NLP课程设计-基于实体识别的智能任务系统
- 前言
- 一、数据获取可行性分析和需求分析
-
- [1. 数据获取可行性分析](#1. 数据获取可行性分析)
- [2. 需求分析](#2. 需求分析)
- 二、程序主要NLP技术
-
- [2.1 文本分类技术](#2.1 文本分类技术)
- [2.2 中文命名实体识别](#2.2 中文命名实体识别)
-
- [2.2.1 BiLSTM(双向长短期记忆网络)](#2.2.1 BiLSTM(双向长短期记忆网络))
- [2.2.2 CRF(条件随机场)](#2.2.2 CRF(条件随机场))
- [2.2.3 BiLSTM+CRF的结合](#2.2.3 BiLSTM+CRF的结合)
- 三、程序设计
- 四、运行结果
- 五、对比试验
前言
在人工智能与自然语言处理技术飞速发展的今天,构建一个能够理解和处理自然语言的智能任务系统成为了计算机科学领域的一项重要挑战。本课程设计旨在通过实践教学,深入掌握 自然语言处理(NLP) 的关键技术和应用,同时培养解决复杂工程问题的能力。
本课程设计的核心目标是开发一个能够通过自然语言处理技术,帮助用户高效管理各种任务的系统。系统需要具备任务识别和分类、实体抽取、任务管理以及用户交互等核心功能。为了实现这些功能,我们采用了先进的深度学习模型,如 双向长短期记忆网络(BiLSTM) 结合条件随机场(CRF) ,以及 隐马尔可夫模型(HMM) 等,对用户输入的自然语言文本进行深入分析和处理。
在实训过程中,不仅要学习理论知识,还要通过实际操作来应用这些知识,包括数据的获取与预处理、算法的描述与实现、系统的模块化设计以及模型的评估与优化等。此外,学生还需运用工程管理方法进行项目的时间管理、质量管理、沟通管理和风险管理,并对项目的成本及预期收益进行分析。
通过本课程设计:
- 理解并应用自然语言处理的核心技术。
- 设计并实现一个高效、可扩展的智能任务系统。
- 掌握项目管理和团队协作的技能。
- 分析和解决在系统开发过程中遇到的技术难题。
本报告详细记录了从项目分析、系统设计、算法实现到模型评估的全过程,展现了学生在自然语言处理领域的实践能力和创新思维。通过本次实训,我们期待学生能够将所学知识应用于更广泛的领域,为智能任务系统的发展贡献自己的力量。
一、数据获取可行性分析和需求分析
1. 数据获取可行性分析
为了构建一个高效的智能任务系统,获取适合的语料库是至关重要的一步。语料库的质量和多样性直接影响系统的性能和准确度。在本项目中,我们选择利用ChatGPT来辅助生成和获取语料库,这具有以下几个优点:
高效性:ChatGPT能够快速生成大量高质量的自然语言文本,覆盖各种任务类型和场景。
多样性:通过不同的提示和上下文设置,ChatGPT可以生成内容丰富、风格多样的文本,确保语料库的多样性和代表性。
可控性:利用ChatGPT生成语料库,可以根据具体需求进行调整和优化,例如特定任务类型的重点覆盖。
可扩展性:生成的语料库可以随着项目需求的变化进行扩展和更新,保持系统的前瞻性和适用性。
基于以上优势,我们确定采用ChatGPT作为主要的数据获取工具,辅以少量的人工校对和调整,以保证语料库的质量。
独有数据集(对于任务型语句的处理)
2. 需求分析
智能任务系统旨在通过自然语言处理技术,帮助用户高效管理各种任务。因此,系统需要具备以下核心功能:
任务识别和分类:能够准确识别用户的需求,并将其分类为不同类型的任务,如定闹钟、查天气等。
实体抽取:从用户的自然语言输入中抽取出关键的实体信息,如时间、地点、任务名称等,以便后续任务的执行。
任务管理:支持用户设置任务的优先级、截止日期和状态,并能够自动提醒用户完成任务。
用户交互:提供友好且智能的用户交互界面,使用户能够便捷地创建、跟踪和管理任务。
3系统模块划分:
数据获取和预处理模块:利用ChatGPT生成和收集语料库,涵盖各种任务类型和场景。使用正则表达式清洗转化成所需数据集。
文本分类模块:基于机器学习或深度学习技术,训练模型以识别和分类用户任务。
实体识别模块:选择合适的实体识别方法,从用户输入中抽取出关键实体。
任务处理模块:根据识别出的任务类型和实体内容,生成相应的任务设定。
任务管理模块:提供用户管理任务的界面和功能,支持任务提醒和状态跟踪。
二、程序主要NLP技术
2.1 文本分类技术
文本分类是自然语言处理领域中的一项基础技术,它使得计算机能够理解文本数据的语义,并将其归类到预定义的类别中。在本项目中,文本分类模块扮演着至关重要的角色,它能够将用户的自然语言指令转换为系统可以理解的任务类型,从而触发相应的处理流程。
文本分类模块采用深度学习模型,循环神经网络(RNN),对文本特征进行学习和分类。模型包括嵌入层和全连接层,嵌入层将文本索引序列映射到低维向量表示,全连接层则将这些向量映射到分类标签空间。
2.2 中文命名实体识别
BiLSTM+CRF(双向长短期记忆网络结合条件随机场)是一种先进的自然语言处理模型,广泛应用于序列标注任务,如命名实体识别(NER)。该模型结合了深度学习中的双向长短期记忆网络(BiLSTM)和传统机器学习中的条件随机场(CRF)两种技术的优势,以实现更准确的序列预测。
2.2.1 BiLSTM(双向长短期记忆网络)
BiLSTM是RNN(循环神经网络)的一种变体,它通过双向处理数据,能够同时捕捉到输入序列中前后文的信息。这种网络结构包含前向和后向两个LSTM层,分别处理序列的过去和未来信息,并将这些信息融合在一起,为每个时间步生成一个综合的特征表示。
2.2.2 CRF(条件随机场)
CRF是一种统计建模方法,用于序列数据的标注问题。它考虑了标签之间的依赖关系,通过定义状态转移概率来优化整个序列的标注。CRF层通常位于BiLSTM之后,它接受BiLSTM的输出,并寻找一个标签序列,使得整个序列的联合概率最大。
2.2.3 BiLSTM+CRF的结合
将BiLSTM和CRF结合起来,可以充分利用BiLSTM强大的特征提取能力以及CRF在序列标注上的优化能力。BiLSTM首先为序列中的每个元素生成特征表示,然后CRF层基于这些特征和定义的转移概率,通过维特比算法找到最优的标签序列。
三、程序设计
3.1 使用工具
开发环境和工具
PyCharm:
用途:作为主要的集成开发环境(IDE),用于编写、调试和运行代码。
特点:提供了强大的代码补全、代码重构、调试工具和版本控制支持,极大地提高了开发效率和代码质量。
Jupyter Notebook:
用途:用于算法的调试和数据处理的辅助开发工具。
特点:提供了交互式编程环境,方便快速测试和验证代码片段,以及进行数据可视化。
编程语言
Python:
用途:作为项目的主要编程语言,用于实现程序的核心逻辑和各个功能模块。
特点:拥有丰富的标准库和第三方库,简洁易读,适合快速开发和原型设计。
第三方库和框架
PyQt5:
用途:用于创建图形用户界面(GUI)。
特点:提供了丰富的控件和布局管理器,可以构建复杂的桌面应用程序界面,支持嵌入网页内容、多媒体功能以及与网页内容的交互,适合开发现代化的桌面应用程序。
PyTorch:
用途:用于构建和训练深度学习模型,特别是在命名实体识别(NER)和文本分类任务中。
特点:
灵活性:PyTorch 采用动态图计算模式,允许动态地构建和修改计算图,方便调试和开发。
丰富的API:提供了丰富的神经网络层、优化器、损失函数等工具,使得构建和训练深度学习模型更加便捷。
强大的社区支持:拥有活跃的社区和丰富的文档资源,便于开发者解决问题和提升技能。
GPU加速:支持GPU加速计算,可以显著提高深度学习模型的训练和推理速度。
在本项目中,PyTorch 被用于实现以下功能:
BiLSTM-CRF 模型:用于命名实体识别(NER),帮助提取用户输入中的关键信息,如时间、地点、任务等。
文本分类模型:用于对用户输入进行分类,确定其意图,如设置闹钟、播放音乐、查询天气等。
四、运行结果
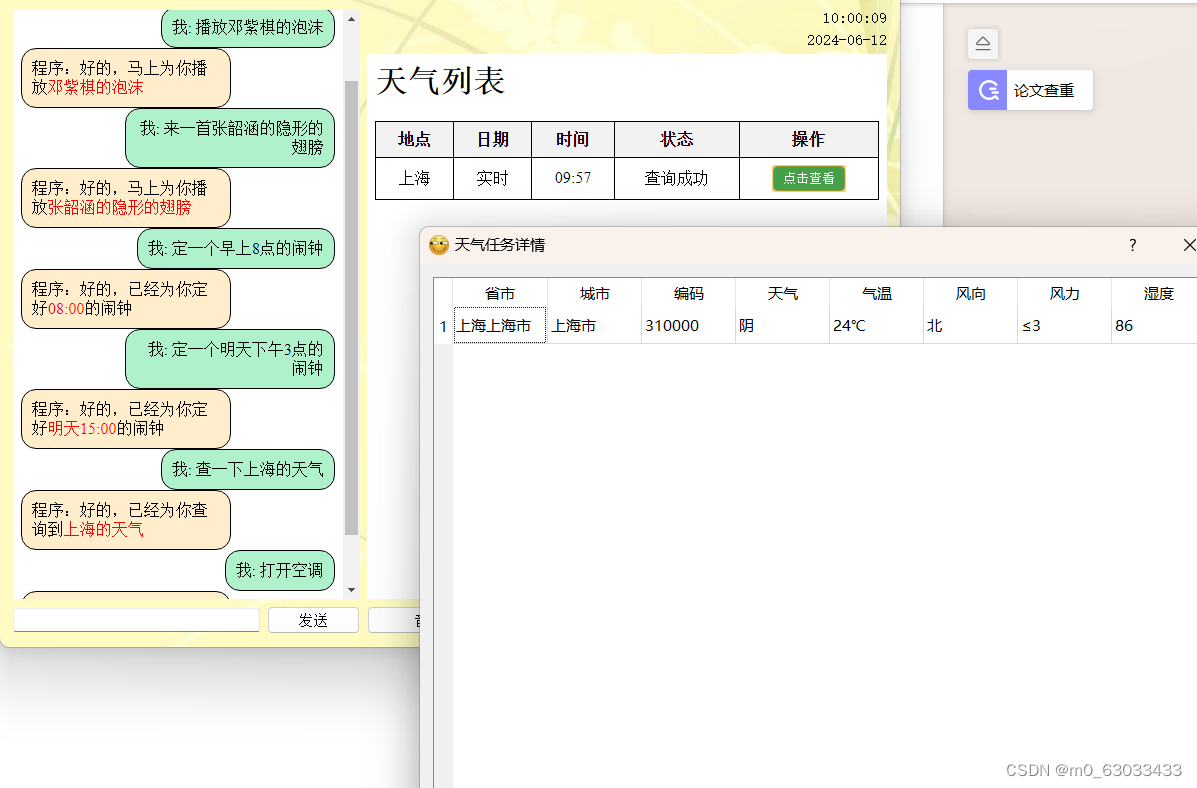
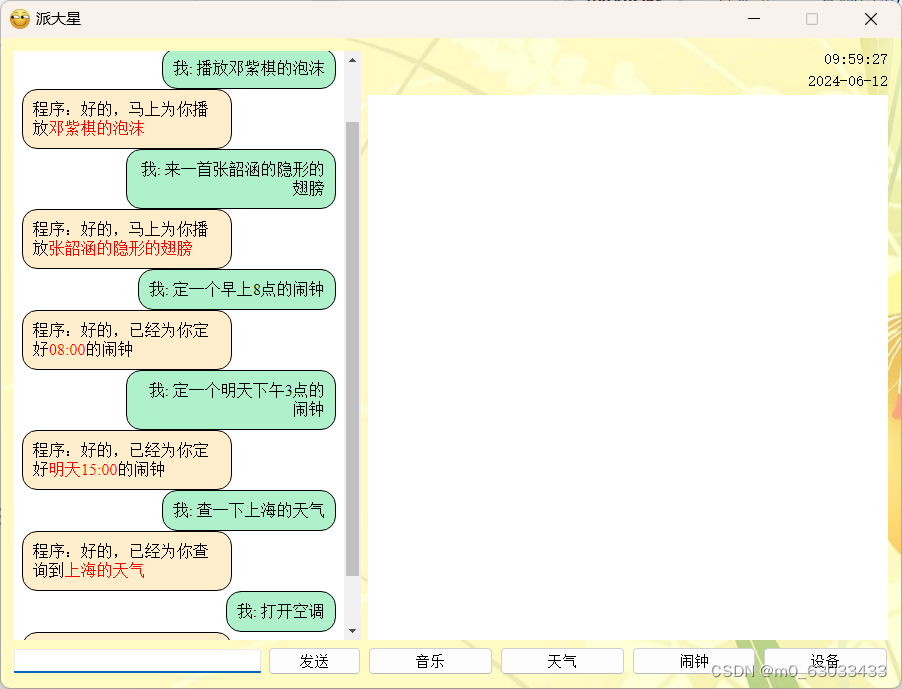
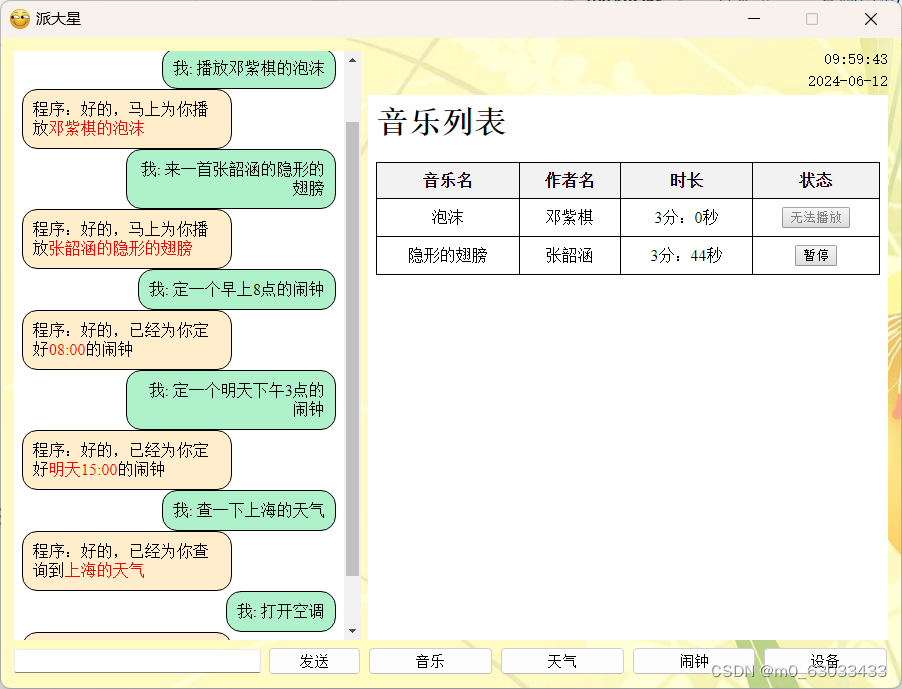
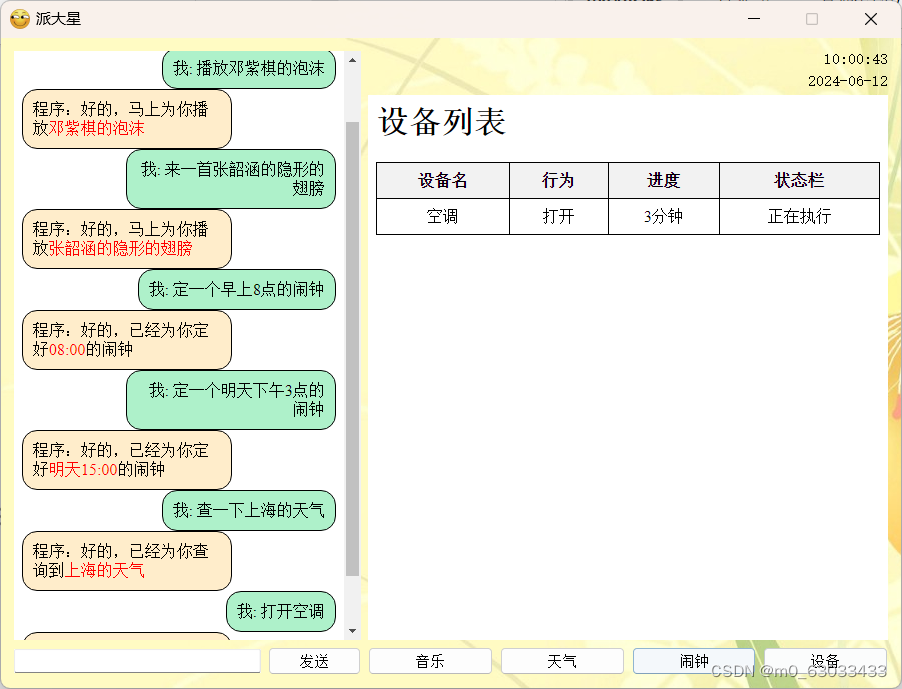
五、对比试验
BiLSTM模型

HMM模型
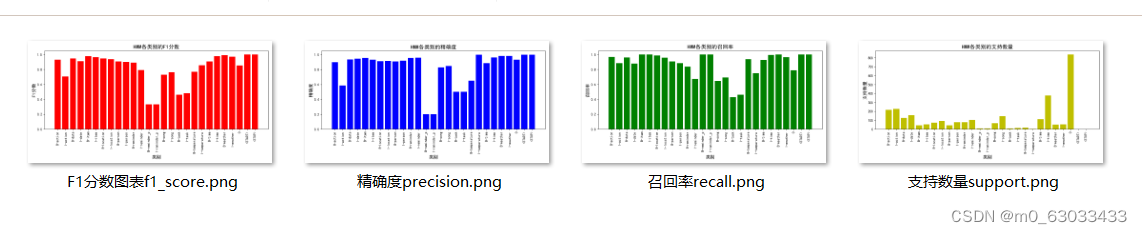
CRF模型