
- 这是篇NIPS2023的 world model 论文
- 文章提出,WM的误差会在训练过程中积累从而影响policy的训练,向WM中加噪声可以改善这一点。
- 其他的流程和IRIS差不多,差别在以下几点:
- image encoder,IRIS用的VQVAE, 本文用的是VAE,用VAE的采样方式来生成zt,从而为zt加噪声。
- sequence model,IRIS用GPT循环输出image的每个token,本文直接用MLP把生成的 z t z_t zt 和动作 a t a_t at 输出成一个token,这样GPT只需要在时序上循环而不需要在同一个 t 内的不同 token 上循环。换句话说,IRIS的一个图片是GPT中的16个token,而STORM的一个图片是GPT中的一个token。
- hidden state,IRIS直接从 z 1 : t z_{1:t} z1:t 预测 z t + 1 z_{t+1} zt+1,相当于RNN,而 STORM先从 z 1 : t z_{1:t} z1:t 预测 h t h_{t} ht,也就是说上面的sequence model输出的不是 z ,而是hidden state h,再用一个MLP从 h t h_t ht来预测 z t + 1 z_{t+1} zt+1,这点是用了Dreamerv3的思路
- loss function,用的也是dreamerv3的loss function
- 完整公式和损失函数如下:

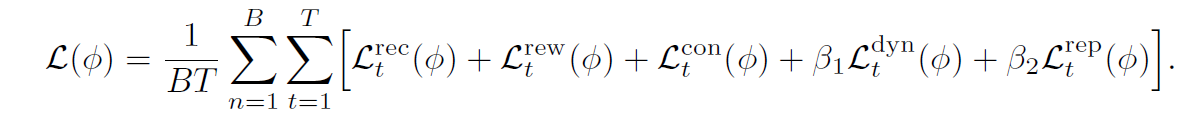
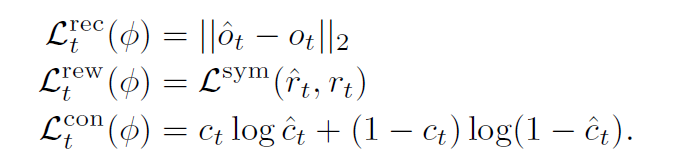
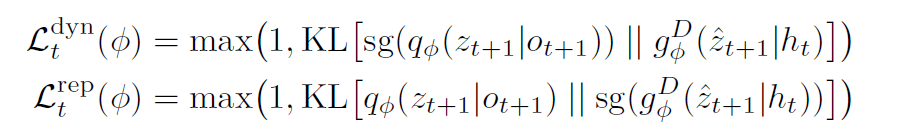
Agent learning
- 强化学习的部分和dreamerv3一样,不过强调了下value函数用的是移动平均:
