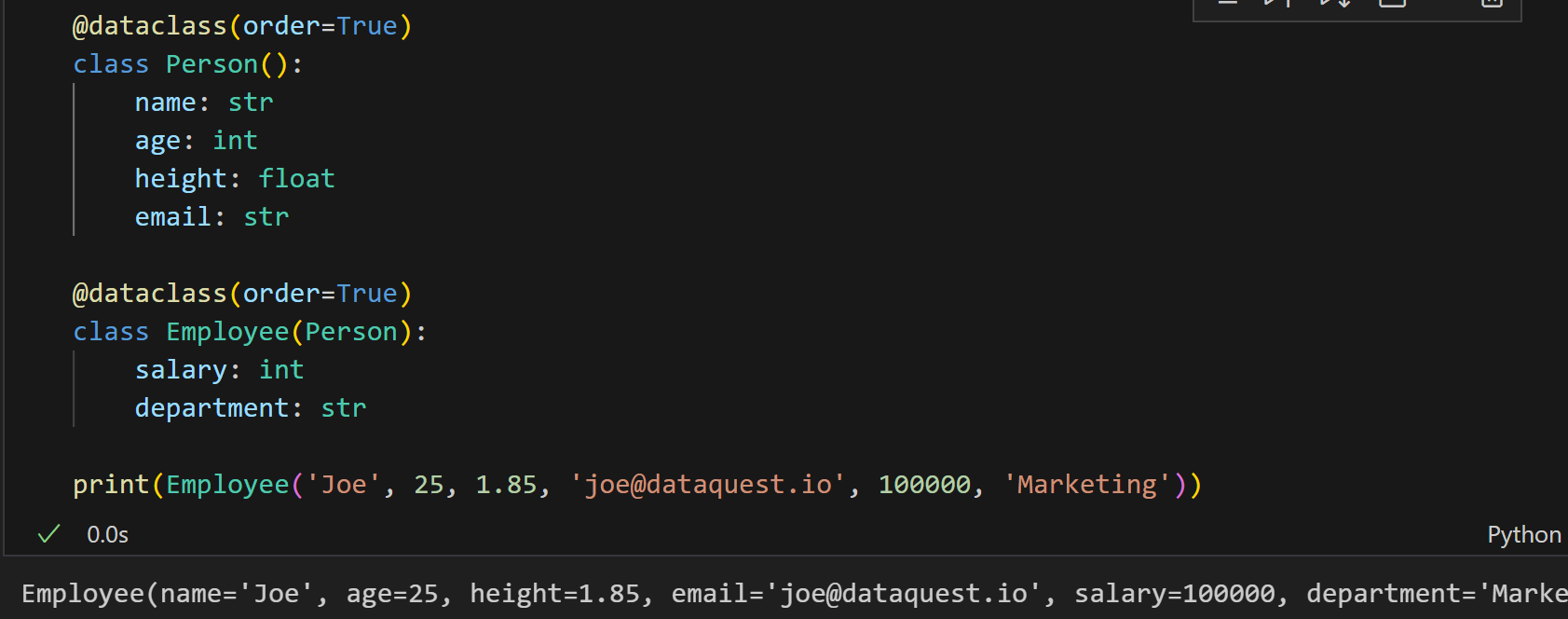
请注意默认属性。假设我们在 Person 中有默认属性,但在 Employee 中没有。在这种情况下,如下面的代码所示,会引发错误:
plain
@dataclass
class Person():
name: str = 'Joe'
age: int = 30
height: float = 1.85
email: str = 'joe@dataquest.io'
@dataclass(order=True)
class Employee(Person):
salary: int
departament: str
print(Employee('Joe', 25, 1.85, 'joe@dataquest.io', 100000, 'Marketing'))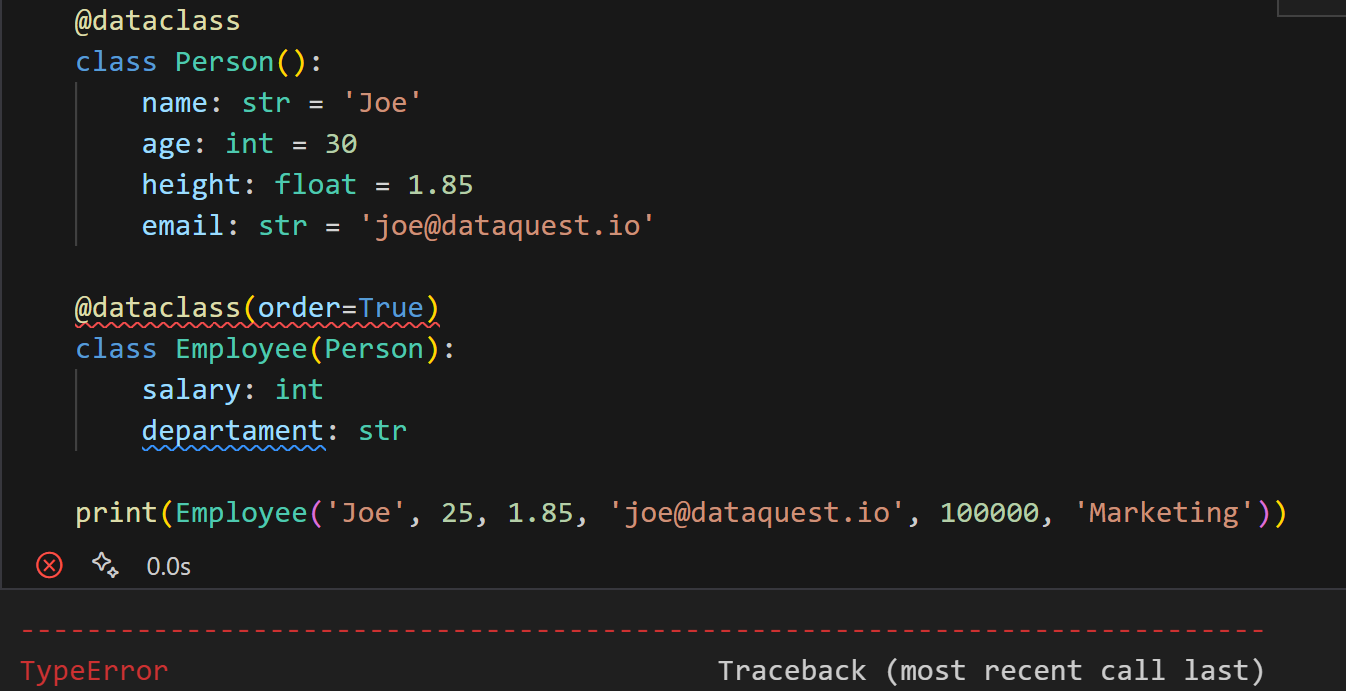

所以,如果基类具有默认属性,那么从该类派生出的所有类中的属性都必须有默认值。
五,总结
dataclasses 模块主要是为了以快速、直观的方式创建数据类,包括以上全文,
我们大致讲了:
- 使用dataclasses定义1个类
- 使用默认属性及其规则
- 创建表示方法repr
- 比较dataclass
- 对dataclass进行sort
- 处理不可变dataclass
参考:
https://docs.python.org/3/library/dataclasses.html
https://docs.python.org/zh-cn/3.13/library/dataclasses.html
https://www.dataquest.io/blog/how-to-use-python-data-classes/