Python学习从0开始------Kaggle深度学习002
- 一、单个神经元
-
- 1.深度学习
- 2.线性单元
-
- [示例 - 线性单元作为模型](#示例 - 线性单元作为模型)
- 多个输入
- 3.Keras中的线性单元
- 二、深度神经网络
- 三、随机梯度下降
-
- 1.介绍
- 2.损失函数
- 3.梯度下降法
-
- 1.梯度下降法的基本概念
- 2.数学原理
- 3.梯度下降法的类型
- 4.梯度下降法的缺点:
- [5.学习步长(learning rate)](#5.学习步长(learning rate))
- [4.优化器 - 随机梯度下降](#4.优化器 - 随机梯度下降)
- 5.示例
- 四、过拟合和欠拟合
-
- 1.介绍
- 2.学习曲线
- 3.能力(Capacity)
- [4.提前停止/早停法(Early Stopping)](#4.提前停止/早停法(Early Stopping))
- 5.示例
- 五、丢弃层和批量归一化
-
- 1.丢弃层(Dropout)
- [2.批量归一化(Batch Normalization)](#2.批量归一化(Batch Normalization))
- 3.示例
- 六、二分类
-
- [1.二分类(Binary Classification)](#1.二分类(Binary Classification))
- [2.准确率和交叉熵(Accuracy and Cross-Entropy)](#2.准确率和交叉熵(Accuracy and Cross-Entropy))
- 3.用Sigmoid函数制作概率
- 四、示例
一、单个神经元
1.深度学习
近年来,人工智能领域一些最令人印象深刻的进展是在深度学习领域。自然语言翻译、图像识别和游戏都是深度学习模型接近甚至超过人类水平的任务。那么什么是深度学习呢?
深度学习是一种以深度计算堆栈为特征的机器学习方法。这种深度的计算使深度学习模型能够在最具挑战性的现实世界数据集中发现各种复杂的分层模式。由于其强大的功能和可扩展性,神经网络已经成为深度学习的定义模型。
神经网络由神经元组成,每个神经元单独执行一个简单的计算,神经网络的能力来自于这些神经元可形成连接的复杂性。
2.线性单元
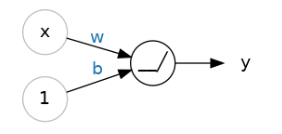
让我们从神经网络的基本组件开始:单个神经元。作为一个图表,一个具有一个输入的神经元(或单元)看起来像这样:
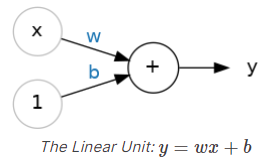
输入是x。它与神经元的连接有一个权重,即w。每当一个值通过连接流动时,你都会将该值乘以连接的权重。对于输入x,到达神经元的是w * x。神经网络通过修改其权重来"学习"。
b是一种特殊的权重,我们称之为偏置。偏置没有与之关联的任何输入数据;相反,我们在图表中放置一个1,以便到达神经元的值只是b(因为1 * b = b)。偏置使神经元能够独立于其输入修改输出。
y是神经元最终输出的值。为了获得输出,神经元将其通过连接接收到的所有值相加。这个神经元的激活函数是y = w * x + b,或者表示为公式 y=wx+b。
示例 - 线性单元作为模型
尽管单个神经元通常只是作为更大网络的一部分来工作,但以一个单独的神经元模型作为基准开始通常是很有用的。单个神经元模型是线性模型。
让我们考虑一下这个模型如何在像"80种麦片"这样的数据集上工作。训练一个以"糖分"(每份的糖克数)作为输入,以"卡路里"(每份的卡路里数)作为输出的模型,我们可能会发现偏置b=90,权重w=2.5。我们可以这样估算每份含有5克糖的麦片的卡路里含量:

根据公式,我们得到卡路里=2.5×5+90=102.5,正如我们所料。
多个输入
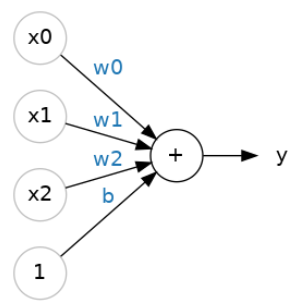
80种谷物的数据集有比"糖"更多的特征。如果我们想扩大我们的模型,把纤维或蛋白质含量也包括进去呢?这很简单。我们可以给神经元添加更多的输入连接,每增加一个特征。为了找到输出,我们将每个输入乘以它的连接权重,然后将它们加在一起:
这个神经元的公式是y=w0x0+w1x1+w2x2+b, 一个有两个输入的线性单位将适合一个平面,一个有更多输入的线性单位将适合一个超平面。
3.Keras中的线性单元
在Keras中创建模型的最简单方法是通过keras.Sequential,它通过将层堆叠在一起来创建神经网络。我们可以使用密集层来创建像上面那样的模型。
我们可以定义一个线性模型,它接受三个输入特征('糖分'、'纤维'和'蛋白质'),并产生一个单一输出('卡路里'),如下所示:
python
from tensorflow import keras
from tensorflow.keras import layers
# 创建一个具有1个线性单元的网络
model = keras.Sequential([
