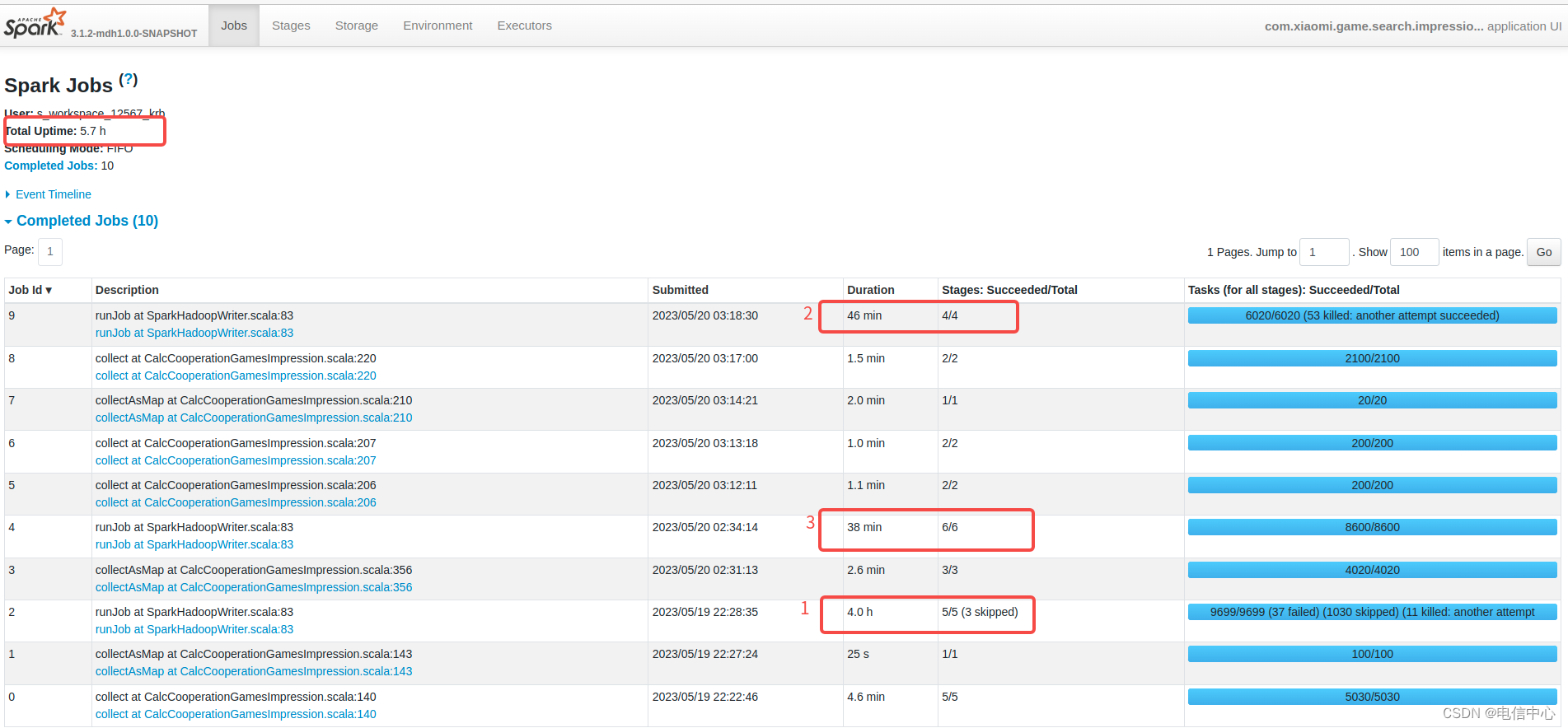
- 首先看哪个Job执行时间长:
例如下图中明显Job 2时间执行最长,这个对rdd作业是直观有效的。
对于sql作业可能不准确,sql需要关注stage的详情耗时。
- 然后看执行时间长的Job中哪个stage执行时间长:
明显stage 7和stage 