目录
[6.5.1 read uncommitted---read committed(赃读问题)](#6.5.1 read uncommitted—read committed(赃读问题))
[6.5.2 read committed---Repeatable Read(不可重复读问题)](#6.5.2 read committed—Repeatable Read(不可重复读问题))
[6.5.3 Repeatable Read---serializable(幻读问题)](#6.5.3 Repeatable Read—serializable(幻读问题))
1多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
(1)一对多(多对一):部门 与 员工的关系
(2)多对多:学生 与 课程的关系
(3)一对一:用户 与 用户详情的关系
案例多对多:
创建学生表create,并插入数据insert:
create table student(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
no varchar(10) comment '学号'
) comment '学生表';
insert into student values (null, '黛绮丝', '2000100101'),(null, '谢逊', '2000100102'),(null, '殷天正', '2000100103'),(null, '韦一笑', '2000100104');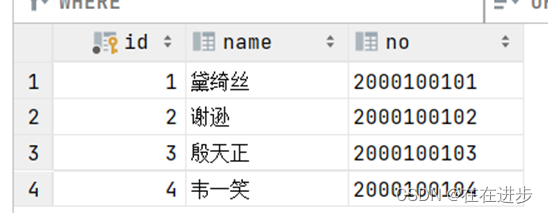
创建课程表create,并插入数据insert:
create table course(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '课程名称'
) comment '课程表';
insert into course values (null, 'Java'), (null, 'PHP'), (null , 'MySQL') , (null, 'Hadoop');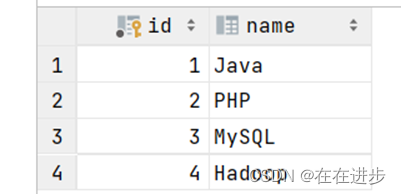
创建课程和学生之前的关系表create,并插入数据insert:
create table student_course(
id int auto_increment comment '主键' primary key,
studentid int not null comment '学生ID',
courseid int not null comment '课程ID',
constraint fk_courseid foreign key (courseid) references course (id),
constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4);
可以看到3个表的关系可视化图:

2多表查询概述
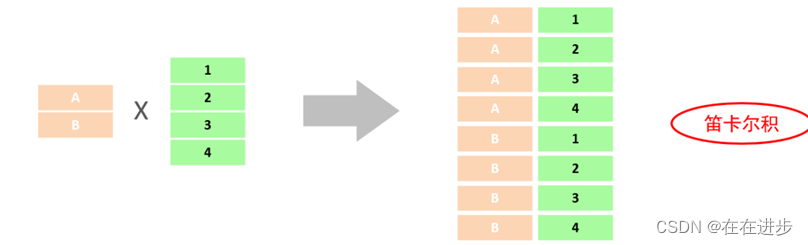
逗号直接连接查询------笛卡尔积
查询单表数据:select * from emp;
执行多表查询: select * from emp , dept; (逗号隔开)

笛卡尔积: 笛卡尔乘积是指在数学中,集合A集合和B集合的所有组合情况。
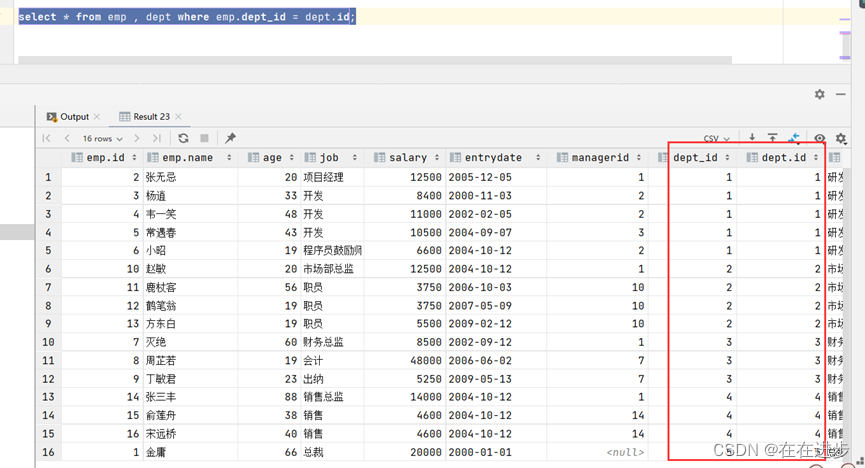
可以给多表查询加上连接查询的条件来去除无效的笛卡尔积:
select * from emp , dept where emp.dept_id = dept.id;
多表查询分为连接查询和子查询
3连接查询
3.1内连接
内连接查询的是两张表交集部分的数据。(也就是绿色部分的数据)