layers.Dense(units=1, input_shape=[3])
])使用第一个参数units,我们定义了想要的输出数量。在这个例子中,我们只是在预测'卡路里',所以我们将使用units=1。
使用第二个参数input_shape,我们告诉Keras输入的维度。设置input_shape=3确保模型将接受三个特征作为输入('糖分'、'纤维'和'蛋白质')。
现在,这个模型已经准备好拟合训练数据了。
二、深度神经网络
1.层
神经网络通常将其神经元组织成层。当我们把具有共同输入集的线性单元组合在一起时,就得到了一个密集层(dense layer)。
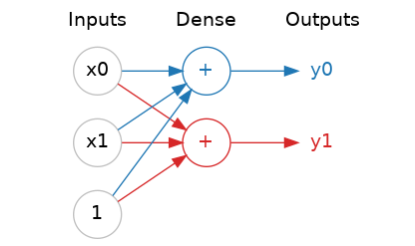
你可以将神经网络中的每一层视为执行某种相对简单的变换。通过多层的堆叠,神经网络可以以越来越复杂的方式转换其输入。在一个训练良好的神经网络中,每一层都是一个转换,使我们离解决方案更近一点。
多种类型的层
在Keras中,"层"是一个非常通用的概念。基本上,层可以是任何类型的数据转换。许多层,如卷积层和循环层,通过神经元的使用来转换数据,主要区别在于它们形成的连接模式。然而,也有其他一些层用于特征工程或只是简单的算术操作。
2.激活函数
然而,事实证明,两个之间没有任何东西的密集层并不比单个密集层本身更好。仅仅密集层本身永远无法让我们摆脱线和平面的世界。我们需要的是一些非线性的元素。我们需要的是激活函数。
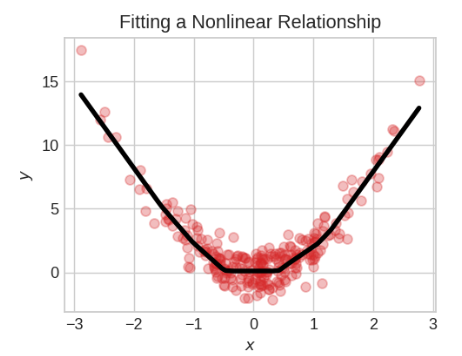
激活函数只是我们应用于层的每个输出(其激活)的某个函数。最常见的是整流函数max(0, x)。
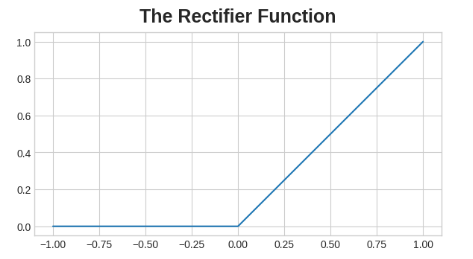
整流函数的图形是一条线,其负部分被"整流"为零。将这个函数应用于神经元的输出会给数据带来一个弯曲,使我们远离简单的直线。
当我们将整流器附加到线性单元时,我们得到了一个整流线性单元或ReLU(Rectified Linear Unit)。(因此,通常将整流函数称为"ReLU函数"。)将ReLU激活应用于线性单元意味着输出变为max(0, w * x + b),我们可以用以下图表来表示:
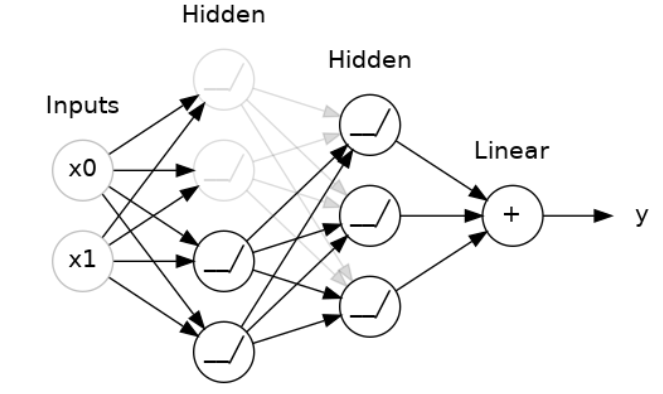
3.堆叠密集层
堆叠层以获得复杂的数据转换:
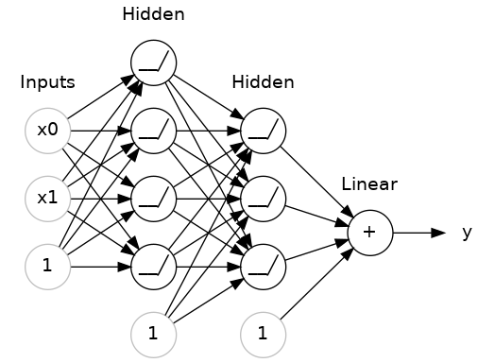
在输出层之前的层有时被称为隐藏层,因为我们永远不会直接看到它们的输出。
现在,请注意,最终(输出)层是一个线性单元(意味着没有激活函数)。这使得这个网络适用于回归任务,即我们试图预测一些任意的数值。其他任务(如分类)可能需要在输出层上应用激活函数。
在堆叠密集层时,我们通常会逐渐增加层的复杂性,以便让网络能够学习数据中的更高级特征。同时,选择合适的激活函数和层的大小(即神经元数量)对于网络的性能至关重要。
4.构建Sequential模型
我们一直在使用的Sequential模型会按顺序将层连接在一起:第一层接收输入,最后一层产生输出。这创建了上面图中的模型:
python
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# 输入层,4个神经元,ReLU激活函数,接收2个特征的输入
layers.Dense(units=4, activation='relu', input_shape=[2]),
# 隐藏层,3个神经元,ReLU激活函数
layers.Dense(units=3, activation='relu'),
# 输出层,1个神经元(没有激活函数,适合回归问题)
layers.Dense(units=1),
])请确保将所有层作为列表一起传递,如layer, layer, layer, ...,而不是作为单独的参数。要给层添加激活函数,只需在activation参数中指定其名称即可。
三、随机梯度下降
1.介绍
与所有机器学习任务一样,我们从一组训练数据开始。训练数据中的每个示例都由一些特征(输入)和预期目标(输出)组成。训练网络意味着调整其权重,使其能够将特征转化为目标。例如,在80种谷物的数据集中,我们想要一个网络,它可以获取每种谷物的"糖"、"纤维"和"蛋白质"含量,并对该谷物的"卡路里"进行预测。如果我们可以成功地训练一个网络来做到这一点,它的权重必须以某种方式表示这些特征和训练数据中表达的目标之间的关系。除了训练数据,我们还需要两个东西:一个衡量网络预测好坏的"损失函数"。一个"优化器",可以告诉网络如何改变它的权重。
2.损失函数
我们已经看到了如何为网络设计架构,但还没有看到如何告诉网络要解决什么问题。这是损失函数的职责。
损失函数衡量目标真实值与模型预测值之间的差异。
不同的问题需要不同的损失函数。我们一直在看回归问题,其任务是预测一些数值------如80种谷物的卡路里含量、红酒质量的评分。其他回归任务可能是预测房屋的价格或汽车的燃油效率。
