探索与求知,培养与传承。
让青年人更早地触摸到科学研究的前沿,便能吸引更多人才投身于学科建设。
11月4日,由北京大学信息处理实验室 开展进行,北京大学心理与认知科学学院院长吴思教授及课题组成员授课的第二届神经计算建模及编程培训班将再度开课。
课程以北京大学神经信息处理课题组所著的**《神经计算建模实战》**教材为基础,结合 BrainPy 编程框架进行实践,可帮助学员为未来在神经计算领域或在类脑智能领域的研究打下坚实的基础。
两届培训均采取线上授课,和鲸为实践教学部分提供数据科学云平台及算力支持,降低不同领域背景学员学习编程的门槛、保障线上教学效果。
紧迫:以培训召集青年人才
计算神经科学的学科建设与跨领域人才培养
计算神经科学------用计算和量化的方法探究人脑的奥秘和智能的本质,是神经科学的分支学科。这门新兴交叉学科诞生自 1980 年,综合了数学、物理学、生物学、计算机科学、信息工程学等,短短三十年间日趋成熟并促成了多个领域的发展,比如最初在计算机科学领域发展起来的强化学习理论,现在在理解依赖于奖励的决策行为的大脑机制中起到了核心作用。
如果说上世纪的科学主要由物理学和分子生物学主导,那么本世纪人类面临的主要挑战之一,便是阐明大脑的工作方式。全面了解大脑功能和功能障碍发生的机理,可能是人类有史以来面临的最艰巨的科学任务。

国际上,计算神经学科领域已经形成了一个充满活力的学术群体,中国在这一前沿领域有着巨大的发展潜力,但目前仍处于空白状态。中国脑计划("脑科学和类脑研究")已被国务院批准为"2030重大科技创新项目"之一,然而要启动一个新的需要复杂定量方法的神经科学子领域,必须吸引物理学、数学、工程学和计算机科学领域的青年人才,并提供帮助他们转型到脑科学研究的培训机会。
前沿:神经计算建模及编程培训班
让天下没有难建的计算神经模型
今年 8 月,北京大学心理与认知科学学院院长吴思教授 的课题组在线上开设了一门课程**《神经计算建模实战》**。第一届培训班刚开放报名,400 个名额就被一抢而空。
培训班开设的初衷是为了普及神经计算建模方法,推动我国计算神经科学的人才培养与发展。正如教材封面上所写的"让天下没有难建的神经计算模型",吴思教授也表示,其实《神经计算建模实战》这门课偏学术,内容非常前沿。由于第一届培训班太多人没有报上名,11 月即将开设第二届培训班来给更多人提供机会学习,之后也可能还会有第三届、第四届......

两届培训班均采取线上授课,为了召集更多青年人才,报名阶段没有做任何专业领域的限制,凡是对神经计算建模感兴趣的师生都可以参与。但这也同时加大了授课难度,其中一大难点是线上授课的实践部分------如何保障不同基础的学员都能全程跟上课程进度,上手实践。对此,和鲸提供了数据科学云平台及算力支持。平台内置了所需的镜像环境,学员打开网页即可复现老师的课件,免除了繁复的底层工作,灵活的算力调度能力也能流畅地支持 400 个学员同时使用的"高并发"场景。
第一届培训班收到了许多学员的反馈。
"这个周的学习坚定了我结合神经生物学与神经计算来揭示神经科学基本规律的决心。"
"报名这个课程带领我进入了计算神经科学的大门......原共赴,直至星辰大海的尽头。"
"这些知识为我未来在神经计算领域或者类脑智能领域的研究打下坚实的基础。"
这些反馈正呼应了吴思教授对于近十几年来计算神经科学在中国的发展情况的评价:"(学科)还在发展中,(从事计算神经科学研究的)人还是太少,但会有越来越多的人参与进来。不光是计算神经科学,比如现在做类脑智能的研究者,与深度学习网络不同,他们做一些偏脉冲神经网络研究。这些人也在学习计算神经科学的知识,所以这个领域还在扩展。"
为更多培训班提供支持
探索与求知,培养与传承
事实上,培训班并不是和鲸第一次了解到计算神经科学,这个"冷门而小众"的学科几年前在国内还只是微光点点,而随着各个领域人才的凝结,它已聚而成炬。
探索与求知,培养与传承。让青年人更早地触摸到科学研究的前沿,便能吸引更多人才投身于学科建设。
我们深受感触。
和鲸社区聚集 50万+ 数据从业者与爱好者,具备丰富且实时更新的真实数据、开源代码、项目案例及实训活动资源,覆盖商科经管、地球科学、人文社科、生物医学等广泛的学科领域,您可进入ModelWhale官网免费注册使用。
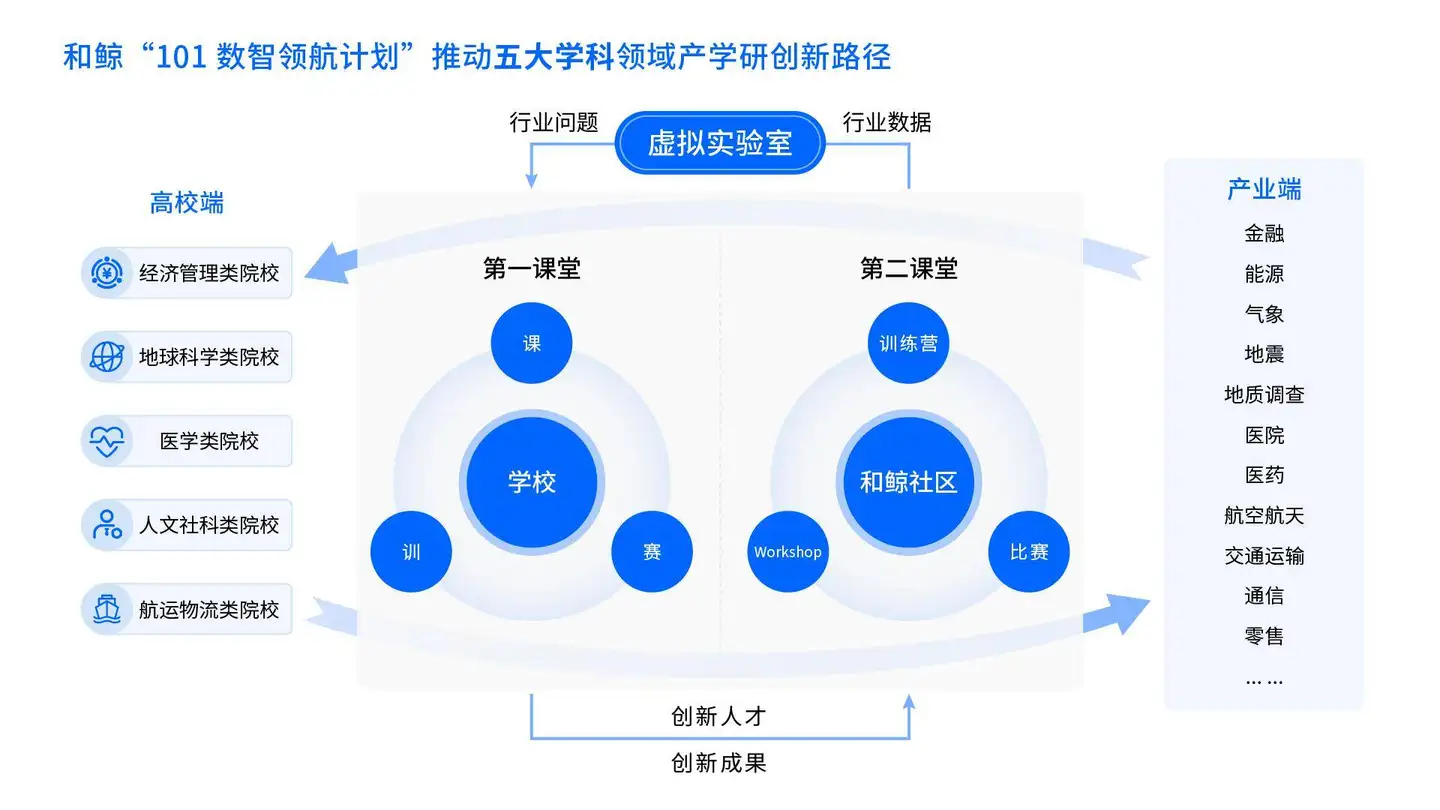
本次活动属于和鲸发起的和鲸社区"101数智领航计划"系列活动,旨在积极贯彻教育部基础学科系列"101计划"工作。2024 年,和鲸社区结合近十年在数据科学人工智能的开源资源积累和专业共建经验积累,将与 20 个头部高校共创共建高质量课程、高质量数据集、高质量实践项目以及学科大模型等,同时开放有限学院名额,助力建立 AI 创新虚拟实验室。
若您对这一计划感兴趣,也欢迎关注和鲸公众号与我们取得联系。