1)隐式内连接
SELECT 字段列表 FROM 表1,表2 WHERE条件... ;
2 )显式内连接
SELECT 字段列表 FROM 表1 INNER JOIN 表2 ON 连接条件 ...
因此下面两个代码效果相同:(emp有17条记录,dept有6条数据。)
select\*fromemp , dept whereemp.dept_id= dept.id;select\*fromemp e joindept d one.dept_id= d.id;3.2左外连接
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。左连接完全包含左表,所以这里会查询到至少17条数据。尽管右表对应记录为空。
SELECT 字段列表 FROM 表1 LEFT OUTER JOIN 表2 ON 条件 ... ;
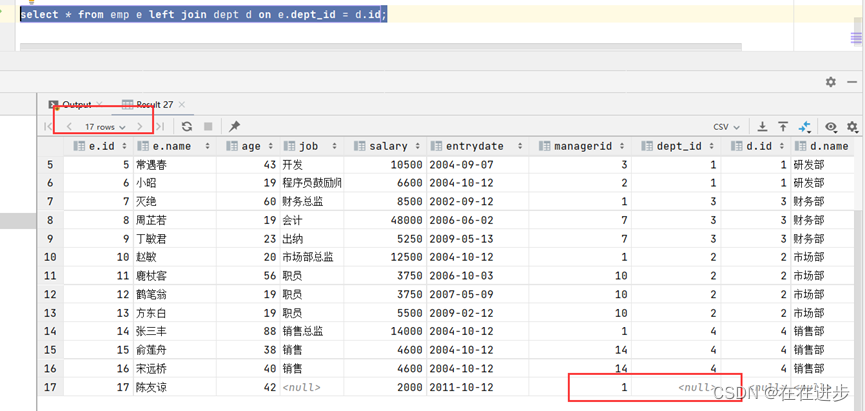
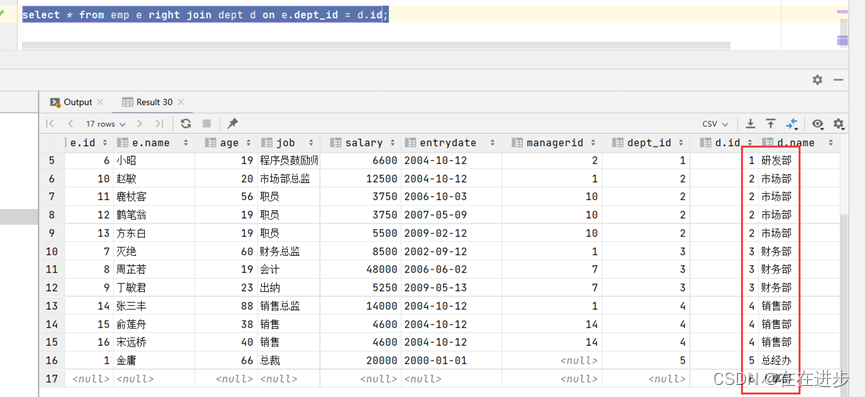
3.3右外连接
右表的数据要完全都包含,尽管左表中没有这个数据。右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
SELECT 字段列表 FROM 表1 RIGHT OUTER JOIN 表2 ON 条件 ... ;
3.4自连接
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。
自连接查询,可以是内连接查询,也可以是外连接查询。
可以把两个自连接的表看成两个不同的表,类比前面的内外连接理解。
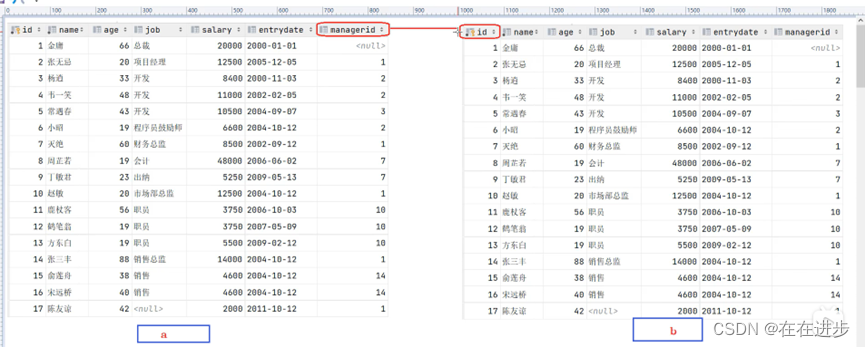
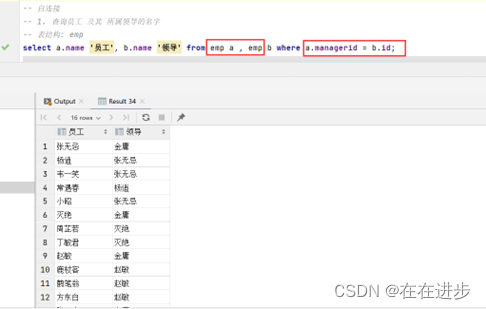
例1. 查询员工 及其 所属领导的名字------内连接
select a.name '员工', b.name '领导' from emp a , emp b where a.managerid = b.id;
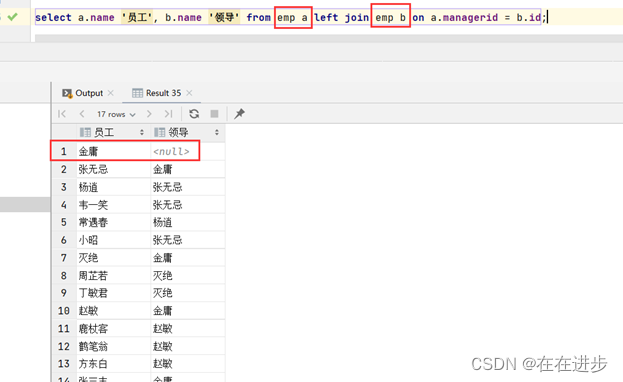
例2. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来------外连接(内连接只查询相交部分)
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id;
4联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
UNION ALL 直接全部合并,UNION对查询结果要去重。
语法:
SELECT字段列表 FROM表A...
UNION ALL
SELECT 字段列表 FROM表B.... ;
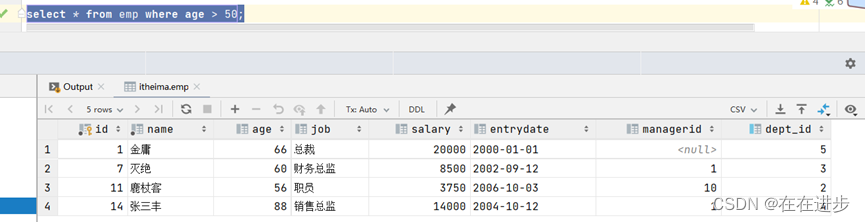
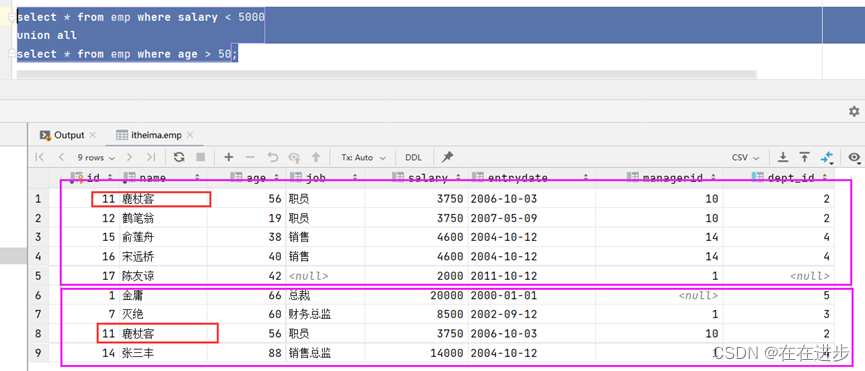
案例:将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
表(1)将薪资低于 5000 的员工

