点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月07日更新到: Java-141 深入浅出 MySQL Spring事务失效的常见场景与解决方案详解(3) MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Sink 的基本概念等内容
- Sink的相关信息 配置与使用
- Sink案例写入Redis

JDBC Sink 详细解析
JDBC Sink 概述
在 Apache Flink 中,JDBC Sink 是一个重要的数据输出组件,它允许将流处理或批处理后的数据通过 JDBC 连接写入到关系型数据库中。其中 MySQL 是最常用的目标数据库之一。
核心功能
- 数据持久化:将实时处理的结果保存到持久化存储
- 系统集成:与其他基于 SQL 的系统进行数据交换
- 事务支持:可配置的事务保证数据一致性
典型应用场景
- 实时分析结果存储
- 用户行为数据归档
- 业务指标持久化
- ETL 流程中的数据加载
实现方式
使用 JdbcSink 类
Flink 提供了内置的 JdbcSink.sink() 方法来创建 JDBC Sink。基本使用模式如下:
java
DataStream<User> users = ...;
users.addSink(JdbcSink.sink(
"INSERT INTO users (id, name, age) VALUES (?, ?, ?)",
(statement, user) -> {
statement.setInt(1, user.getId());
statement.setString(2, user.getName());
statement.setInt(3, user.getAge());
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/test")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("password")
