激活函数是深度学习模型中不可或缺的一部分,它们赋予神经网络强大的非线性变换能力,使其能够拟合复杂的函数关系。在这篇博文中,我们将探讨三种常见的激活函数:Tanh、Sigmoid 和 Softmax,并提供一些记忆它们的技巧。
1. Tanh 函数
定义 :
Tanh(双曲正切函数)将输入值压缩到 -1, 1 的范围内。其公式如下:

应用场景:
- 常用于隐藏层的激活函数,特别是在需要零均值化数据的场景。
- 广泛应用于循环神经网络(RNN)中。
优缺点:
- 优点:输出范围是 -1, 1,零中心化可以使得数据更好地对称,帮助梯度下降算法更有效地进行优化。
- 缺点:存在梯度消失问题,当输入值过大或过小时,梯度会变得非常小,影响深层神经网络的训练效果。
示例代码:
python
import numpy as np
def tanh(x):
return np.tanh(x)
# 示例输入
logit = 0.5
output = tanh(logit)
print(output) # 输出 0.46211715726000974记忆技巧:
- Tanh 是"双曲正切"的缩写,输出范围 -1, 1,零中心化,适合隐藏层。
2. Sigmoid 函数
定义 :
Sigmoid 函数将输入值压缩到 0, 1 的范围内。其公式如下:
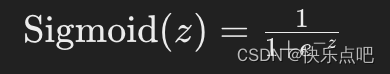
应用场景:
- 常用于二分类问题的输出层激活函数。
优缺点:
- 优点:输出范围 0, 1,适合处理概率问题。
- 缺点:存在梯度消失问题,输出不是零中心化。
示例代码:
python
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 示例输入
logit = 0.5
output = sigmoid(logit)
print(output) # 输出 0.6224593312018546记忆技巧:
- Sigmoid 函数有一个 "S" 形曲线,输出范围 0, 1,适合二分类问题的输出层。
3. Softmax 函数
定义 :
Softmax 函数将向量的输出转化为概率分布,使得所有输出的和为1。其公式如下:
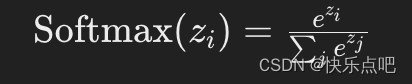
应用场景:
- 常用于多分类问题的输出层激活函数。
优缺点:
- 优点:将向量转化为概率分布,和为1,适合多分类问题。
- 缺点:需要更多计算资源。
示例代码:
python
import numpy as np
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
# 示例输入
logits = np.array([1.0, 2.0, 3.0])
output = softmax(logits)
print(output) # 输出 [0.09003057 0.24472847 0.66524096]记忆技巧:
- Softmax 将向量转化为概率分布,和为1,适合多分类问题的输出层。
激活函数的顺序使用
在神经网络中,这些激活函数通常按以下顺序使用:
- 输入层:无激活函数,仅用于接受输入数据。
- 隐藏层:常用 Tanh 或 ReLU(另一种激活函数)进行激活。
- 输出层 :
- 二分类问题:使用 Sigmoid 进行激活。
- 多分类问题:使用 Softmax 进行激活。
- 回归问题:通常无激活函数,或根据具体需求选择合适的激活函数。
结论
理解和记住 Tanh、Sigmoid 和 Softmax 函数的特性、应用场景和优缺点,可以帮助我们在构建和调试深度学习模型时做出更明智的选择。希望这些记忆技巧和示例代码能够帮助您更好地掌握这些激活函数。