做这个开发是因为:在实际开发操作中,你的kafka主题中会有大量的数据但是需求并不需要所有数据,所有我们要对数据进行清洗,把需要的数据保存在flink流中,为下流的开发做好数据保障!
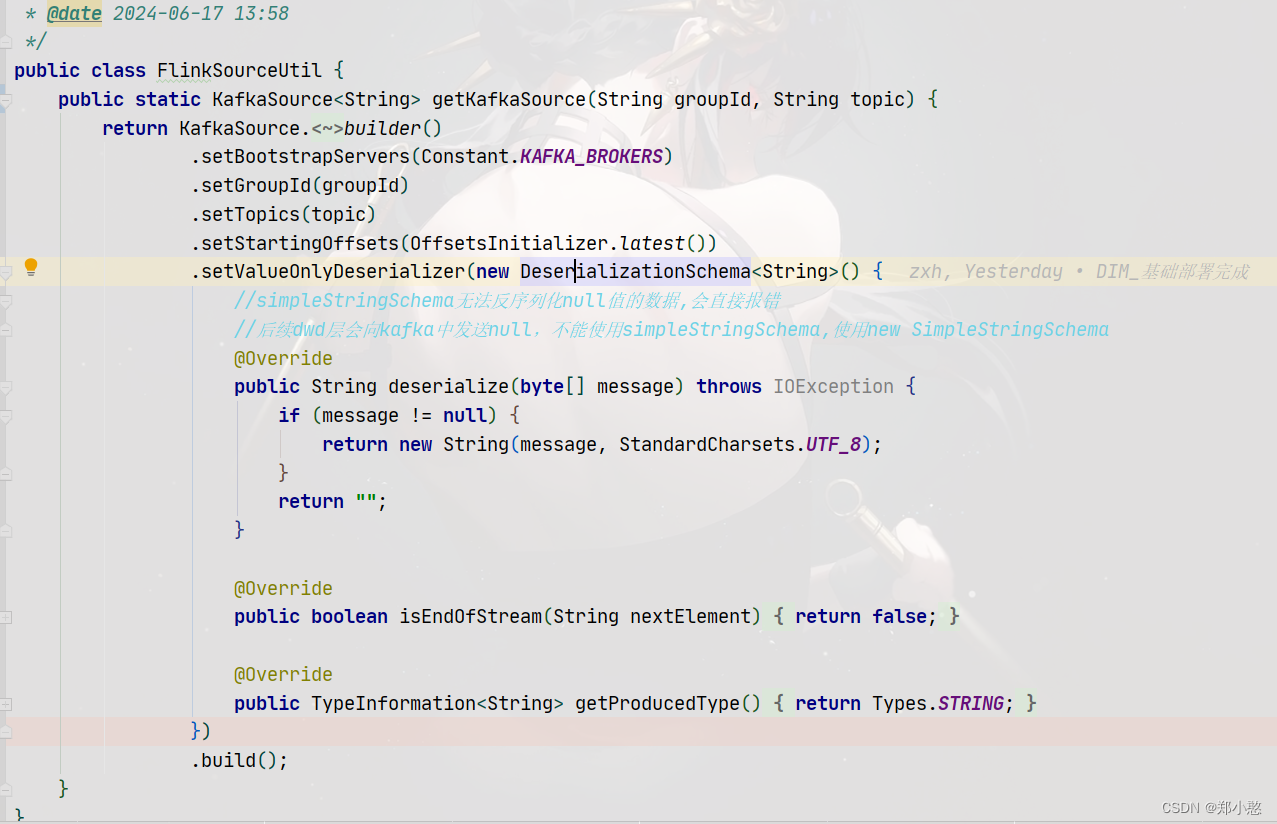
首先创建工具类
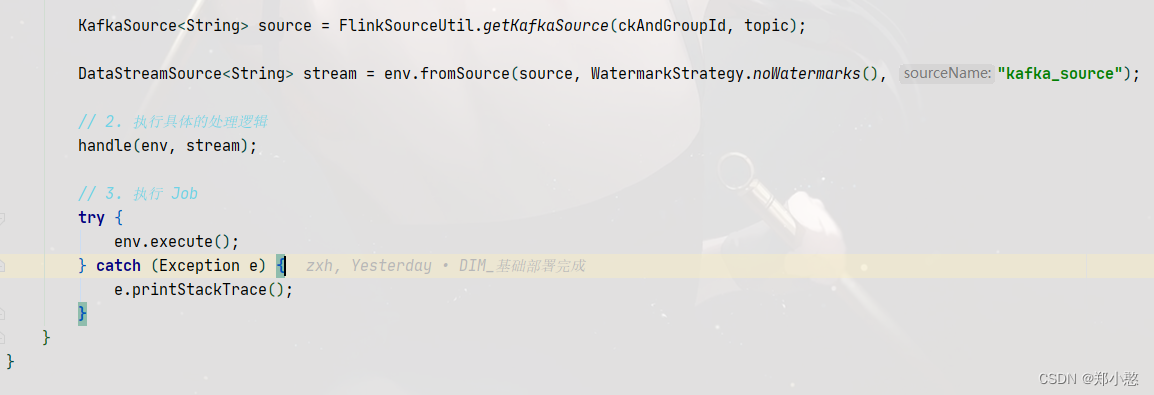
 再写一个抽象类,测试阶段可以把状态后端和检查点给注释掉,可以提高效率
再写一个抽象类,测试阶段可以把状态后端和检查点给注释掉,可以提高效率