回归问题的一个常见损失函数是平均绝对误差(MAE)。对于每个预测值y_pred,MAE通过绝对差abs(y_true - y_pred)来衡量与真实目标y_true的差异。
数据集上的总MAE损失是所有这些绝对差异的平均值。
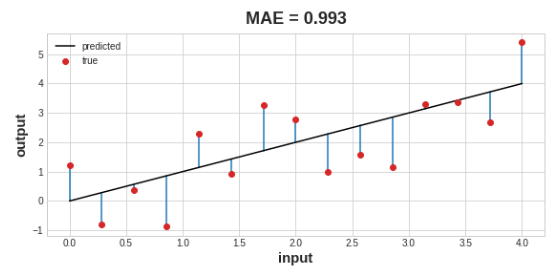
除了MAE之外,你还可能在回归问题中看到的其他损失函数是均方误差(MSE)或Huber损失(两者都在Keras中可用)。
在训练过程中,模型将使用损失函数作为指导来找到其权重的正确值(损失越低越好)。换句话说,损失函数告诉网络它的目标是什么。
3.梯度下降法
我们已经描述了我们希望网络解决的问题,但现在我们需要说明如何解决它。这是优化器的职责。优化器是一种算法,用于调整权重以最小化损失。
深度学习中使用的几乎所有优化算法都属于随机梯度下降(SGD)家族。它们是迭代算法,分步骤训练网络。一次训练步骤是这样的:
- 从训练数据中抽取一些样本并通过网络进行预测。
- 测量预测值与真实值之间的损失。
- 最后,调整权重以减小损失。
然后重复这个过程,直到损失达到你希望的小值(或者直到它无法再减小)。每次迭代抽取的训练数据样本称为小批量(或小批量,minibatch),而训练数据的完整轮次称为一个周期(epoch)。你训练的周期数决定了网络将看到每个训练样本的次数。
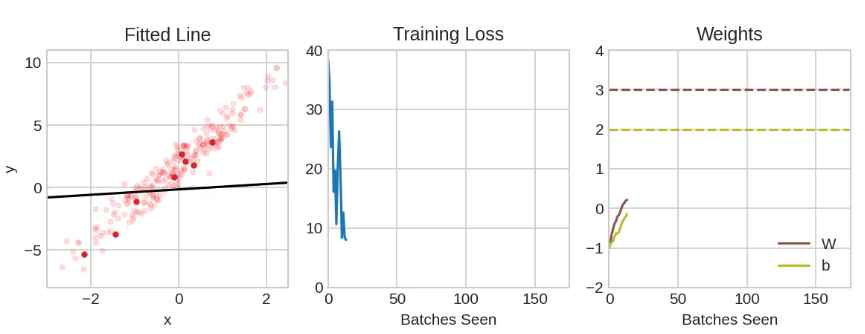
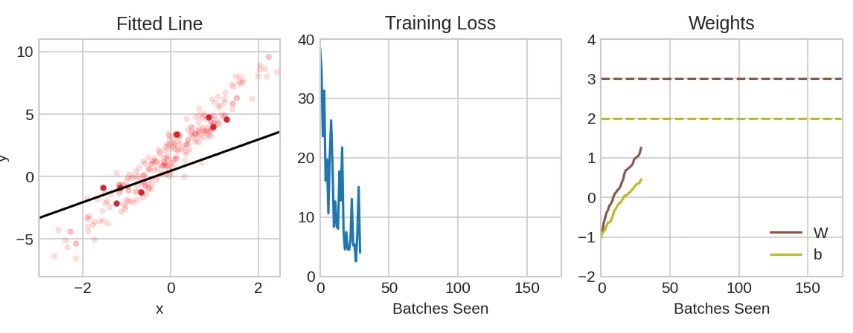
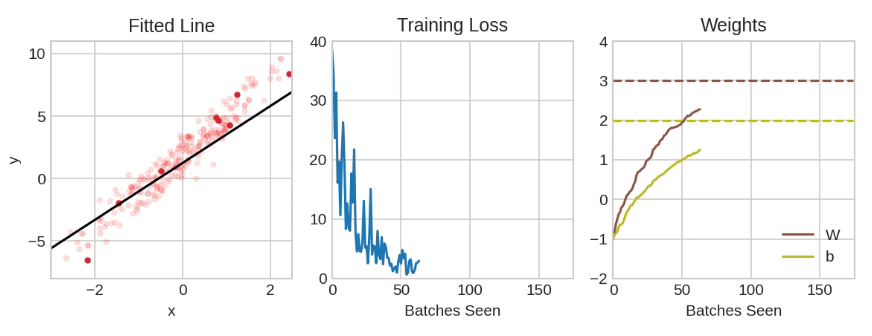
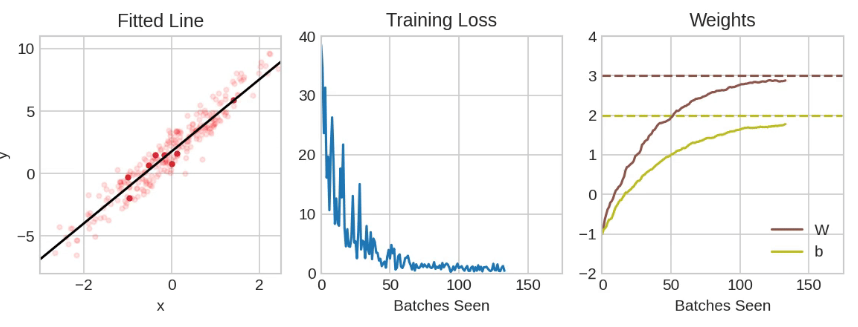
以上展示了使用SGD训练的线性模型。淡红色的点表示整个训练集,而实心的红点表示小批量。每次SGD看到一个新的小批量时,它都会将权重(w表示斜率,b表示y轴截距)向该批量的正确值移动。经过一批又一批的数据,线最终收敛到最佳拟合。你可以看到,随着权重接近其真实值,损失变得越来越小。
1.梯度下降法的基本概念
梯度下降法是一种常用的优化算法,用于求解最小化目标函数的问题。在机器学习和深度学习中,梯度下降法被广泛应用于求解模型参数的优化问题,例如线性回归、逻辑回归、神经网络等1。它的基本思想是通过不断迭代,使目标函数的值逐步趋近于最小值。这种方法的核心是利用目标函数的梯度信息,即函数在当前点的斜率,来指导下一步的移动方向和步长。
2.数学原理
假设有一个目标函数f(x),其中x是一个d维向量,即x=(x1,x2,...,xd)T。我们的目标是求解该函数的最小值,即:minf(x)。为了实现这个目标,我们需要计算目标函数在当前点x处的梯度,即:∇f(x)=(∂f(x)/∂x1,∂f(x)∂x2,...,∂f(x)/∂x)T。梯度是一个向量,它的方向指向函数在当前点上升最快的方向,即函数的斜率最大的方向,而它的大小表示函数在当前点上升的速度。梯度下降法的核心思想是沿着梯度的负方向移动,以达到函数值的最小化。
3.梯度下降法的类型
梯度下降法主要包括三种类型:随机梯度下降法(SGD)、批量梯度下降法(BGD)和小批量梯度下降法(MBGD)。
批量梯度下降法:使用整个训练集来计算梯度,并更新模型参数。由于需要计算所有样本的梯度,计算复杂度较高,但通常能够保证收敛到全局最优解。
随机梯度下降法:每次迭代只使用一个样本来计算梯度并更新模型参数。这种方法计算速度快,但可能会引入噪声,导致模型参数在最优解附近震荡。
小批量梯度下降法:每次迭代使用一小批样本来计算梯度并更新模型参数。这种方法结合了批量梯度下降法和随机梯度下降法的优点,既保证了计算速度,又减少了噪声的影响。
4.梯度下降法的缺点:
梯度下降法也存在一些缺点,如靠近局部极小值时速度减慢、直线搜索可能会产生一些问题、可能会"之字型"地下降等。
5.学习步长(learning rate)
学习步长是一个较小的正数,用于调节参数的更新速度,使模型参数更容易收敛。如果学习步长过大,可能会导致模型在最优解附近震荡;如果学习步长过小,则可能会导致模型收敛速度过慢。
4.优化器 - 随机梯度下降
学习率和批量大小
请注意,线条在每个批量方向上只进行小的移动(而不是一步到位)。这些移动的幅度由学习率决定。较小的学习率意味着网络需要看到更多的小批量数据,其权重才能收敛到最佳值。
学习率和批量大小是影响SGD训练过程的两个最重要的参数。它们之间的交互往往是微妙的,而且这些参数的正确选择并不总是明显的。
幸运的是,对于大多数工作来说,进行广泛的超参数搜索以获得满意的结果并不是必要的。Adam是一种SGD算法,它具有自适应学习率,这使得它适合大多数问题而无需进行任何参数调整(在某种意义上,它是"自调优"的)。Adam是一个很好的通用优化器。
添加损失函数和优化器