表(2)年龄大于 50 岁的员工
UNION ALL直接将上下(1)(2)表合并在一起,不管是否重复。
UNION也是直接将上下(1)(2)表合并在一起,但是去重了。
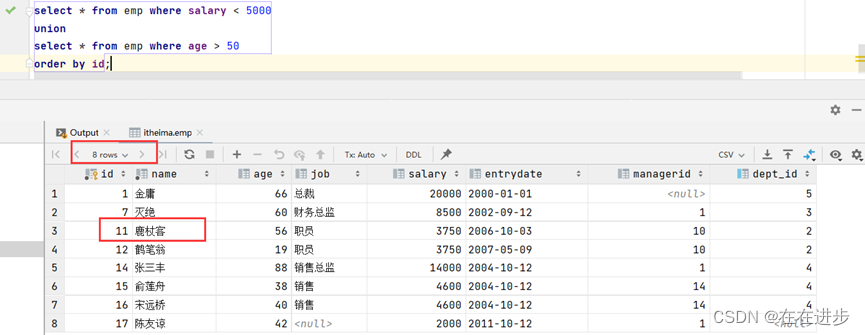
等价于where和or组合条件查询,以下代码结果同上。
select\*fromemp wheresalary< 5000 orage> 50order byid;注意:对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
5子查询
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
语法:SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是INSERT / UPDATE /DELETE / SELECT的任何一个。
根据子查询结果不同,分为:(原来是这样!!!!)
A.标量子查询(子查询结果为单个值)
B.列子查询(子查询结果为一列)
C.行子查询(子查询结果为一行)
D.表子查询(子查询结果为多行多列)
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
5.1标量子查询(子查询结果为单个值)
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: =、<>、>、 >= 、<、<=
案例:1. 查询 "销售部(dept表)" 的所有员工(emp表)信息。
代码:
select * from emp where dept_id = (select id from dept where name = '销售部');分析:
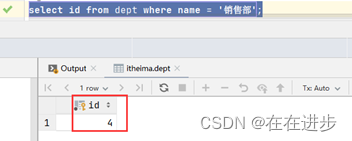
(1)先查询 "销售部" 部门ID
select id from dept where name = '销售部';
返回的是单个值4:
(2)利用子查询:根据销售部部门ID, 查询员工信息

select * from emp where dept_id = (select id from dept where name = '销售部');
相当于:select * from emp where dept_id = 4;
案例2. 查询在 "方东白" 入职之后的员工信息。
代码:
select * from emp
where entrydate > (select entrydate from emp where name = '方东白');分析:
大于某入职时间(emp表)的员工信息(emp表),虽然是一个表,但是条件不能并列直接得到。条件2依赖于条件1。
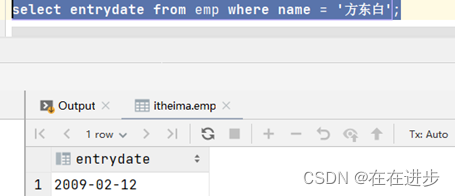
(1)查询 方东白 的入职日期
select entrydate from emp where name = '方东白';
一个人的入职时间,肯定也是一个值:
(2)查询指定入职日期之后入职的员工信息
select * from emp
where entrydate > (select entrydate from emp where name = '方东白');

5.2列子查询(子查询结果为一列)
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN(相当于单个的=)、NOT IN(不等于)、
ANY和SOME(任意满足一个就行)、ALL(全部满足)
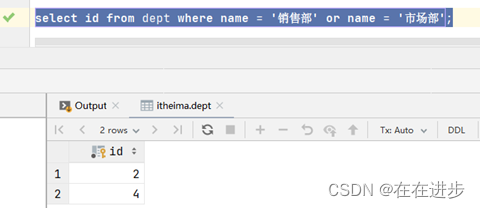
案例1 .查询 "销售部" 和 "市场部" 的所有员工信息
select * from emp
where dept_id in (select id from dept where name = '销售部' or name = '市场部');
子表返回的是一个范围,就不能用=,而要用in。下图可以看到子表返回的是1列数据(多行数据)!
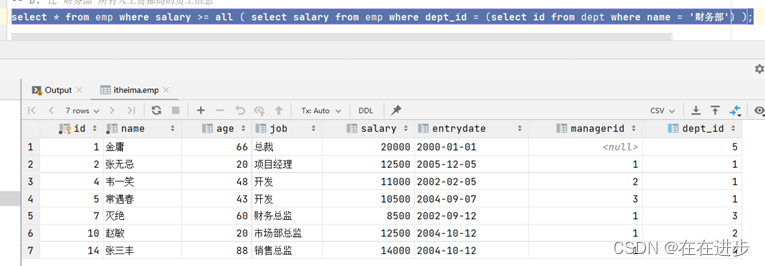
案例2 . 查询比 财务部 所有人工资都高的员工信息
代码:
select * from emp
where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') );分析:
(1). 查询所有 财务部 人员工资
先找出财务部id:
select id from dept where name = '财务部';
再找出财务部的所有薪资:
select salary from emp where dept_id = (select id from dept where name = '财务部');

(2). 比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') );
5.3行子查询(子查询结果为一行)
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<>、IN 、NOT IN
案例:查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
代码:这里=或in都可以
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');
分析:
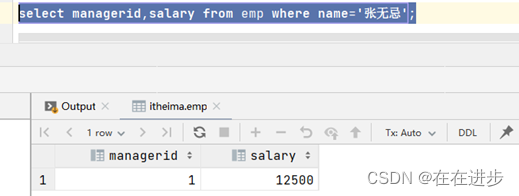
(1)查询 "张无忌" 的薪资及直属领导
select salary, managerid from emp where name = '张无忌';
子表返回的是一行(多列)数据。
(2)查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');5.4表子查询(子查询结果为多行多列)
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN,或接在from后
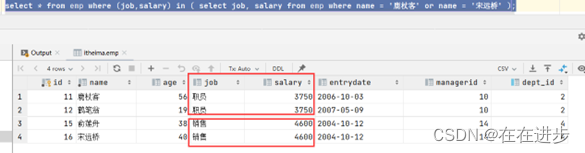
案例1. 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
代码:
select * from emp where (job,salary) in ( select job, salary from emp where name = '鹿杖客' or name = '宋远桥' );
分析:
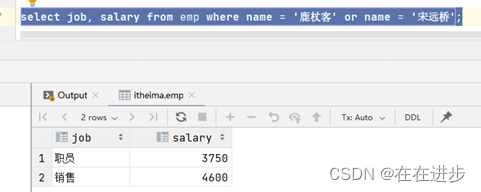
(1)查询 "鹿杖客" , "宋远桥" 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
子表返回的是2行2列的记录:
(2) 查询与 "鹿杖客" , "宋远桥" 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name = '鹿杖客' or name = '宋远桥' );
案例2. 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分析:
(1)入职日期是 "2006-01-01" 之后的员工信息
select * from emp where entrydate > '2006-01-01';
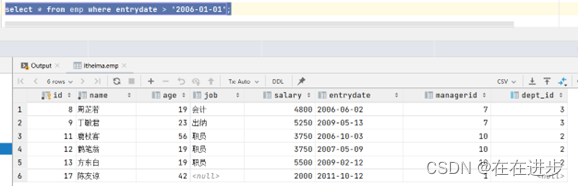
(2)查询这部分员工, 对应的部门信息;
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
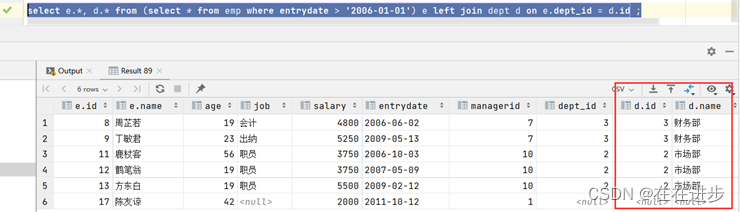
多表查询总结:

6事务简介和操作
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就比如:张三给李四转账1000块钱,张三银行账户的钱减少1000,而李四银行账户的钱要增加1000。这一组操作就必须在一个事务的范围内,要么都成功,要么都失败。
事务操作:执行成功就提交COMMIT,失败报错就回滚ROLLBACK。
6.1控制事务
6.1.1控制事务一
1).查看/设置事务提交方式
SELECT @@autocommit ;
SET @@autocommit = 0 ;
#设置为手动提交,必须输入COMMIT;才能让数据改变
2).提交事务
COMMIT;
3 ).回滚事务
ROLLBACK;
#当数据操作报错,执行回滚,就不会对部分数据造成影响,保证数据的正确性和完整性。
6.1.2控制事务二
1)开启事务
STARTTRANSACTION
或BEGIN ;
2).提交事务(成功时)
COMMIT;
3 ).回滚事务(报错时)
ROLLBACK;
6.2事务的四大特性(ACID)
(1)原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
(2)一致性(Consistency) :事务完成时,必须使所有的数据都保持一致状态。
(3)隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
(4)持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。因为数据库中的数据最终是存储在磁盘中的。
6.3并发事务问题
(1)脏读
---个事务读到另外一个事务还没有提交的数据。
(2)不可重复读
一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
(3)幻读
一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时又发现这行数据已经存在,好像出现了"幻影"。
6.4事务隔离级别
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。主要有以下几种:

查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
果然是默认的:Repeatable Read
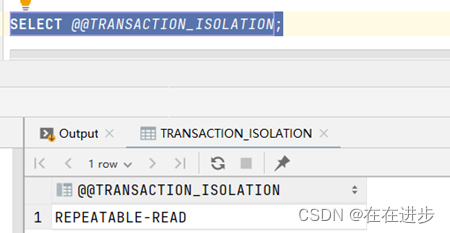
设置事务隔离级别
SETSESSION \| GLOBAL TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTEDlREAD COMMITTED | REPEATABLE READ |SERIALIZABLE }
例:set session transaction isolation level read uncommitted ;

6.5并发事务演示
6.5.1 read uncommitted---read committed(赃读问题)
(1)模拟两个事务,切换到相应的数据库:
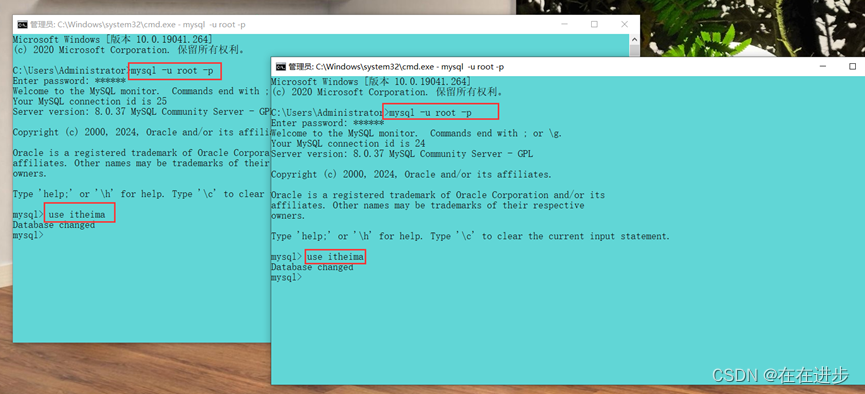
(2)创建表account并插入数据:
create table account(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
money int comment '余额'
) comment '账户表';
insert into account(id, name, money) VALUES (null,'张三',2000),(null,'李四',2000);(3)设置事务隔离级别为:read uncommitted

(4)赃读:发现左边A事务读到右边B事务还没有提交的数据。
说明read uncommitted会出现赃读情况。
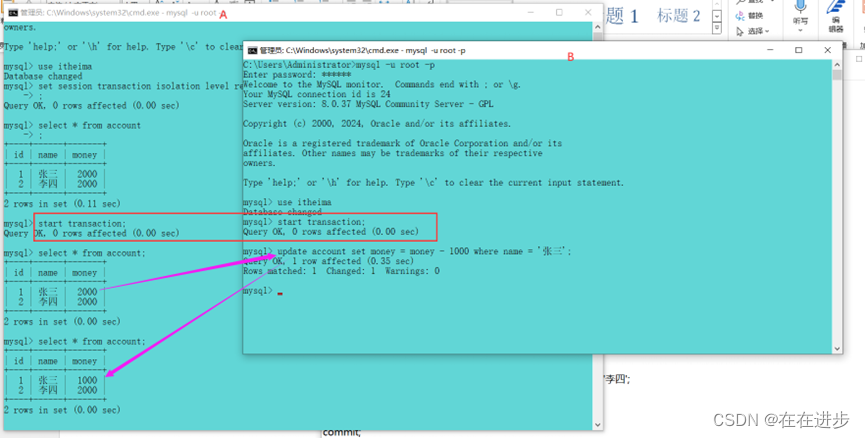
用read committed来解决赃读问题
read committed就可以解决赃读。同上的操作,将A将事务的隔离级别设置为read committed,然后在B中进行修改,但是不提交,发现A事务中不会出现赃读情况。