.build()
));配置选项
-
连接参数:
- JDBC URL
- 驱动类名
- 用户名和密码
- 连接池配置(可选)
-
执行参数:
- 批处理大小
- 重试策略
- 超时设置
性能优化建议
- 合理设置批处理大小(通常 100-1000 条记录)
- 考虑使用连接池管理数据库连接
- 对大表插入考虑使用批量插入语法
- 在高吞吐场景下监控数据库性能
注意事项
- 确保 JDBC 驱动版本兼容
- 处理网络中断和数据库故障
- 考虑数据去重机制
- 监控写入延迟和错误率
扩展功能
- 自定义 SQL 语句生成
- 支持 UPSERT 操作
- 与 Flink 状态后端集成
- 指标收集和监控
Flink JDBC Sink 简介
Flink 提供了 JdbcSink 连接器,它是基于标准 JDBC 协议的 Sink 实现,可以将流处理中的数据高效地写入各种支持 JDBC 的关系型数据库,包括 MySQL、PostgreSQL、Oracle 等。这个连接器是 Flink 生态系统的重要组成部分,为数据从流处理系统到关系型数据库的传输提供了标准化的解决方案。
核心功能特性
- 多数据库支持:通过 JDBC 驱动兼容各类关系型数据库
- 批处理优化:支持批量写入模式提升性能
- 事务保证:提供精确一次(exactly-once)的语义保证
- 重试机制:内置连接失败后的自动重试功能
使用要求
在使用 JDBC Sink 时,需要提供以下关键配置信息:
-
数据库连接信息:
- JDBC URL(如:jdbc:mysql://localhost:3306/db_name)
- 用户名和密码
- 连接池配置(可选)
-
SQL 语句:
- 支持 INSERT/UPDATE 等DML语句
- 可以使用预处理语句(PreparedStatement)形式
- 支持通过参数绑定动态传值
-
数据类型映射:
- Flink 数据类型与数据库类型的自动转换
- 支持自定义类型序列化器
典型应用场景
以 MySQL 为例,Flink JdbcSink 的工作流程是:
- 从数据流中接收记录
- 根据配置的SQL模板准备语句
- 通过JDBC连接池获取数据库连接
- 执行批量写入操作
- 提交事务保证数据一致性
java
// 示例:创建JdbcSink写入MySQL
JdbcSink.sink(
"INSERT INTO user_actions (user_id, action_type, timestamp) VALUES (?, ?, ?)",
(ps, record) -> {
ps.setString(1, record.getUserId());
ps.setString(2, record.getActionType());
ps.setTimestamp(3, new Timestamp(record.getTimestamp()));
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/flink_db")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("flink_user")
.withPassword("password")
.build()
);性能优化建议
- 合理设置批处理大小(batch size)
- 根据网络延迟调整批处理间隔
- 使用连接池管理数据库连接
- 对频繁更新的表考虑使用UPSERT语法
Flink 到 MySQL 的基本步骤
将数据流写入 MySQL 的步骤主要包括以下几点:
- 依赖库配置:确保在项目中引入了 Flink 和 MySQL 相关的依赖库,通常需要配置 Maven 或 Gradle。
- 定义数据源和数据流:创建并处理数据流。
- 配置 JDBC Sink:提供数据库的连接信息和插入 SQL 语句。
- 启动任务:将数据流写入 MySQL。
优化建议
在实际项目中,向 MySQL 插入大量数据时,应考虑以下优化策略:
- 批量插入:通过 JdbcExecutionOptions 配置批量插入,可以大幅提升写入性能。