在定义模型之后,你可以使用模型的compile方法添加损失函数和优化器:
python
model.compile(
optimizer="adam",
loss="mae",
)请注意,我们只需要使用字符串就能指定损失函数和优化器。如果你想要调整参数,例如,你也可以直接通过Keras API访问这些。但对于我们来说,默认设置就足够好了。
名字的由来
梯度是一个向量,它告诉我们权重需要朝哪个方向移动。更准确地说,它告诉我们如何改变权重以使损失变化最快。我们称之为梯度下降,是因为它使用梯度沿着损失曲线下降以找到最小值。"随机"意味着"由机会决定"。我们的训练是随机的,因为小批量是从数据集中随机抽取的样本。这就是为什么它被称为SGD(随机梯度下降)!
5.示例
使用红酒质量数据集。该数据集由大约1600种葡萄牙红酒的理化测量数据组成。此外还包括盲品测试对每款葡萄酒的质量评级。我们将每个特征重新缩放到区间0,1,当神经网络的输入在一个共同的尺度上时,它们往往表现得最好:
python
import pandas as pd
from IPython.display import display
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
# 创建训练和验证分割
df_train = red_wine.sample(frac=0.7, random_state=0)
df_valid = red_wine.drop(df_train.index)
display(df_train.head(4))
# 缩放到[0,1]
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
# 拆分特征和目标
X_train = df_train.drop('quality', axis=1)
X_valid = df_valid.drop('quality', axis=1)
y_train = df_train['quality']
y_valid = df_valid['quality']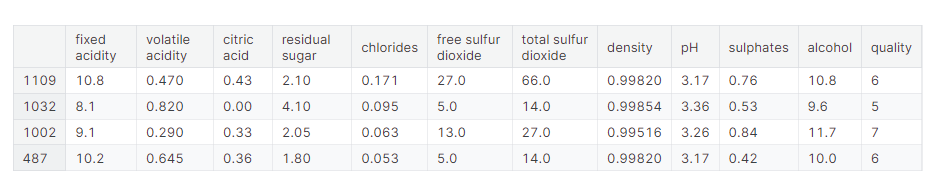
我们选择了一个有超过1500个神经元的三层网络。这个网络应该能够学习数据中相当复杂的关系:
python
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)确定模型的体系结构应该是流程的一部分。从简单开始,并使用验证丢失作为指导。在定义模型后,我们在优化器和损失函数中进行了编译。
然后,开始训练,告诉Keras一次向优化器提供256行训练数据(batch_size),并在整个数据集(epoch)中执行10次:
python
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=10,
)
-------------------------输出---------------------------
Epoch 1/10
5/5 [==============================] - 1s 66ms/step - loss: 0.2470 - val_loss: 0.1357
Epoch 2/10
5/5 [==============================] - 0s 21ms/step - loss: 0.1349 - val_loss: 0.1231
Epoch 3/10
5/5 [==============================] - 0s 23ms/step - loss: 0.1181 - val_loss: 0.1173
Epoch 4/10
5/5 [==============================] - 0s 21ms/step - loss: 0.1117 - val_loss: 0.1066
Epoch 5/10
5/5 [==============================] - 0s 22ms/step - loss: 0.1071 - val_loss: 0.1028
Epoch 6/10
5/5 [==============================] - 0s 20ms/step - loss: 0.1049 - val_loss: 0.1050
Epoch 7/10
5/5 [==============================] - 0s 20ms/step - loss: 0.1035 - val_loss: 0.1009
Epoch 8/10
5/5 [==============================] - 0s 20ms/step - loss: 0.1019 - val_loss: 0.1043
Epoch 9/10
