一、概念
1.神经元模型
(1)神经网络的基本组成单位
(2)生物上,每个神经元通过树突接受来自其他被激活神经元的信息,通过轴突释放出来的化学递质改变当前神经元内的电位。当神经元内的电位累计到一个水平时(这个过程不一定就是持续的,线性的,而这使我们需要的松弛感)就会被激活,产生动作电位,然后通过轴突释放化学物质。
(人话就是这个做出反应的功能就是我们要的让机器具有"反应"的能力,人类的记忆之本,而记忆又是智慧之本。)
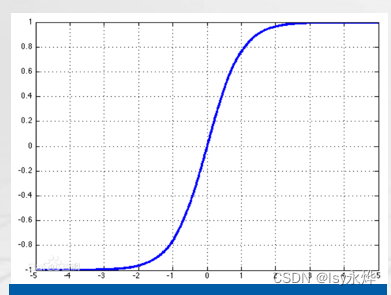
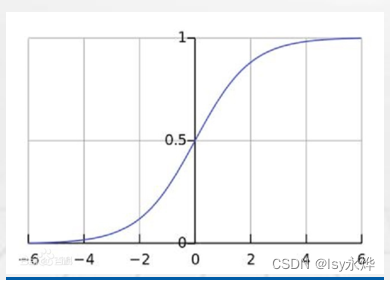
(3)常用的激活函数(牢记!!!!!注意x,y的取值范围!!!!!):
激活函数的目的是进行非线性变换(就是刺激/反应)。
Sigmoid:优点易于求导;输出区间固定,训练过程不易发散;可作为二分类问题的概率输出函数。
ReLU:是目前广泛使用的一种激活函数。
优点:计算速度快:减少梯度消失问题:稀疏激活性:实现简单:
缺点:输出不是严格的范围限定:输出可能不稳定:不适合所有情况:
Tanh:使用Tanh的神经网络往往收敛更快。
Softmax:常用于将函数的输出转化为概率分布。其可以看作是arg max的平滑近似。


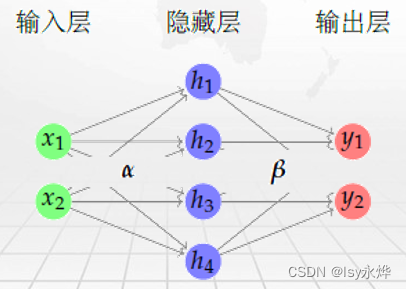
2.多层感知机
输入层输入数据,隐藏层处理数据(其中包含激活函数),输出层输出数据(其中包含激活函数)。
3.损失函数:
(1)被用对于神经网络模型的性能进行度量,其评价的是模型预测值与真实值之间的差异程度。
(2)不同的任务往往对应不同的损失函数,常用的包括:
交叉熵损失函数: 主要用于分类任务当中,如图像分类、行为识别等;
平方误差损失函数: 主要用于回归任务中。
4.反向传播算法(BP算法)
本质:对各连接权值的动态调整
(1)是一种按照误差逆向传播算法训练的多层前馈神经网络,具有高度的非线性映射能力。
(2)算法包括信号的前向传播和误差的反向传播。
即计算误差输出时,按从输入到输出的方向进行;
而调整权值和阈值时,按从输出到输入的方向进行。
(3)正向传播:输入信号通过隐藏层作用于输出结点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。
(4)误差的反向传播:将输出误差通过隐藏层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值w_ij的依据。
(5)优点:
很好的逼近特性。 具有较强的泛化能力。 具有较好的容错性。
(6)缺点:
收敛速度慢。 局部极值。 难以确定隐层和隐层结点的数目。
(7) 层与层的连接是单向的,信息的传播是双向的。
5.梯度下降法:
(1)反向学习(BP)算法又叫梯度下降法,由于BP 神经网络权值参数的运算量过大,一般采用梯度下降法来实现。
(2)是一种迭代优化方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向(因为在该方向上目标函数下降最快)。
(3)神经网络训练过程中,使用梯度下降技术来最小化代价函数。
(4)特点:越接近目标值,步长越小,下降速度越慢。
6.梯度消失
(1)其实就是斜率消失,在BP算法中使用链式法则进行连乘时,靠近输入层的参数梯度几乎为0,即几乎消失的情况。如sigmod。
(2)解决方法:
a.更换激活函数,如选择ReLU这种梯度不易饱和的函数;
b.调整神经网络的结构,减少神经网络的层数等。
7.梯度爆炸
(1)参数的初始化不合理,由于每层的梯度与其函数形式、参数、输入均有关系,当连乘的梯度均大于1时,就会造成底层参数的梯度过大。
(2)解决方法:
a.模型参数初始化
b.梯度裁剪
c.参数正则化
8.深度学习
(1)深层神经网络在神经元数目一定的情况下,相比于传统浅层神经网络来说,具有更强大的学习能力,能够从原始输入中自动提取出具有高度抽象含义的特征(即脑补能力极其nb)。
(2)是非监督的特征学习。
(3)与传统的区别:
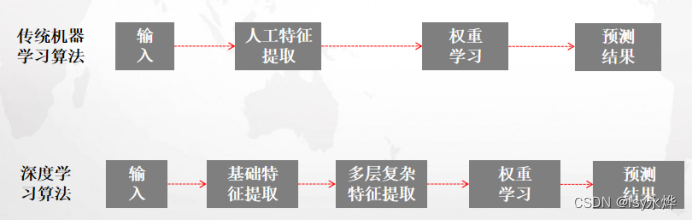