- 连接池:对于高并发的写入操作,建议使用连接池来减少数据库连接开销。
- 索引优化:为插入的表配置合适的索引,可以提高查询性能,但在大量写入时,索引可能会降低- 插入速度,因此需要权衡。
- 数据分片:对于非常大规模的数据,可以考虑将数据分片并行写入不同的 MySQL 实例或分区表中。
案例:流数据下沉到MySQL
添加依赖
xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>编写代码
一个Person的类,对应MySQL中的一张表的字段。 模拟几条数据流,写入到 MySQL中。
java
package icu.wzk;
public class SinkSqlTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Person> data = env.getJavaEnv().fromElements(
new Person("wzk", 18, 1),
new Person("icu", 20, 1),
new Person("wzkicu", 13, 2)
);
data.addSink(new MySqlSinkFunction());
env.execute();
}
public static class MySqlSinkFunction extends RichSinkFunction<Person> {
private PreparedStatement preparedStatement = null;
private Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
String url = "jdbc:mysql://h122.wzk.icu:3306/flink-test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC";
String username = "hive";
String password = "hive@wzk.icu";
connection = DriverManager.getConnection(url, username, password);
String sql = "INSERT INTI PERSON(name, age, sex) VALUES(?, ?, ?)";
preparedStatement = connection.prepareStatement(sql);
}
@Override
public void invoke(Person value, Context context) throws Exception {
preparedStatement.setString(1, value.getName());
preparedStatement.setInt(2, value.getAge());
preparedStatement.setInt(3, value.getSex());
preparedStatement.executeUpdate();
}
@Override
public void close() throws Exception {
if (null != connection) {
connection.close();
}
if (null != preparedStatement) {
preparedStatement.close();
}
}
}
public static class Person {
private String name;
private Integer age;
private Integer sex;
public Person() {
}
public Person(String name, Integer age, Integer sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
}
}数据库配置
