引言
DataX 系列文章:
1.1 DataX
1.1.1 Data X概览
DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
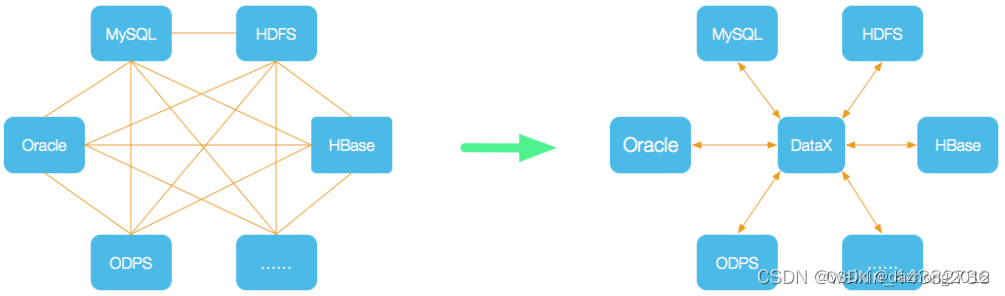
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
1.1.2 DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
1.1.3 DataX3.0插件体系
| 数据源类型 | 数据源名称 | Reader(读) | Writer(写) | 备注 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读、写 |
| Oracle | √ | √ | 读、写 | |
| OceanBase | √ | √ | 读、写 | |
| SQLServer | √ | √ | 读、写 | |
| PostgreSQL | √ | √ | 读、写 | |
| DRDS | √ | √ | 读、写 | |
| 达梦 | √ | √ | 读、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读、写 | |
| OCS | √ | √ | 读、写 | |
| NoSQL 数据存储 | OTS | √ | √ | 读、写 |
| Hbase 0.94 | √ | √ | 读、写 | |
| Hbase 1.1 | √ | √ | 读、写 | |
| MongoDB | √ | √ | 读、写 | |
| Hive | √ | √ | 读、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读、写 |
| FTP | √ | √ | 读、写 | |
| HDFS | √ | √ | 读、写 | |
| Elasticsearch | √ | 写 |
1.1.4 DataX3.0六大核心优势
1、可靠的数据质量监控
1)完美解决数据传输个别类型失真问题
2)提供作业全链路的流量、数据量运行时监控
3)提供脏数据探测
2、丰富的数据转换功能
3、精准的速度控制
4、强劲的同步性能
5、健壮的容错机制
6、极简的使用体验
1.2 DataX-Web
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发,可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU、内存、负载的监控等等。数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
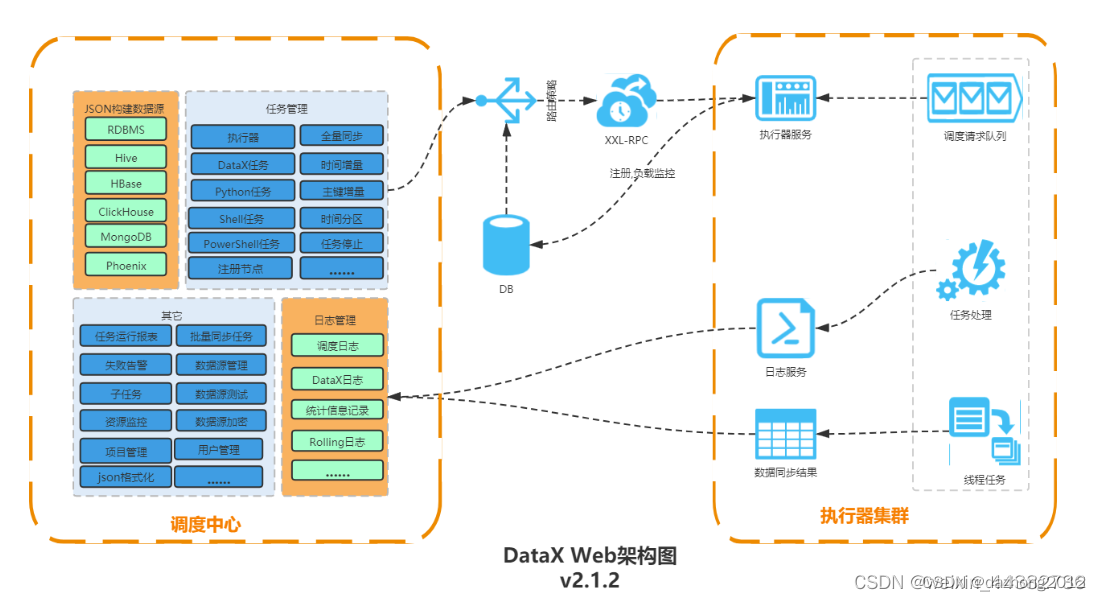
简单来说用户可以通过图形化web,构建DataX Json,可以轻松调度各Job启停,DataX-Web也提供了诸如阻塞处理、超时警告等等功能辅助生产,对于少量数据同步任务,DataX-Web完全可以胜任,并且大大减少了工作量。