5/5 [==============================] - 0s 19ms/step - loss: 0.1005 - val_loss: 0.1035
Epoch 10/10
5/5 [==============================] - 0s 20ms/step - loss: 0.1011 - val_loss: 0.0977可以看到,随着模型的运行,Keras将向您提供最新的损失信息。通常,观察损失的更好方法是绘制它。fit方法实际上在History对象中保存训练期间产生的损失的记录。我们将把数据转换为Pandas数据框架,这样便于绘图:
python
import pandas as pd
# 将培训历史记录转换为数据框
history_df = pd.DataFrame(history.history)
# 采用Pandas的原生plot方法
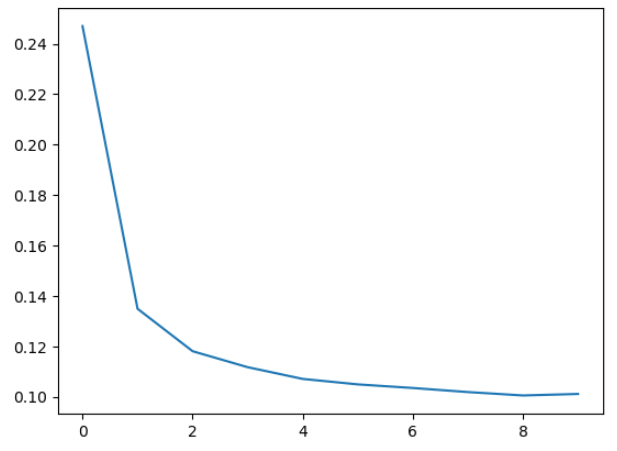
history_df['loss'].plot();请注意,随着时间的推移,损失是趋于平稳的。当损失曲线变得像那样水平时,这意味着模型已经学会了它所能做的一切,没有理由继续进行额外的时代。
四、过拟合和欠拟合
1.介绍
回想三中Keras将在训练模型的各个时期保留训练和验证损失的历史记录。接下来介绍如何解释这些学习曲线,以及如何使用它们来指导模型开发。特别是我们将在学习曲线上检查欠拟合和过拟合,并研究一些纠正它的策略。
2.学习曲线
在训练数据中,信息可以被分为两类:信号和噪声。信号是那些能够泛化的部分,即模型可以利用它们来对新数据进行预测的部分。噪声则是仅与训练数据相关的部分,它包括了现实世界中数据的随机波动或那些偶然、非信息性的模式,这些模式实际上并不能帮助模型进行预测。噪声是那些看起来有用但实际上不是的部分。
我们通过选择权重或参数来训练模型,以最小化训练集上的损失。然而,要准确评估模型的性能,我们需要在新的数据集(验证集)上评估它。通过比较训练集和验证集上的损失曲线(学习曲线),我们可以获得关于模型性能的深入见解。
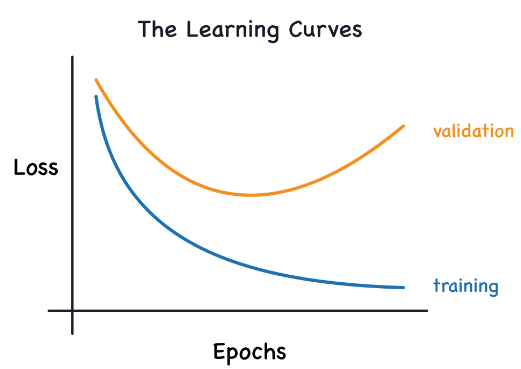
在训练过程中,训练损失会在模型学习信号或噪声时下降。但是,验证损失仅在模型学习信号时下降(因为模型从训练集中学习到的噪声不会泛化到新的数据上)。因此,当模型学习信号时,两条曲线都会下降,但当它学习噪声时,曲线之间会出现差距。这个差距的大小告诉我们模型学习了多少噪声。
理想情况下,我们希望创建仅学习信号而不学习任何噪声的模型。但在实践中,这几乎是不可能的。相反,我们需要做出权衡。我们可以让模型以学习更多噪声为代价来学习更多信号。只要这个权衡对我们有利,验证损失就会继续下降。然而,在某个点之后,权衡可能会对我们不利,即学习噪声的代价超过了学习信号的益处,这时验证损失就会开始上升。
因此,通过观察训练集和验证集上的损失曲线,我们可以判断模型是否开始过度拟合(即学习过多噪声),并据此调整模型参数或采取其他措施来防止过度拟合。
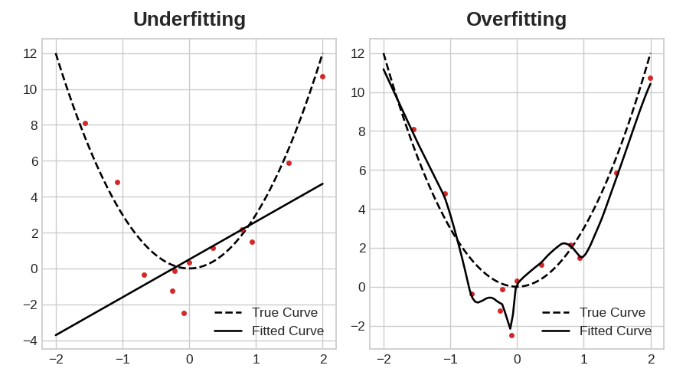
这种权衡表明,在训练模型时可能会出现两个问题:信号不足或噪声过多。欠拟合训练集是指由于模型没有学习到足够的信号,损失没有达到预期的低水平。训练集的过拟合是指由于模型学习了太多的噪声,损失没有达到预期的那么低。训练深度学习模型的诀窍是在两者之间找到最佳平衡。
我们将看看从训练数据中获得更多信号同时减少噪声的几种方法。
3.能力(Capacity)
模型的能力是指它能够学习的模式的大小和复杂性。对于神经网络来说,这在很大程度上取决于它有多少神经元以及它们是如何连接在一起的。如果您的网络似乎无法适应数据,您应该尝试增加其容量。
可以通过使其更宽(在现有层上增加更多单元)或使其更深(增加更多层)来增加网络的容量。更广的网络更容易学习线性关系,而更深的网络更喜欢非线性关系,哪个更好取决于数据集:
python
model = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(1),
])
wider = keras.Sequential([
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
deeper = keras.Sequential([
layers.Dense(16, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(1),
])4.提前停止/早停法(Early Stopping)
我们提到,当模型过于急切地学习噪声时,验证损失可能会在训练期间开始增加。为了防止这种情况,只要验证损失不再减少,我们就可以简单地停止训练。以这种方式中断训练被称为提前停止。
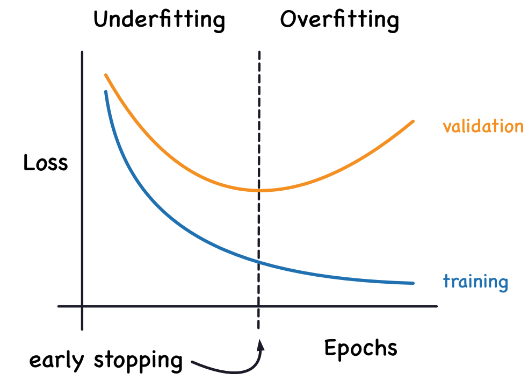
