Dictionary 底层结构
与Java中的HashMap结构类似。(Java工作者应该很熟悉)Dictionary底层数据结构是一个存放指针的数组。(数组 + 链表)
Dictionary 字典型数据结构,是以关键字Key 和 值Value 进行一一映射的。这种映射关系是用一个Hash函数来建立的。解决Hash冲突的方法同样是拉链法。
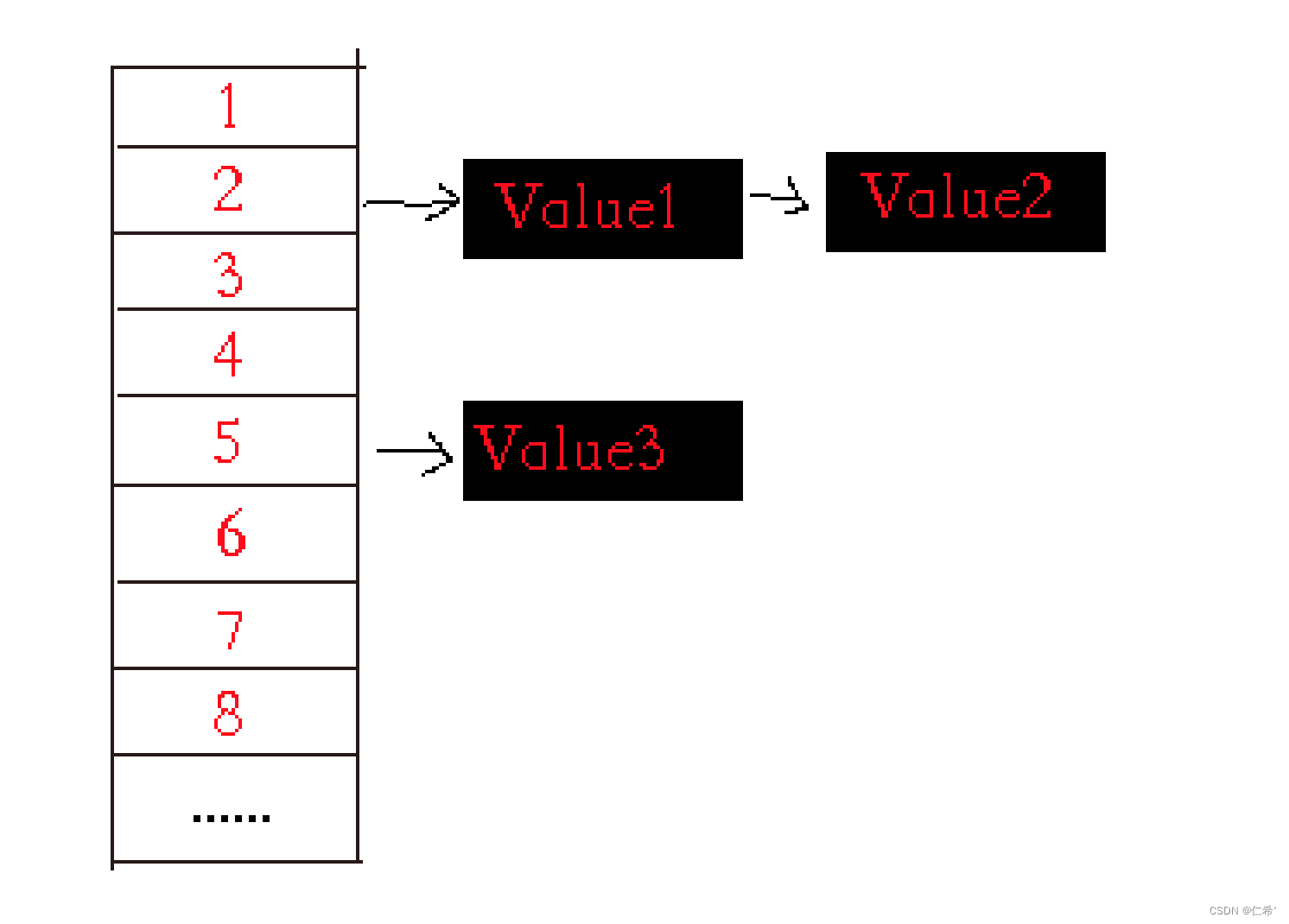
当我们实例化 new Dictionary() 后,内部的数组是0个数组的状态。
Add 接口:Insert 的代理
cs
public void Add(TKey key, TValue value)
{
Insert(key, value, true);
}Insert 接口
它们有专门的方法来计算到底该使用多大的数组。源码 HashHelpers 中,primes数值是这样定义的:
cs
public static readonly int[] primes = {
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369};
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException(Environment.GetResourceString("Arg_HTCapacityOverflow"));
Contract.EndContractBlock();
for (int i = 0; i < primes.Length; i++)
{
int prime = primes[i];
if (prime >= min) return prime;
}
//outside of our predefined table.
//compute the hard way.
for (int i = (min | 1); i < Int32.MaxValue;i+=2)
{
if (IsPrime(i) && ((i - 1) % Hashtable.HashPrime != 0))
return i;
}
return min;
}
// Returns size of hashtable to grow to.
public static int ExpandPrime(int oldSize)
{
int newSize = 2 * oldSize;
// Allow the hashtables to grow to maximum possible size (~2G elements) before encoutering capacity overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Contract.Assert( MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
return GetPrime(newSize);
}扩容操作:当没有指定默认值时,初始值是3。每次扩容会调用ExpandPrime,会先在原有的基础上扩大两倍,然后再调用GetPrime方法获取最终扩容长度。例如:3->7->17->37->....
cs
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
int targetBucket = hashCode % buckets.Length;当调用函数获得Hash哈希值后,还需要对哈希地址做余操作,以确定地址落在 Dictionary 数组长度范围内不会溢出。紧接着对指定数组单元格内的链表元素做遍历操作,找出空出来的位置将值填入。
当获得Hash值的数组索引后,我们知道了该将数据存放在哪个数组位置上,如果该位置已经有元素被推入,则需要将其推入到链表的尾部。
每存放一个元素,不论是否发生hash碰撞,记录剩余单元格数量的变量 freeCount-1。如果freeCount == 0,执行扩容操作。
Remove 接口
用哈希函数 comparer.GetHashCode 再除余后得到范围内的地址索引,再做余操作确定地址落在数组范围内,从哈希索引地址开始,查找冲突的元素的Key是否与需要移除的Key值相同,相同则进行移除操作并退出。
Remove 的移除操作并没有对内存进行删减,而只是将其单元格置空,这是位了减少了内存的频繁操作。
ContainsKey 接口
它调用了 FindEntry 函数,FindEntry 查找Key值位置的方法跟前面提到的相同。从用Key值得到的哈希值地址开始查找,查看所有冲突链表中,是否有与Key值相同的值,找到即刻返回该索引地址。
TryGetValue 接口
同样调用FindEntry接口
哈希函数中的比较函数
源码中,对数字,byte,有'比较'接口(IEquatable<T>),和没有'比较'接口,四种方式进行了区分对待。
- 数字和byte:固定的比较函数
- 有'比较'接口(IEquatable<T>)的实体:GenericEqualityComparer<T>来获得哈希函数
- 没有'比较'接口(IEquatable)的实体,如果继承了 Nullable<U> 接口: NullableEqualityComparer
- 什么都不是:ObjectEqualityComparer<T>,比较内存地址
非线程安全
Dictionary 同List一样并不是线程安全的组件,官方源码中进行了这样的解释。
cs
** Hashtable has multiple reader/single writer (MR/SW) thread safety built into
** certain methods and properties, whereas Dictionary doesn't. If you're
** converting framework code that formerly used Hashtable to Dictionary, it's
** important to consider whether callers may have taken a dependence on MR/SW
** thread safety. If a reader writer lock is available, then that may be used
** with a Dictionary to get the same thread safety guarantee. Hashtable在多线程读写中是线程安全的,而 Dictionary 不是。如果要在多个线程中共享Dictionaray的读写操作,就要自己写lock以保证线程安全。
总结
Dictionaray是由数组构成,并且由哈希函数完成地址构建,由拉链法冲突解决方式来解决冲突。
从效率上看,同List一样最好在实例化对象时,即 new 时尽量确定大致数量 会更加高效,另外用数值方式做Key比用类实例方式作为Key值更加高效率。
从内存操作上看,大小以3->7->17->37->....的速度,每次增加2倍多的顺序进行,删除时,并不缩减内存。
如果想在多线程中,共享 Dictionary 则需要进行我们自己进行lock操作。