论文摘要翻译与评论
论文标题:
QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
提出的框架
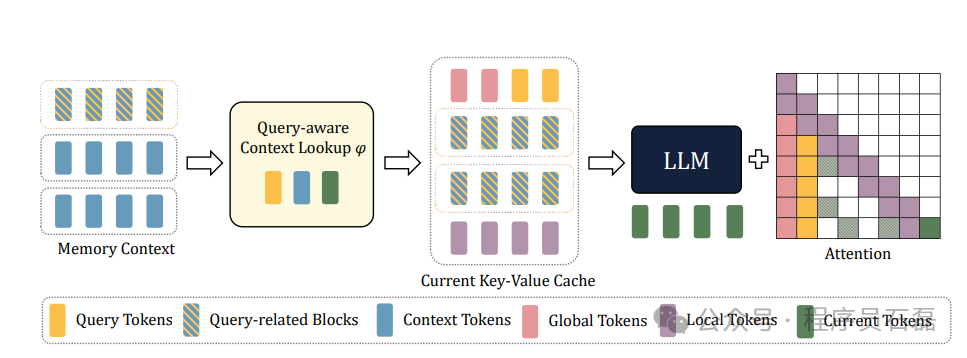
我们Q-LLM框架的示意图。来自记忆上下文的输入被分割成记忆块,通过查询感知的上下文查找来搜索与查询相关的块。目前的键值缓存由全局标记、查询标记、查询相关块和局部标记组成。它们共同形成一个新的上下文窗口,并与当前标记一起被输入到LLM中。
摘要翻译:
大型语言模型(LLMs)在理解和推理长文本上下文方面的能力是各领域进步的关键。然而,它们在识别相关上下文和记忆搜索方面仍存在困难。为了解决这个问题,我们引入了Query-aware Inference for LLMs(Q-LLM)系统,该系统旨在像人类认知一样处理广泛的序列。通过专注于与给定查询相关的记忆数据,Q-LLM能够在固定窗口大小内准确捕捉相关信息,并为查询提供精确答案。它不需要额外的训练,可以无缝集成到任何LLMs中。使用LLaMA3(QuickLLaMA),Q-LLM可以在30秒内阅读《哈利·波特》并准确回答相关问题。在公认的基准测试中,Q-LLM在LLaMA3上的性能提高了7.17%,在Mistral上的性能提高了3.26%,在无限基准测试中提高了7.0%,并在LLaMA3上实现了100%的准确率。我们的代码可以在https://github.com/dvlab-research/Q-LLM找到。
主要方法:
- 系统设计:
- Q-LLM系统采用Query-aware Context Lookup策略,只选择与查询相关的记忆数据,从而过滤掉无关的干扰。
- 该系统无需额外训练,可以与任何LLMs无缝集成。
- 性能评估:
- 使用LLaMA3-8B-inst和Mistral-7B-inst-v0.2作为基础模型,进行一系列基准测试,包括Longbench、∞-Bench和Needle-in-a-Haystack Benchmark。
- 结果显示Q-LLM在处理极长序列时显著优于当前的最新技术。
主要贡献:
- Q-LLM系统的提出:
- 该系统利用查询感知的上下文查找策略,显著提高了长序列处理和推理的效率。
- 无需额外训练的系统集成:
- Q-LLM无需额外训练即可与现有的大型语言模型集成,使其具有广泛的应用潜力。
- 显著的性能提升:
- 在多个基准测试中,Q-LLM展示了在处理长序列任务中的优越性能,尤其是在查询相关的推理任务中。
创新性:
- 查询感知上下文查找:
- 模拟人类认知的处理方式,通过查询感知的上下文查找策略,专注于与查询相关的信息,提高了模型的效率和准确性。
- 长序列处理:
- Q-LLM能够在固定窗口大小内处理长达1024K tokens的序列,这是目前许多模型所不能及的。
方法的长强点和弱点:
- 优势 :
- 无需额外训练即可集成,降低了系统部署的复杂性。
- 在多项基准测试中表现出色,尤其是在处理长序列任务中。
- 查询感知的上下文查找策略提高了模型的查询回答准确性。
- 弱点 :
- 依赖于固定窗口大小,可能在处理高度复杂的上下文时存在信息丢失的风险。
- 对于非常嘈杂的上下文,尽管有过滤机制,仍可能受到干扰,影响准确性。
通过以上分析,Q-LLM展示了在大型语言模型处理长序列任务中的巨大潜力,特别是在无需额外训练的情况下实现了显著的性能提升。然而,未来的研究需要继续优化其处理复杂上下文的能力,以确保在更广泛的应用场景中能够有效应用。
论文下载地址
链接:https://pan.quark.cn/s/012ff035720d
如果您也对大模型的应用,调优,安装感兴趣,请关注我!