13执行时间长(这个不一定百分百准确,这个包含等待调度的时间,可以点击stage链接查看详情耗时)
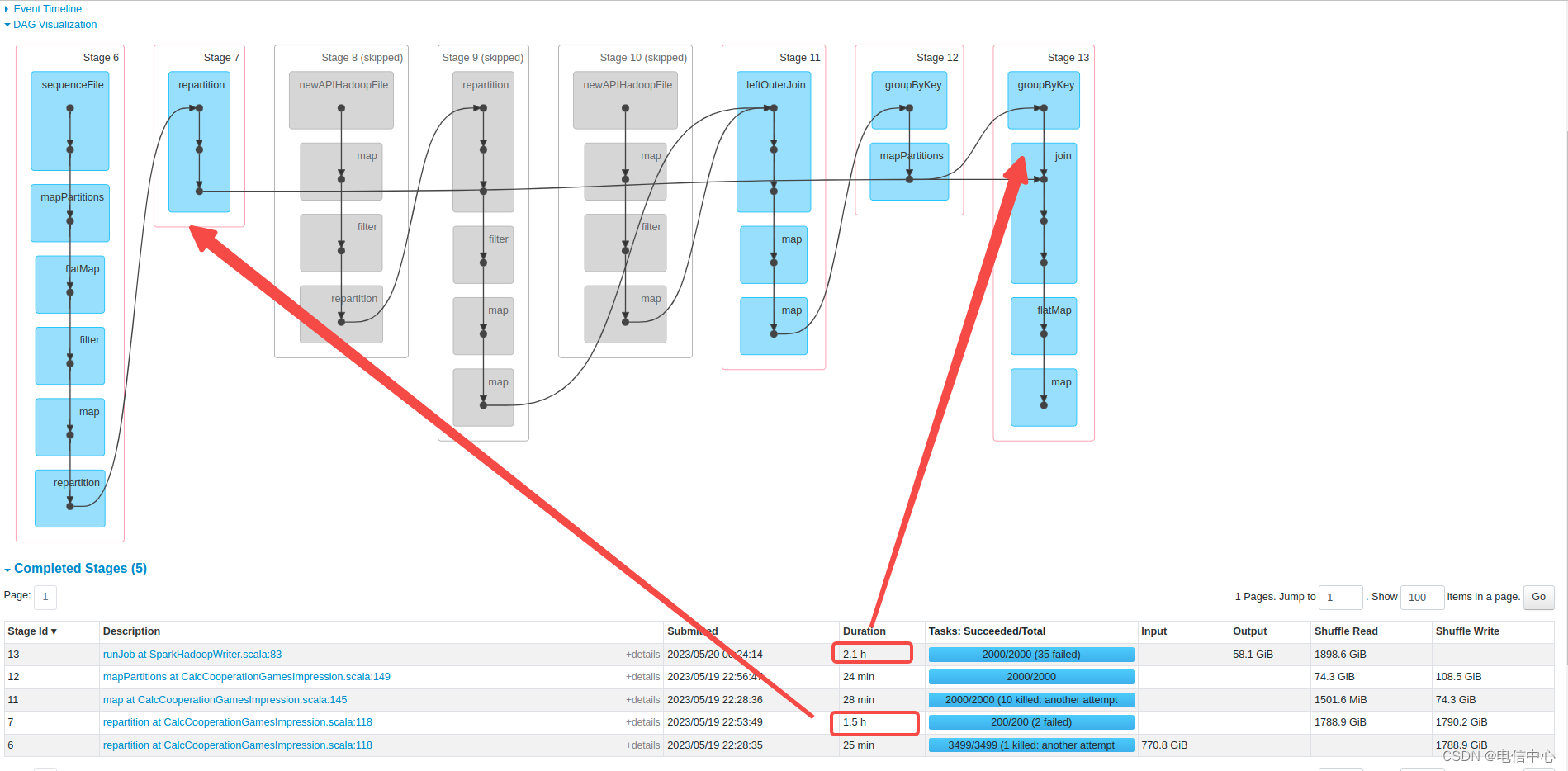
所以stage7的REPARTITION和stage13的join是瓶颈。
stage7是不必要的,因为join是会根据key再分区,REPARTITION没有意义。
- 怎么确定stage 13到底是什么代码导致的慢呢?