9.卷积神经网络(重点)
人工智能已经学过考过,但仍是这学期还是重点,甚至题目都跟上学期一模一样,我的评价是XX,跟软件项目管理靠软件经济一样,没有提前做好教学规划。
(1)是深度神经网络中的一种,受生物视觉认知机制启发而来。
(2)原理很简单,就是用卷积核在样本矩阵上移动求出来一个新的矩阵:
就是对应位置相加再相乘,不会的可以看看后面的习题
(3)卷积核每次移动的单位,可设定为不同长度,称之为步长(stride)。
(4)丢失部分边界信息,为解决这些问题,通常会为原始数据填补上一圈或几圈元素,这一操作称之为填充(padding)。
(就是有的数据太少了,或者不够凑出来一个移动矩阵,就在周围补一圈0)


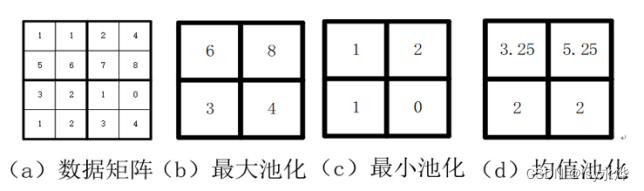
10.池化(Pooling)
(1)用于卷积之后,发现得出来的特征矩阵还是不太行之后。
(2)目的在于降低特征图的维度。
(3)池化需要一个池化核,池化核的概念类似于卷积核。
(4)所对应的池化操作分别称之为最大池化、最小池化和均值池化。
11.生成对抗网络
(1)包含两个部分:生成器G(Generator)和判别器D(Discriminator)。
(2)生成器G:从给定数据分布中进行随机采样并生成一张图片。
(3)判别器D:用来判断生成器生成的数据的真实性。
(4)例如:生成器负责生成一张鸟的图片,而判别器的作用就是判断这张生成的图片是否真的像鸟。
二、习题
单选题:
4、对神经网络(Neural Network)而言,下面哪一项对过拟合和欠拟合影响最大( A )。
A 隐藏层节点数量
B 初始权重
C 学习速率
D 每一次训练的输入个数
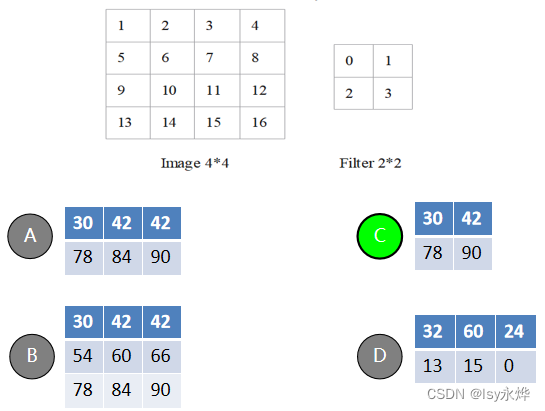
5、完成下图的卷积运算,即图像Image与滤波器Filter卷积获得Feature map,其中步长s=2,给出feature map值(C)。
6、下列不属于常见的池化方式的是(B)。
A 平均池化
B 随机池化
C 最小池化
D 最大池化
- 关于反向传播算法的说法错误的是(C )。
A、之所以称为反向传播是由于在深层神经网络中,需要通过链式法则将梯度逐层传递到底层。
B、反向传播算法又叫做梯度下降法。
C、函数值沿着梯度的方向下降最快。
D、优化过程中容易出现梯度消失和梯度爆炸。
注意是负梯度方向
多选题:
- 下列属于常用的激活函数的是(ABCD )
A、ReLU
B、Sigmoid
C、Tanh
D、Softmax
判断题:
- 卷积神经网络通常由多个输入层和一个输出层以及多个隐藏层组成。隐藏层包括卷积层、激活层、池化层以及全连接层等。(Í )
通常由一个输入一个输出,多个隐藏
计算题:
1.完成下图的卷积和池化运算。
输入图像为5*5,卷积核3*3,步长为1,池化窗口2*2
求卷积后的特征图(5分)
对卷积后的特征图做最小池化运算,求最终特征图,(5分)
输入图像 5*5
|---|---|---|---|---|
| 1 | 0 | 1 | 2 | 3 |
| 0 | 1 | 2 | 1 | 0 |
| 2 | 3 | 0 | 1 | 0 |
| 0 | 1 | 2 | 0 | 1 |
| 1 | 0 | 1 | 2 | 1 |卷积核 3*3, bias=0
|---|---|---|
| 1 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 1 |解:(1)卷积结果:
比如这里的5就是红字的地方就是
1*1 + 0*0 + 1*1
0*0 + 1*1 + 0*2
2*1 + 3*0 + 0*1 = 5
然后8这个就是中间三列,那几个数和卷积核相乘再相加。
|---|---|---|
| 5 | 8 | 5 |
| 7 | 3 | 6 |
| 5 | 8 | 2 |(2)池化结果
这里用的2*2(题目说了)的池化核,还说了最小池化法,就是选最小的就行,更简单,比如红字部分,最小的是3,所以第一个3就是这么来的,简单的一批。
|---|---|
| 3 | 3 |
| 3 | 2 |