11暂退法Dropout
python
#Dropout 是一种正则化技术,主要用于防止过拟合,
#通过在训练过程中随机丢弃神经元来提高模型的泛化能力。
import torch
from torch import nn
from d2l import torch as d2l
import liliPytorch as lp
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
#该情况下,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
#该情况下所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
"""
生成一个与 X 形状相同的掩码张量 mask。torch.rand(X.shape) 生成一个元素值在 [0, 1) 范围内的均匀分布的随机张量。
mask 中的每个元素与 dropout 进行比较,若大于 dropout 则为 1(保留),否则为 0(丢弃)。最后将布尔值转换为浮点数。
"""
#将 mask 和 X 元素逐位相乘,以应用掩码效果,即丢弃部分神经元。
#为了保持输出的期望值不变,结果除以 (1.0 - dropout) 进行缩放补偿。
return mask * X / (1.0 - dropout)
#测试dropout_layer函数
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
"""
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 4., 6., 0., 0., 12., 0.],
[16., 0., 20., 0., 0., 26., 28., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
"""
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
#dropout1:第一个隐藏层之后的 dropout 比例为 20%。
#dropout2:第二个隐藏层之后的 dropout 比例为 50%。
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
#将输入张量X重塑为 (batch_size, num_inputs) 的形状。
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
# lp.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
# d2l.plt.show()
#Dropout 简洁实现
net = nn.Sequential(
nn.Flatten(),#它会将多维的输入张量展平成一维。
nn.Linear(784,256),
nn.ReLU(),
#在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
#在第二个全连接层后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256,10)
)
#函数接受一个参数 m,通常是一个神经网络模块(例如,线性层,卷积层等)
def init_weights(m):
#这行代码检查传入的模块 m 是否是 nn.Linear 类型,即线性层(全连接层)
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.01)
#m.weight 是线性层的权重矩阵。
#std=0.01 指定了初始化权重的标准差为 0.01,表示权重将从均值为0,标准差为0.01的正态分布中随机采样。
#model.apply(init_weights) 会遍历模型的所有模块,并对每个模块调用 init_weights 函数。
#如果模块是 nn.Linear 类型,则初始化它的权重。
net.apply(init_weights)
trainer = torch.optim.SGD(net.parameters(), lr = lr)
lp.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show() 运行结果:
python
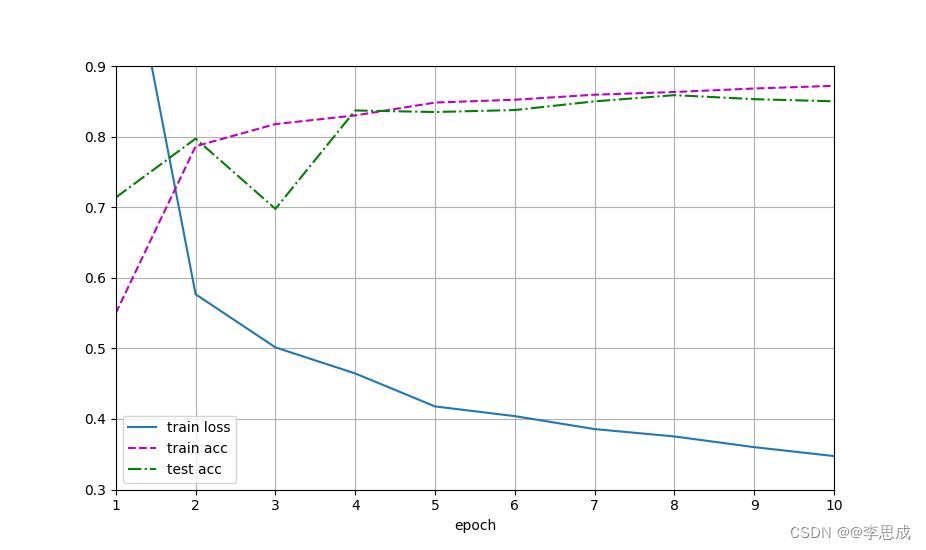
epoch: 1,train_loss: 1.1632388224283854,train_acc: 0.55005,test_acc: 0.7137
<Figure size 350x250 with 1 Axes>
epoch: 2,train_loss: 0.5765969015757243,train_acc: 0.7862833333333333,test_acc: 0.7971
<Figure size 350x250 with 1 Axes>
epoch: 3,train_loss: 0.5013401063283285,train_acc: 0.8177166666666666,test_acc: 0.6976
<Figure size 350x250 with 1 Axes>
epoch: 4,train_loss: 0.46441060066223144,train_acc: 0.8299666666666666,test_acc: 0.837
<Figure size 350x250 with 1 Axes>
epoch: 5,train_loss: 0.4177045190811157,train_acc: 0.8482,test_acc: 0.8348
<Figure size 350x250 with 1 Axes>
epoch: 6,train_loss: 0.4039476199467977,train_acc: 0.8522,test_acc: 0.8376
<Figure size 350x250 with 1 Axes>
epoch: 7,train_loss: 0.38559712861378986,train_acc: 0.8593333333333333,test_acc: 0.8499
<Figure size 350x250 with 1 Axes>
epoch: 8,train_loss: 0.37514646828969317,train_acc: 0.86315,test_acc: 0.8587
<Figure size 350x250 with 1 Axes>
epoch: 9,train_loss: 0.36000535113016763,train_acc: 0.8681166666666666,test_acc: 0.853
<Figure size 350x250 with 1 Axes>
epoch: 10,train_loss: 0.3473748308181763,train_acc: 0.8719333333333333,test_acc: 0.85