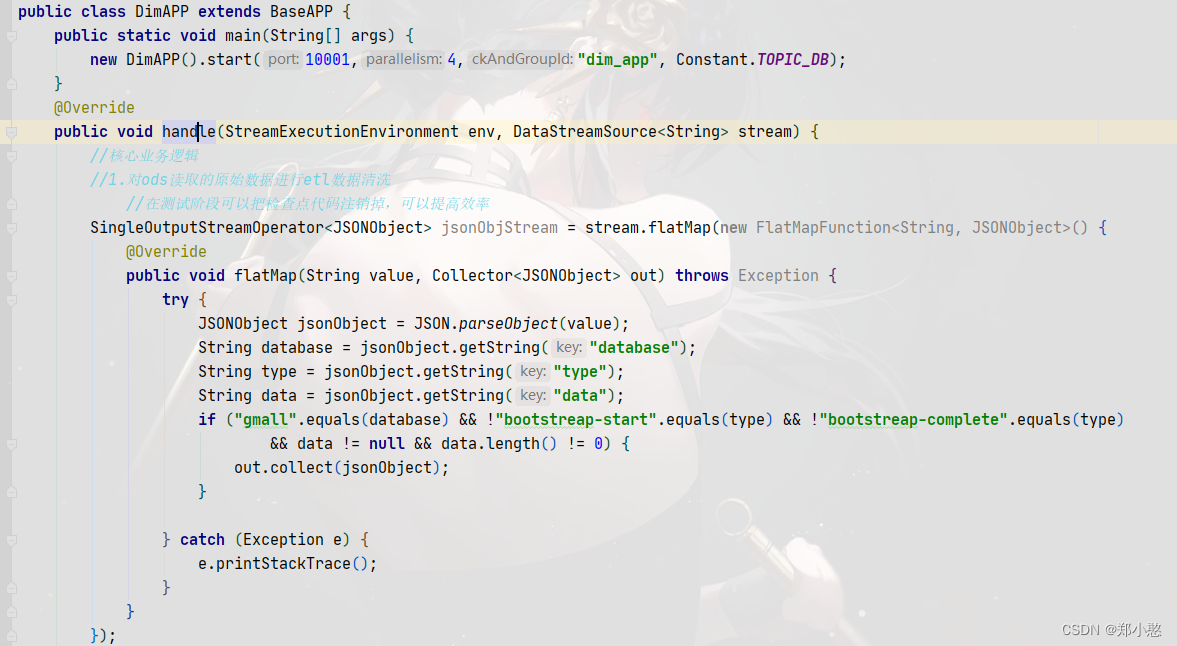
再写一个主程序继承抽象类中的方法,并在程序中对数据进行etl
做这个开发是因为:在实际开发操作中,你的kafka主题中会有大量的数据但是需求并不需要所有数据,所有我们要对数据进行清洗,把需要的数据保存在flink流中,为下流的开发做好数据保障!
首先创建工具类
再写一个抽象类,测试阶段可以把状态后端和检查点给注释掉,可以提高效率
再写一个主程序继承抽象类中的方法,并在程序中对数据进行etl