一旦我们检测到验证损失开始再次上升,我们可以将权重重置到最小损失发生时的状态。这确保了模型不会继续学习噪声并导致过拟合。
使用提前停止训练也意味着我们不太可能在网络还没有完全学习到信号之前就过早地停止训练。因此,除了防止因训练时间过长而导致的过拟合外,提前停止还可以防止因训练时间不足而导致的欠拟合。只需将训练周期设置为一个较大的数字(超过你需要的数量),提前停止会处理其余部分。
添加早停法
在Keras中,我们通过回调函数(callback)在训练过程中加入早停法。回调函数就是在网络训练过程中你希望定期运行的函数。早停法回调函数会在每个周期(epoch)结束后运行。(Keras已经预定义了许多有用的回调函数,但你也可以定义自己的回调函数。)
python
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
min_delta=0.001, # 验证损失最小改进量,达到这个值才认为有改进
patience=20, # 在停止之前等待多少个周期
restore_best_weights=True, # 如果在训练过程中发现更好的模型,则将其权重保存
)这些参数的意思是:"如果在过去的20个周期中,验证损失至少没有改善0.001,则停止训练并保留你找到的最佳模型。"有时很难判断验证损失上升是由于过拟合还是仅仅由于随机批次变化。这些参数允许我们设置一些何时停止的阈值。
在我们的示例中,我们将把这个回调函数传递给fit方法,同时传递损失函数和优化器。
5.示例
继续使用三中的数据集,现在让我们增加网络的容量。我们将使用一个相当大的网络,但是一旦验证损失显示出增加的迹象,就依靠回调来停止训练:
python
from tensorflow import keras
from tensorflow.keras import layers, callbacks
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # 作为改进的最小变化量
patience=20, # 要等多少次才能停止
restore_best_weights=True,
)
model = keras.Sequential([
layers.Dense(512, activation='relu', input_shape=[11]),
layers.Dense(512, activation='relu'),
layers.Dense(512, activation='relu'),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)定义回调后,将其作为参数添加到fit中(您可以有多个参数,因此将其放入列表中)。当使用提前停止时,选择大量的epoch,超过你需要的:
python
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=500,
callbacks=[early_stopping], # 把你的回调放在一个列表里
verbose=0, # 关闭培训日志
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();
print("Minimum validation loss: {}".format(history_df['val_loss'].min()))
--------------------------输出------------------------------
Minimum validation loss: 0.09269220381975174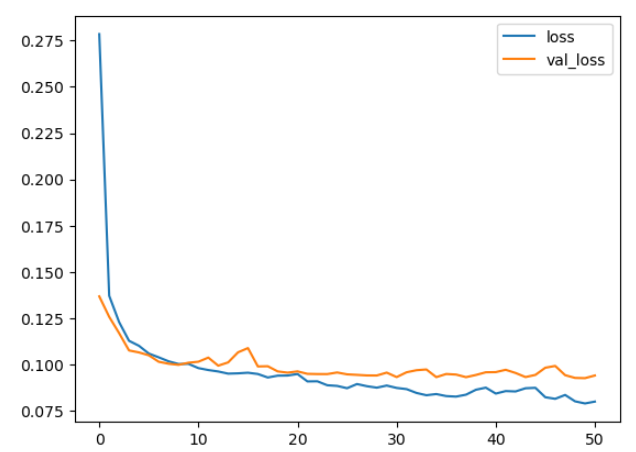
五、丢弃层和批量归一化
1.丢弃层(Dropout)
"丢弃层"可以帮助纠正过拟合,在四中,我们讨论了过拟合是由于网络学习训练数据中的虚假模式造成的。为了识别这些虚假模式,网络通常会依赖于非常特定的权重组合,一种特定的团体。由于这种特异性,它们往往很脆弱:去掉一个权重,这种团体就会瓦解。
丢弃层背后的想法正是如此。为了打破这些团体,我们在训练的每一步中随机丢弃层的一部分输入单元,这使得网络很难学习训练数据中的那些虚假模式。相反,它必须寻找广泛、一般的模式,其权重模式往往更加健壮。
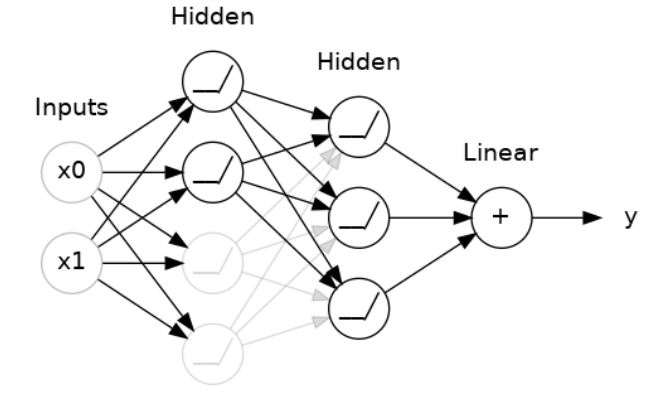
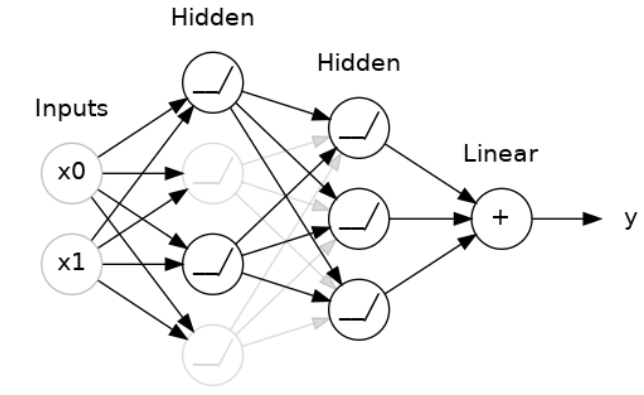
你也可以将丢弃层看作是创建了一种网络集合。预测将不再由一个大型网络进行,而是由一组较小的网络组成的委员会进行。委员会中的每个成员都倾向于犯不同类型的错误,但同时又正确,这使得委员会作为一个整体比任何个体都更好。(如果你熟悉随机森林作为决策树的集合,这就是同样的想法。)
添加丢弃层
在Keras中,dropout rate参数rate定义了要关闭的输入单元的百分比。将Dropout图层放在你想要应用Dropout的图层前面:
python
keras.Sequential([
# ...
layers.Dropout(rate=0.3), # 在下一层应用30%的丢弃
layers.Dense(16),
# ...
])2.批量归一化(Batch Normalization)
我们将看到的下一个特殊层执行"批规范化"(或"batchnorm"),它可以帮助纠正缓慢或不稳定的训练。对于神经网络,将所有数据放在一个共同的尺度上通常是一个好主意,也许使用像scikit-learn的StandardScaler或MinMaxScaler这样的东西。原因是SGD将根据数据产生的激活大小成比例地转移网络权重。倾向于产生不同大小的激活的特征会导致不稳定的训练行为。
现在,如果在数据进入网络之前对其进行规范化是好的,那么在网络内部进行规范化可能会更好。事实上,我们有一种特殊的层可以做到这一点,批量归一化层。
批量归一化层在每个批处理进入时查看它,首先用它自己的平均值和标准批量归一化,然后用两个可训练的重新缩放参数将数据放在一个新的尺度上。实际上,Batchnorm对其输入执行一种协调的重新缩放。
在大多数情况下,添加batchnorm是作为优化过程的辅助(尽管它有时也可以帮助预测性能)。使用批量归一化的模型往往需要更少的时间来完成训练。此外,batchnorm还可以解决各种可能导致培训"卡住"的问题。考虑将批处理规范化添加到模型中,特别是在训练过程中遇到问题时。
添加批量归一化
python
layers.Dense(16, activation='relu'),
layers.BatchNormalization(),
#或者
layers.Dense(16),
layers.BatchNormalization(),
layers.Activation('relu'),3.示例
python
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(1024, activation='relu', input_shape=[11]),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1024, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(1),
])
model.compile(
optimizer='adam',
loss='mae',
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=256,
epochs=100,
verbose=0,
)
# 展示学习曲线
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot();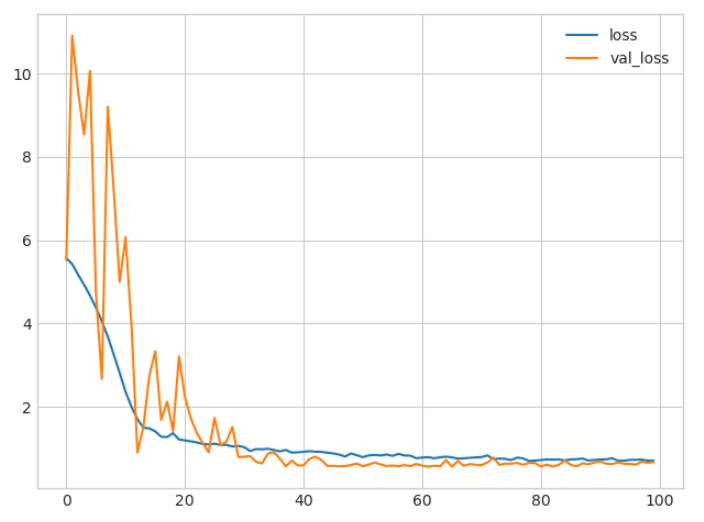
六、二分类
1.二分类(Binary Classification)
将事物划分为两个类别是常见的机器学习问题。你可能想要预测一个客户是否可能进行购买,一个信用卡交易是否欺诈,深空信号是否显示新行星存在的证据,或者医疗测试是否表明疾病存在。这些问题都是二分类问题。
在原始数据中,类别可能由字符串表示,如"是"和"否",或者"狗"和"猫"。在使用这些数据之前,我们将为它们分配一个类别标签:一个类别将被标记为0,另一个将被标记为1。分配数字标签将数据转化为神经网络可以使用的形式。
2.准确率和交叉熵(Accuracy and Cross-Entropy)
准确率是评估分类问题成功程度的众多指标之一。准确率是正确预测数与总预测数的比率:准确率 = 正确数 / 总数。一个始终预测正确的模型将具有1.0的准确率得分。在其他条件相同的情况下,当数据集中的类别出现频率大致相同时,准确率是一个合理的指标。
准确率(以及大多数其他分类指标)的问题在于,它不能用作损失函数。随机梯度下降(SGD)需要一个变化平滑的损失函数,但准确率作为计数之比,其变化是"跳跃式"的。因此,我们必须选择一个替代品作为损失函数。这个替代品就是交叉熵函数。
现在回想一下,损失函数定义了网络在训练过程中的目标。对于回归问题,我们的目标是使预期结果和预测结果之间的距离最小化。我们选择了平均绝对误差(MAE)来衡量这个距离。
对于分类问题,我们想要的是概率之间的距离,这正是交叉熵所提供的。交叉熵是一种衡量从一个概率分布到另一个概率分布距离的方法。
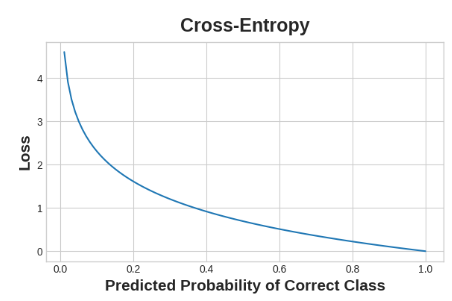
这个想法是,我们希望我们的网络以1.0的概率预测正确的类。预测概率离1.0越远,交叉熵损失越大。我们使用交叉熵的技术原因有点微妙,使用交叉熵来处理分类损失;你可能关心的其他指标(如准确性)也会随之提高。
3.用Sigmoid函数制作概率
交叉熵和准确率函数都需要以概率作为输入,也就是说,数值应该在0到1之间。为了将密集层产生的实值输出转换为概率,我们附加了一种新的激活函数,即sigmoid激活函数。
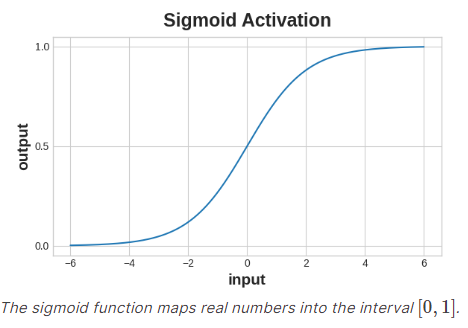
为了获得最终的类别预测,我们定义了一个阈值概率。通常这个阈值会是0.5,这样四舍五入就能给出正确的类别:低于0.5意味着标签为0的类别,0.5或以上则意味着标签为1的类别。在使用准确率指标时,Keras默认使用0.5作为阈值。
四、示例
以电离层数据集为例:
python
import pandas as pd
from IPython.display import display
ion = pd.read_csv('../input/dl-course-data/ion.csv', index_col=0)
display(ion.head())
df = ion.copy()
df['Class'] = df['Class'].map({'good': 0, 'bad': 1})
df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)
max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)
df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
df_train.dropna(axis=1, inplace=True) # drop the empty feature in column 2
df_valid.dropna(axis=1, inplace=True)
X_train = df_train.drop('Class', axis=1)
X_valid = df_valid.drop('Class', axis=1)
y_train = df_train['Class']
y_valid = df_valid['Class']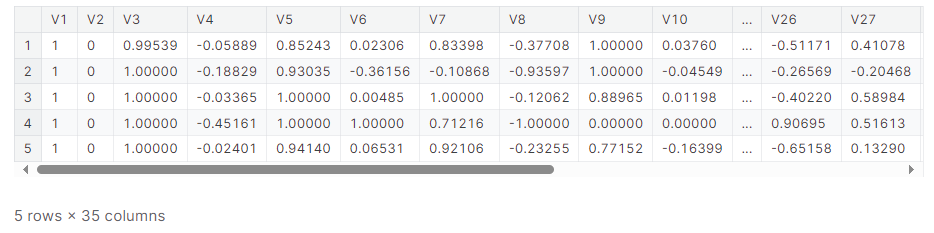
我们将定义我们的模型,就像我们为回归任务所做的那样,但有一个例外。在最后一层包含一个"sigmoid"激活,这样模型将产生类概率:
python
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(4, activation='relu', input_shape=[33]),
layers.Dense(4, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])在模型的编译方法中加入了交叉熵损失和精度度量。对于两类问题,请确保使用二分类版本。(其它类别的问题会略有不同。)Adam优化器在分类方面也很有效,所以我们将继续使用它:
python
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)这个特定问题中的模型可能需要相当多的时间来完成训练,因此为了方便,我们将包含一个提前停止回调:
python
early_stopping = keras.callbacks.EarlyStopping(
patience=10,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=1000,
callbacks=[early_stopping],
verbose=0, # hide the output because we have so many epochs
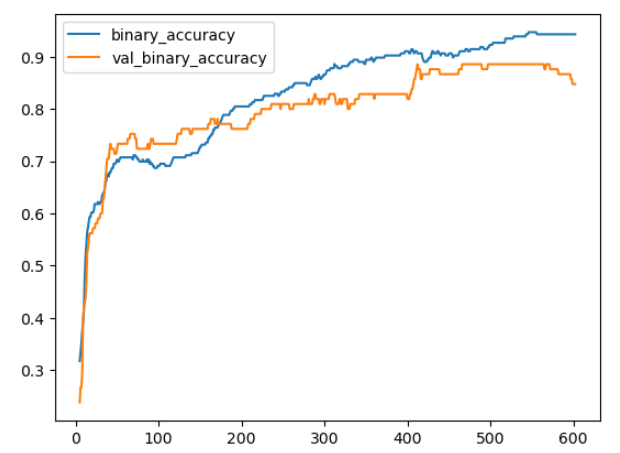
)我们将一如既往地查看学习曲线,并检查我们在验证集上获得的损失和准确性的最佳值。(请记住,提前停止将恢复获得这些值的权重。):
python
history_df = pd.DataFrame(history.history)
history_df.loc[5:, ['loss', 'val_loss']].plot()
history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()
print(("Best Validation Loss: {:0.4f}" +\
"\nBest Validation Accuracy: {:0.4f}")\
.format(history_df['val_loss'].min(),
history_df['val_binary_accuracy'].max()))
-----------------------------输出----------------------------------------
Best Validation Loss: 0.3534
Best Validation Accuracy: 0.8857