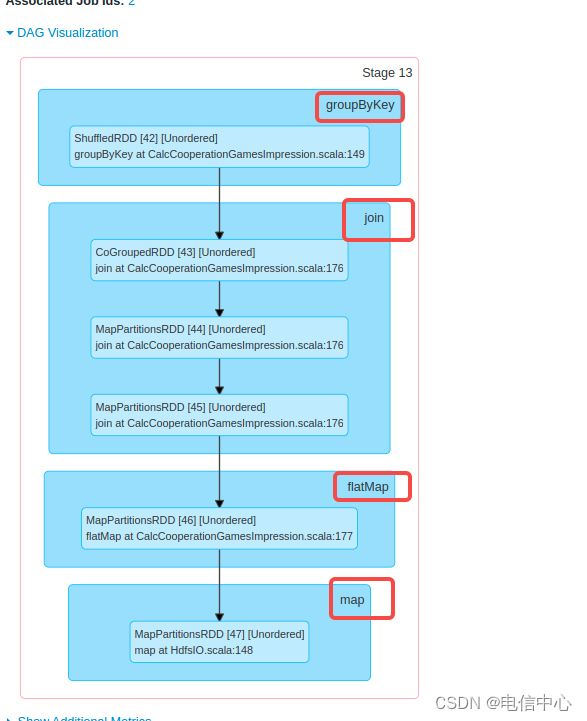
途中有四个算子,reduceByKey、Join都有可能导致数据倾斜,flatMap和map可能导致数据膨胀或者自定义逻辑慢,当前上图中的map是 HDFSIO的逻辑,比较简单。- 数据倾斜:
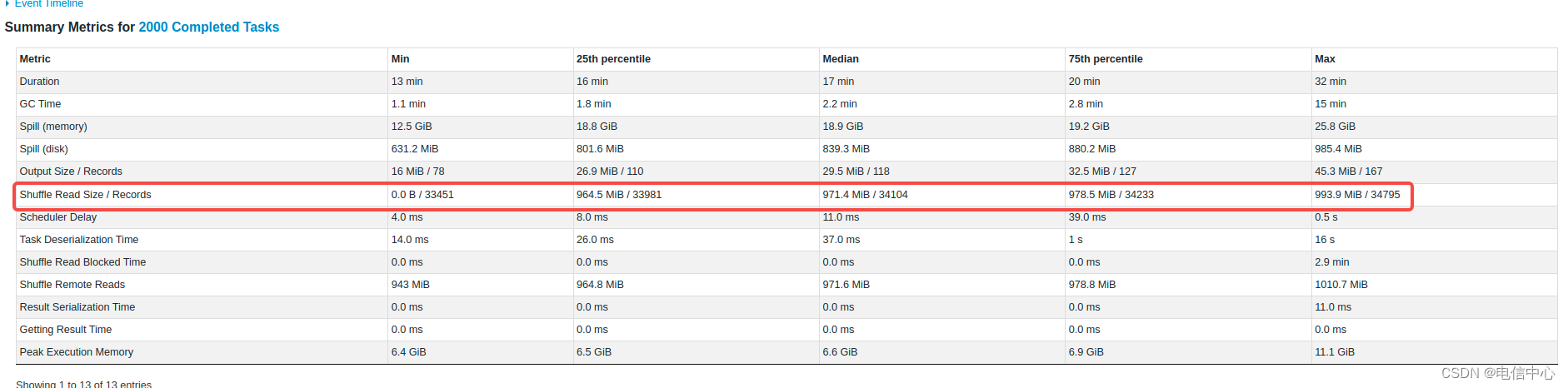
没有明显倾斜,但是:
第一:执行时间有长有短:通过分析数据,基本与gc时间有关;
第二:gc时间差异明显:可能与自定义代码逻辑有关系;
第三:内存溢出有大有小:可能与聚合逻辑有关系;
第四:内存使用峰值有明显区别。
综上,怀疑的范围主要是:reduceByKey的处理逻辑、join个别key可能比较集中一点点、flatmap逻辑存在问题导致内存紧张
还有一种情况是代码逻辑中有慢操作,例如请求外部接口、迭代计算、复杂低效的逻辑都可以通过运行时的threaddump或者结束后的pmap.log来判断。具体可以看:https://blog.csdn.net/weixin_38643743/article/details/139721055
- 数据倾斜: