在工单系统上看到有一条SQL问题还没解决,直接联系这位同学看看是否需要帮忙。
慢SQL:
UPDATE A
SET CORPORATION_NAME = (
SELECT DISTINCT CORPORATION_NAME
FROM (
SELECT CONTRACT_NO,
COOP_SERVICE_TYPE,
CORPORATION_NAME,
PROJECT_NAME,
ROW_NUMBER() OVER (PARTITION BY CONTRACT_NO, COOP_SERVICE_TYPE ) AS SEQ
FROM O_PLIS_PROC B
WHERE B.BDHA_TX_DATE='2024-06-10' AND A.LM_CT1_NO = B.CONTRACT_NO
) B
WHERE B.COOP_SERVICE_TYPE='01' AND B.SEQ = 1
)
WHERE LM_CT1_NO IN (
SELECT CONTRACT_NO
FROM O_PLIS_PROC C
WHERE C.CONTRACT_NO=A.LM_CT1_NO
AND C.COOP_SERVICE_TYPE='01'
AND C.BDHA_TX_DATE='2024-06-10'
);执行计划:
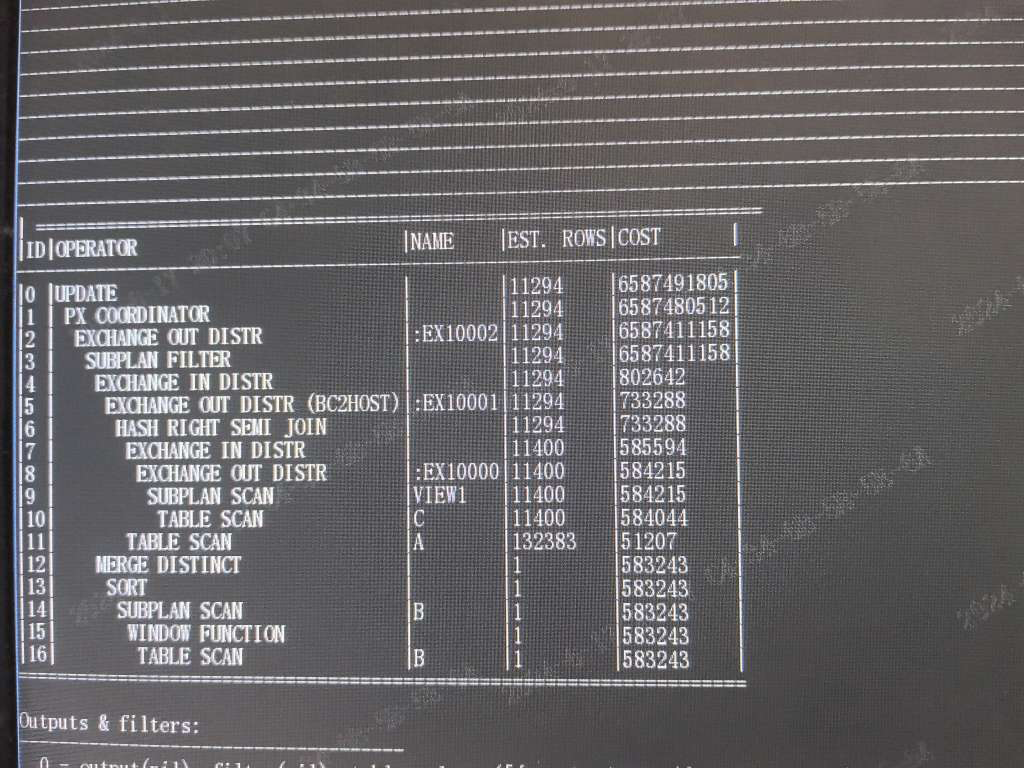
上面sql 跑超时都跑不出结果,估计要执行非常长时间。
这条sql in 后面关联返回107911行数据,update set ... 可以理解成标量子查询,返回1107911数据相当于 update set 标量子查询也要执行107911次。
标量子查询最重要的是要走对索引,然而这个sql计划根本没走索引,这位同学的问题也是如何通过改写来消除标量子查询,很明显这个思路是错误的。
添加合适的索引:
CREATE INDEX TEST ON O_PLIS_PROC(
BDHA_TX_DATE,
COOP_SERVICE_TYPE,
CONTRACT_NO,
COOP_SERVICE_TYPE,
CORPORATION_NAME);
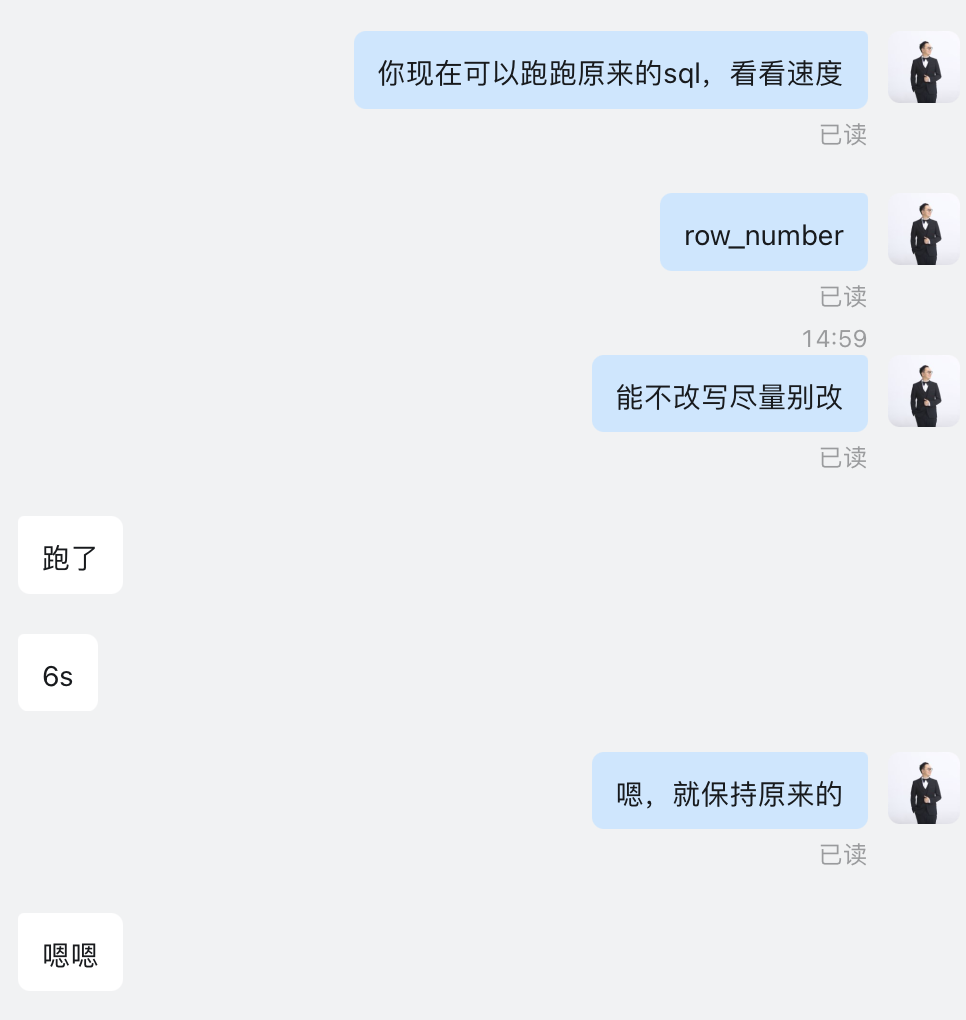
很明显,创建索引以后计划显示能用上索引,sql整体5秒能执行完成。
再提供个相同逻辑的等价改写方案:
WITH O_PLIS_PROC as (
SELECT
CONTRACT_NO,
COOP_SERVICE_TYPE,
CORPORATION_NAME
FROM O_PLIS_PROC
WHERE BDHA_TX_DATE='2024-06-10' AND COOP_SERVICE_TYPE='01'
)
UPDATE A
SET CORPORATION_NAME = (
SELECT CORPORATION_NAME
FROM O_PLIS_PROC B
WHERE A.LM_CT1_NO = B.CONTRACT_NO GROUP BY CONTRACT_NO, COOP_SERVICE_TYPE LIMIT 1 )
WHERE LM_CT1_NO IN (
SELECT CONTRACT_NO
FROM O_PLIS_PROC C
WHERE C.CONTRACT_NO=A.LM_CT1_NO
);
改写后的sql 5秒能跑出结果,和原来逻辑一样,提升不大。
遇到性能慢的sql语句,不要一上来就想着等价改写,先通过索引进行优化,合理的索引能解决90%的性能问题。
如果索引都解决不了的情况下,才去尝试使用等价改写来进行优化sql,一般来说等价改写能解决剩下5%的问题。
如果连等价改写都解决不了剩下的5%的性能问题话,就要尝试改业务,或者改数据库技术栈来解决问题了,这种通常来说成本会非常高。