当然如果提交事务之后,A和B两个事务对数据库的影响都一样的。
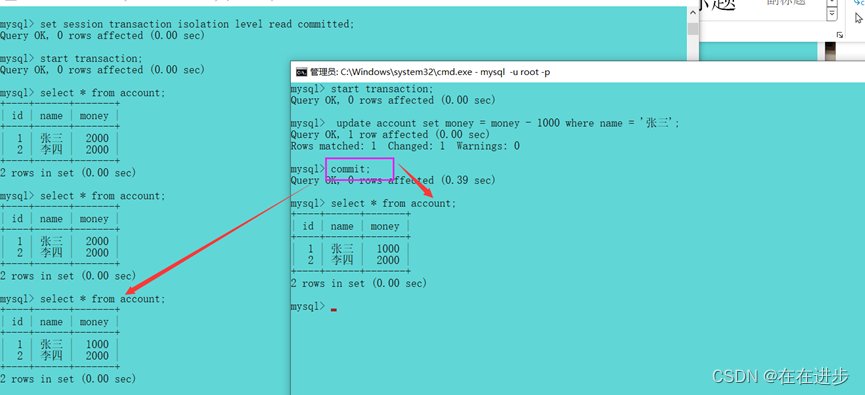
6.5.2 read committed---Repeatable Read(不可重复读问题)
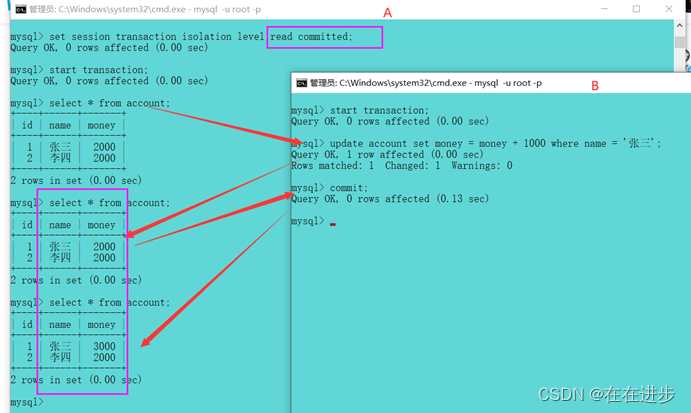
read committed可以解决赃读问题,但是会出现不可重复读问题。这是Repeatable Read可以解决。
当A事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
所以read committed不能解决不可重复读的问题。
Repeatable Read解决了不可重复读问题,当A事务先后读取同一条记录,读取的数据相同(不管B事务是否提交)。
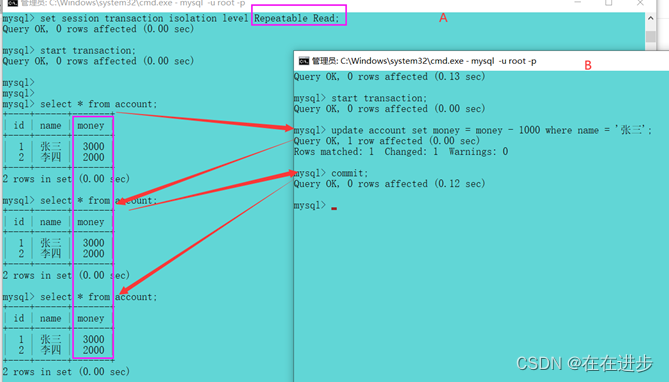
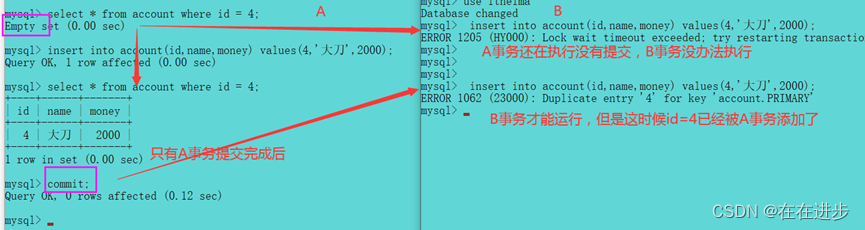
6.5.3 Repeatable Read---serializable(幻读问题)
Repeatable Read可以解决不可重复读的问题,但是事务还是会出现幻读问题。可以用终极serializable来解决。

serializable来解决幻读问题:
注意:事务隔离级别越高,数据越安全,但是性能越低。