我们新建一张表出来,person表,里边有我们需要的字段。 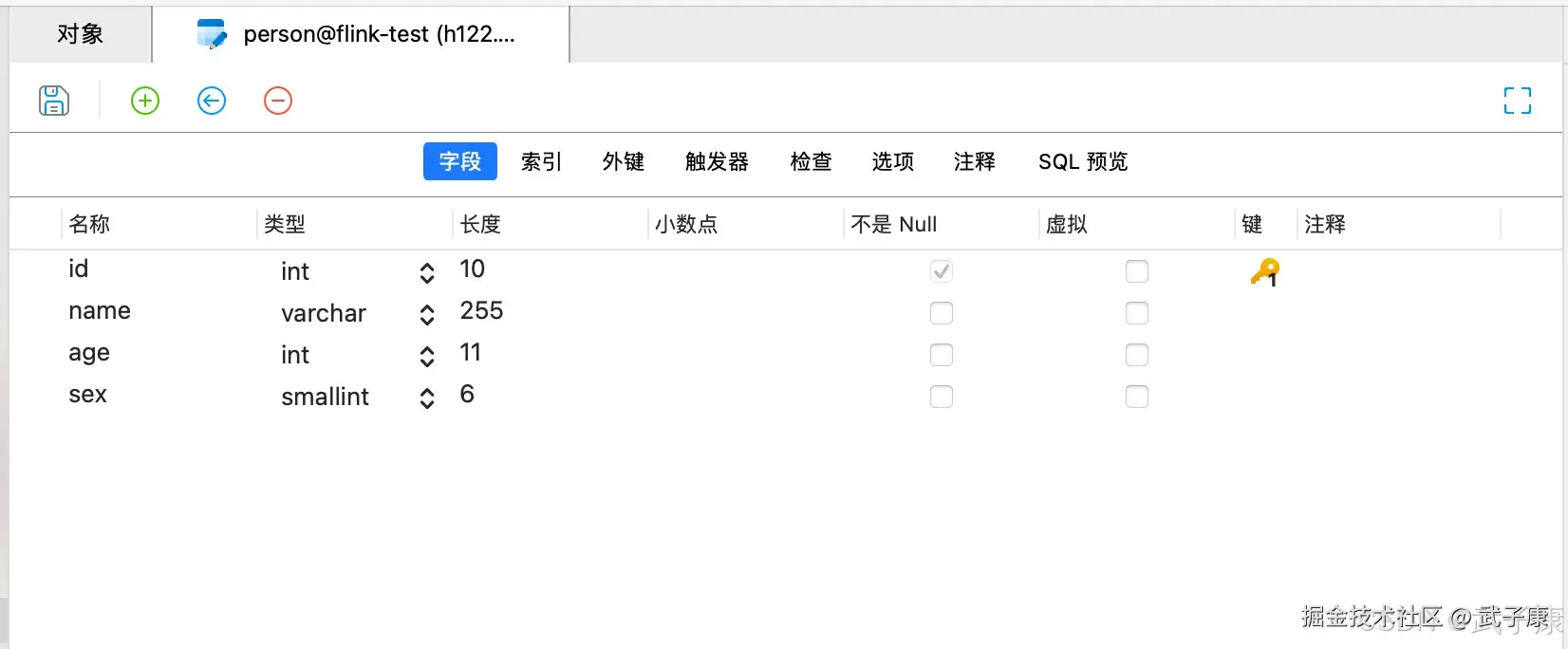
运行代码
我们运行代码,等待运行结束。 
查看结果
查看数据库中的数据,我们可以看到刚才模拟的数据已经成功写入了。 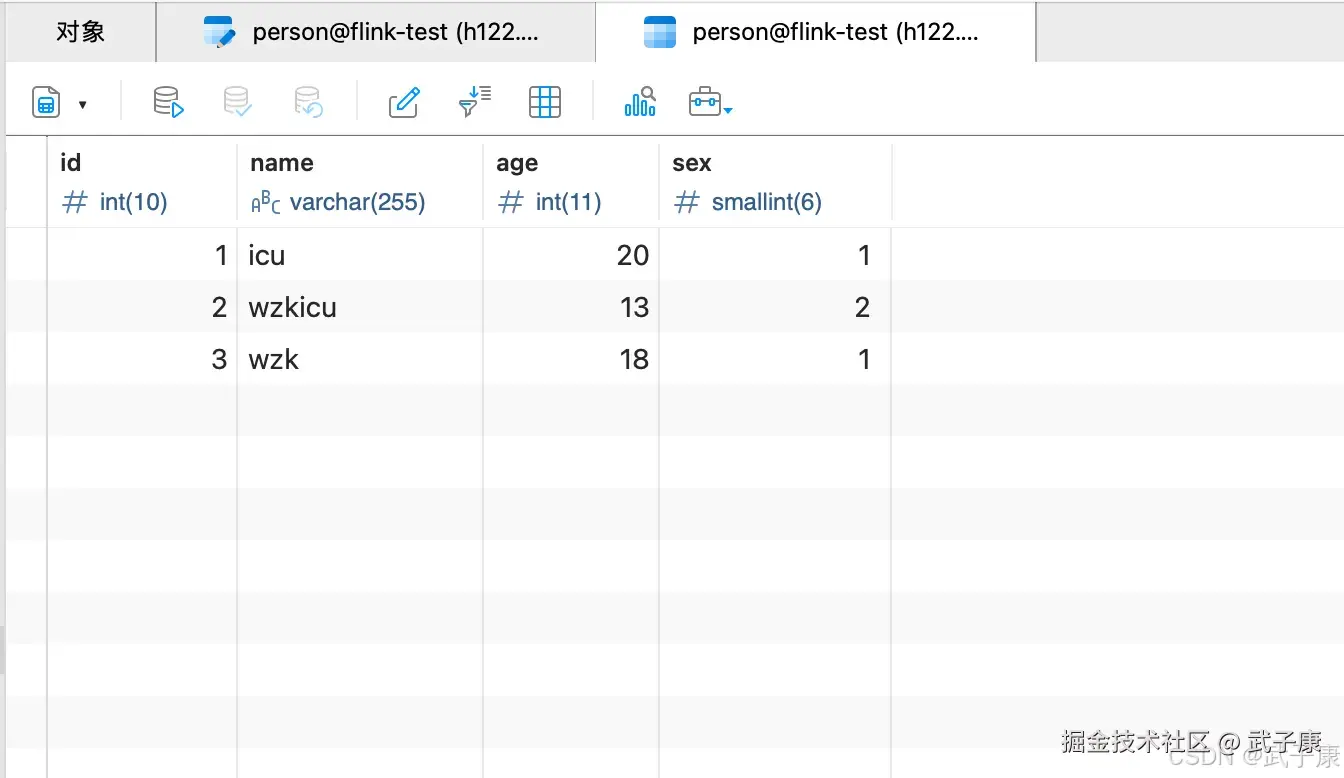
案例:写入到Kafka
编写代码
java
package icu.wzk;
public class SinkKafkaTest {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> data = env.socketTextStream("localhost", 9999, '\n', 0);
String brokerList = "h121.wzk.icu:9092";
String topic = "flink_test";
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(brokerList, topic, new SimpleStringSchema());
data.addSink(producer);
env.execute("SinkKafkaTest");
}
}运行代码
启动一个 nc
shell
nc -lk 9999我们通过回车的方式,可以发送数据。 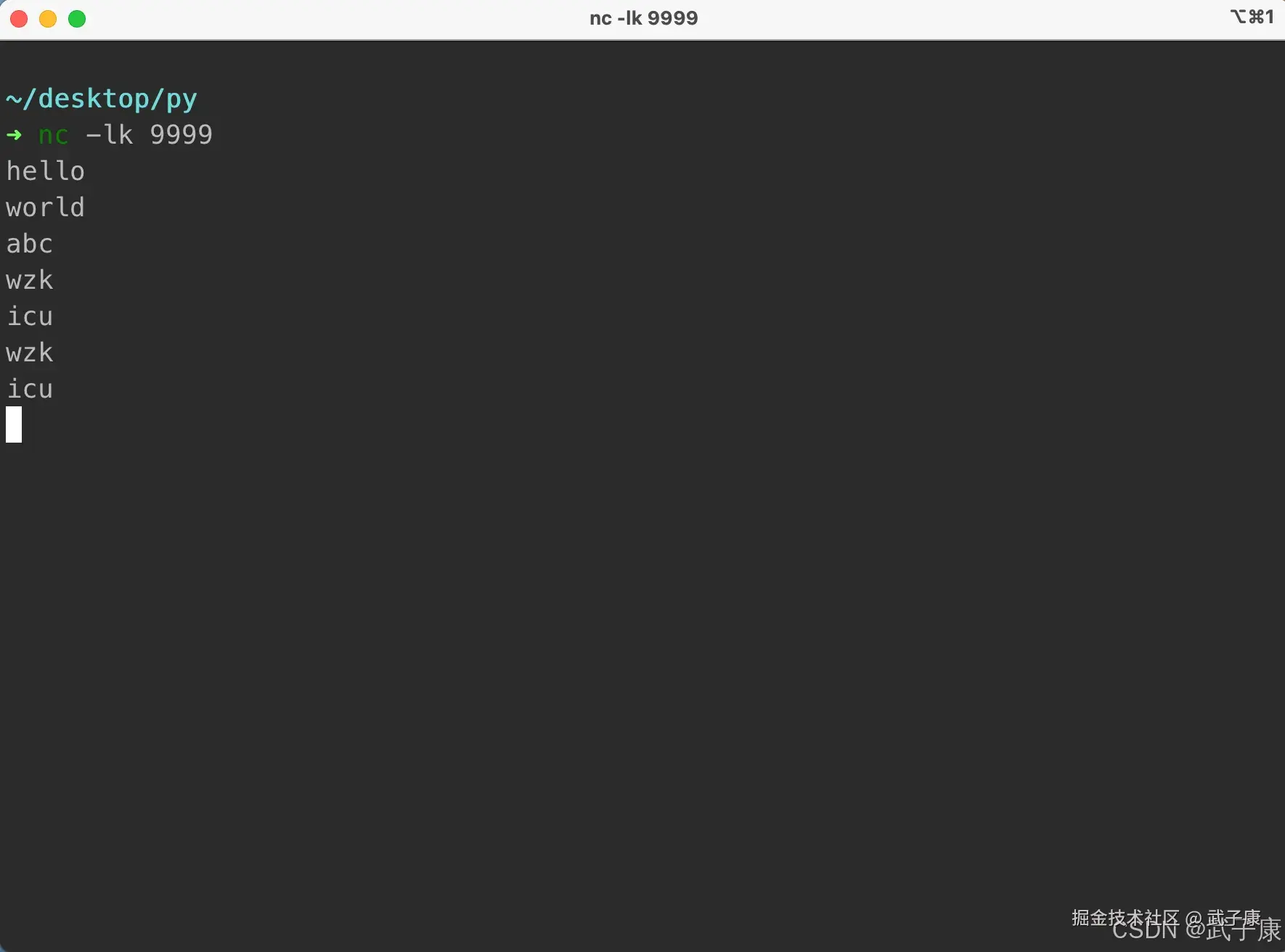 Java 程序中等待
Java 程序中等待 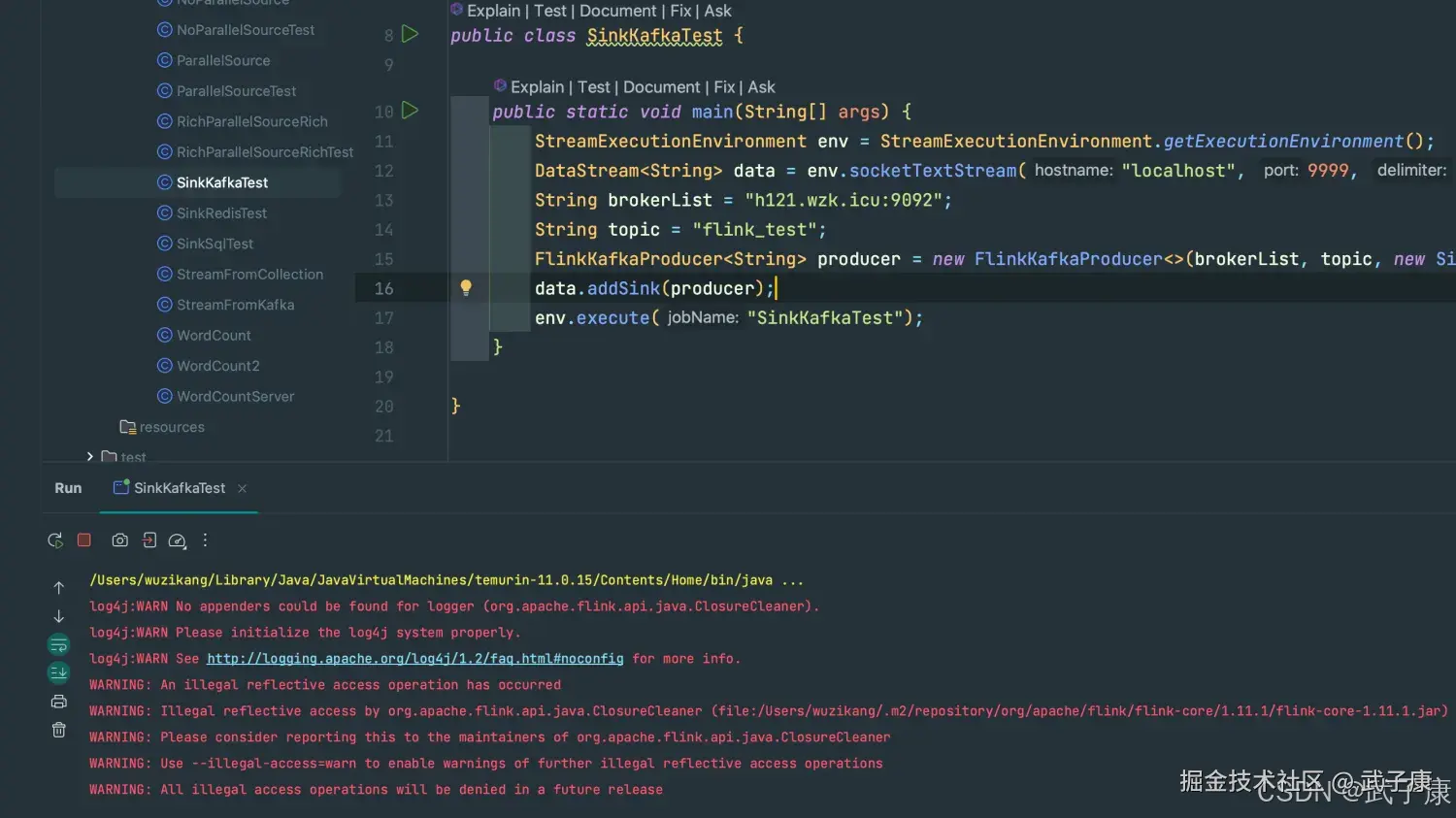
查看结果
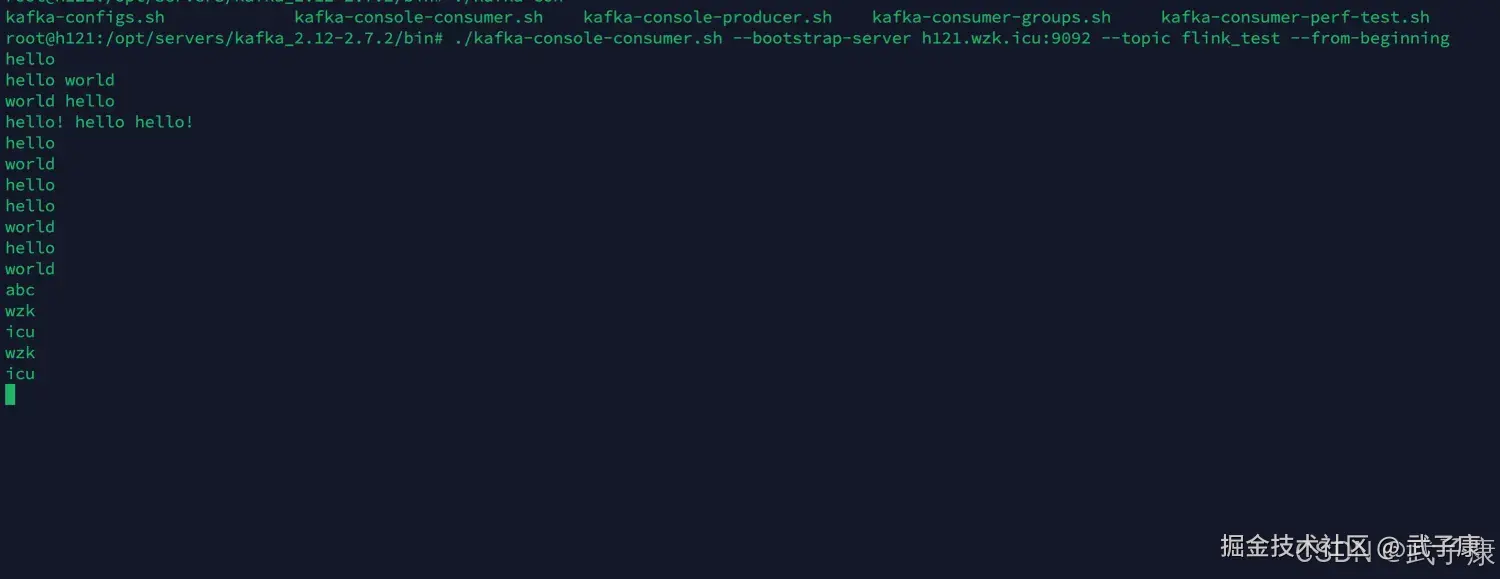
我们登录到服务器查看信息
shell
./kafka-console-consumer.sh --bootstrap-server h121.wzk.icu:9092 --topic flink_test --from-beginning可以看到刚才的数据已经写入了: