系列文章目录
第1天总结:spark基础学习
- 1- Spark基本介绍(了解)
- 2- Spark入门案例(掌握)
- 3- 常见面试题(掌握)
文章目录
- 系列文章目录
- 前言
- 一、Spark基本介绍
-
-
- 1、Spark是什么
-
- [1.1 定义](#1.1 定义)
- [1.2 Spark与MapReduce对比(面试题)](#1.2 Spark与MapReduce对比(面试题))
- 2、Spark特点
- 3、Spark框架模块
- 二、Spark入门案例(掌握)
-
- 总结
-
- 常见面试题
- 1.spark和mr的区别
-
- [Spark和MR(通常指的是Hadoop MapReduce)在多个方面存在显著的区别。](#Spark和MR(通常指的是Hadoop MapReduce)在多个方面存在显著的区别。)
- 计算速度与迭代计算:
- 并行度与任务调度:
- 编程模型与灵活性:
- 资源申请与释放:
- 2.Spark的四大特性:
-
- Speed(高速性):
- [Ease of Use(易用性):](#Ease of Use(易用性):)
- Generality(通用性):
- [Runs Everywhere(随处运行):](#Runs Everywhere(随处运行):)
- 3.spark为什么执行快
- 4.Spark词频统计的步骤以及每步涉及到的算子作用:
前言
本文就介绍了spark学习的基础内容
以及详细介绍了词频统计案例。
一、Spark基本介绍
1、Spark是什么
1.1 定义
Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
1.2 Spark与MapReduce对比(面试题)
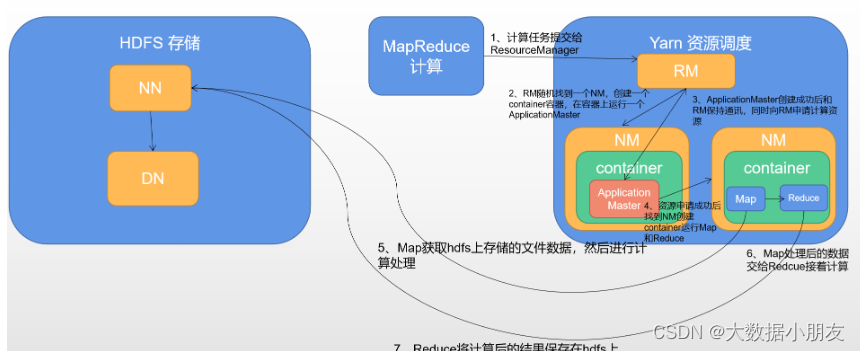
MapReduce架构回顾
-
MapReduce的主要缺点:
- 1- MapReduce是基于进程进行数据处理,进程相对线程来说,在创建和销毁的过程比较消耗资源,并且速度比较慢
- 2- MapReduce运行的时候,中间有大量的磁盘IO过程。也就是磁盘数据到内存,内存到磁盘反复的读写过程
- 3- MapReduce只提供了非常低级(底层)的编程API,如果想要开发比较复杂的程序,那么就需要编写大量的代码。
-
Spark相对MapReduce的优点:
- 1- Spark底层是基于线程来执行任务
- 2- 引入了新的数据结构------RDD(弹性分布式数据集),能够让Spark程序主要基于内存进行运行。内存的读写数据相对磁盘来说,要快很多
- 3- Spark提供了更加丰富的(顶层)编程API,能够非常轻松的实现功能开发
2、Spark特点
快速记忆: speed, easy use , general , runs everywhere
-
高效性
- 计算速度快
- 提供了一个全新的数据结构RDD(弹性分布式数据集)。整个计算操作,基于内存计算。当内存不足的时候,可以放置到磁盘上。整个流程是基于DAG(有向无环图)执行方案。
- Task线程完成计算任务执行
- 计算速度快
-
易用性
- 支持多种语言开发 (Python,SQL,Java,Scala,R),降低了学习难度
-
通用性
- 在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLlib 及GraphX在内的多个工具库(模块),我们可以在一个应用中无缝地使用这些工具库。
-
兼容性(任何地方运行)
-
支持三方工具接入
- 存储工具
- hdfs
- kafka
- hbase
- 资源调度
- yarn
- Kubernetes(K8s容器)
- standalone(spark自带的)
- 高可用
- zookeeper
- 存储工具
-
支持多种操作系统
- Linux
- windows
- Mac
-
3、Spark框架模块

- Spark Core API :实现了 Spark 的基本功能。包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。数据结构RDD。--重点学习
- Spark SQL :我们可以使用 SQL处理结构化数据。数据结构:Dataset/DataFrame = RDD + Schema。--重点学习
- Structured Streaming :基于Spark SQL进行流式/实时的处理组件,主要处理结构化数据。--部分学习
- Streaming(Spark Streaming):提供的对实时数据进行流式计算的组件,底层依然是离线计算,只不过时间粒度很小,攒批。--了解
- MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等。--了解
- GraphX:Spark中用于图计算的API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。--了解
二、Spark入门案例(掌握)
1、需求描述
读取文本文件,文件内容是一行一行的文本,每行文本含有多个单词,单词间使用空格分隔。统计文本中每个单词出现的总次数。WordCount词频统计。
shell
文本内容如下:
hello hello spark
hello heima spark2、需求分析
Python编程思维的实现过程:

PySpark实现过程:
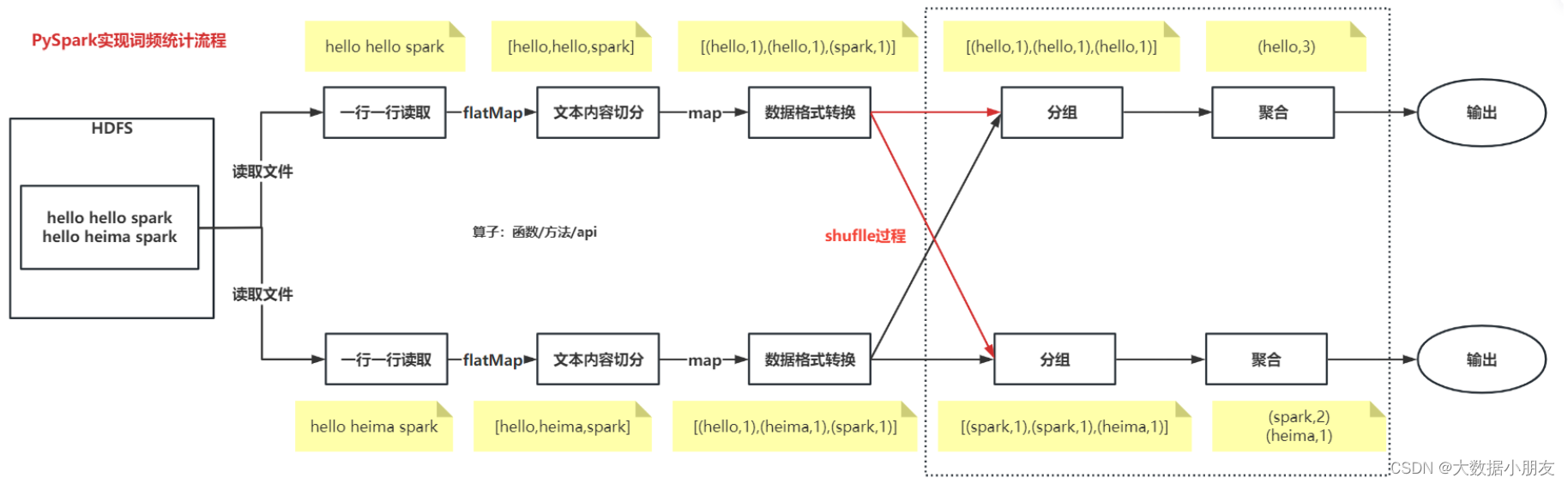
编程过程总结:
-
1.创建SparkContext对象
-
2.数据输入
-
3.数据处理
- 3.1文本内容切分
- 3.2数据格式转换
- 3.3分组和聚合
-
4.数据输出
-
5.释放资源
3、代码编写
可能出现的错误:
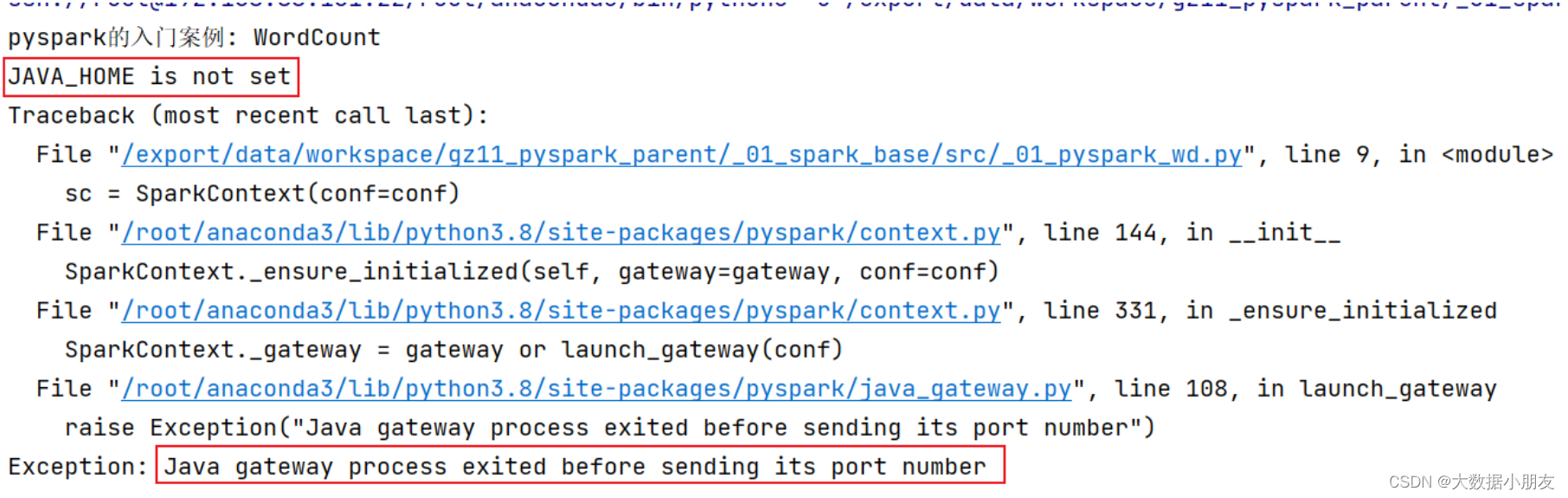
结果: 可能会报错: JAVA_HOME is not set
原因: 找不到JAVA_HOME环境
解决方案: 需要在代码中指定远端的环境地址 以及 在node1环境中初始化JAVA_HOME地址
第一步:在node1的 /root/.bashrc 中配置初始化环境的配置
vim /root/.bashrc
export JAVA_HOME=/export/server/jdk1.8.0_241
第二步: 在main函数上面添加以下内容
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'注意: jdk路径配置到node1的 /root/.bashrc 文件的第三行,示例如下:

代码:
from pyspark import SparkConf, SparkContext
import os
绑定指定的Python解释器
os.environ'SPARK_HOME' = '/export/server/spark'
os.environ'PYSPARK_PYTHON' = '/root/anaconda3/bin/python3'
os.environ'PYSPARK_DRIVER_PYTHON' = '/root/anaconda3/bin/python3'
创建main函数
if name == 'main ':
print("Spark入门案例: WordCount词频统计")
# 1- 创建SparkContext对象
"""
setAppName:设置PySpark程序运行时的名称
setMaster:设置PySpark程序运行时的集群模式
"""
conf = SparkConf()\
.setAppName('spark_wordcount_demo')\
.setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2- 数据输入
"""
textFile:支持读取HDFS文件系统和linux本地文件系统
HDFS文件系统:hdfs://node1:8020/文件路径
linux本地文件系统:file:///文件路径
"""
init_rdd = sc.textFile("file:///export/data/gz16_pyspark/01_spark_core/data/content.txt")
# 3- 数据处理
# 文本内容切分
"""
flatMap运行结果:
输入数据:['hello hello spark', 'hello heima spark']
输出数据:['hello', 'hello', 'spark', 'hello', 'heima', 'spark']
map运行结果:
输入数据:['hello hello spark', 'hello heima spark']
输出数据:[['hello', 'hello', 'spark'], ['hello', 'heima', 'spark']]
"""
# flatmap_rdd = init_rdd.map(lambda line: line.split(" "))
flatmap_rdd = init_rdd.flatMap(lambda line: line.split(" "))
# 数据格式转换
"""
输入数据:['hello', 'hello', 'spark', 'hello', 'heima', 'spark']
输出数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]
"""
map_rdd = flatmap_rdd.map(lambda word: (word,1))
# 分组和聚合
"""
输入数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]
输出数据:[('hello', 3), ('spark', 2), ('heima', 1)]
reduceByKey底层运行过程分析:
1- 该算子同时具备分组和聚合的功能。而且是先对数据按照key进行分组,对相同key的value会形成得到List列表。再对分组后的value列表进行聚合。
2- 分组和聚合功能不能分割,也就是一个整体
结合案例进行详细分析:
1- 分组
输入数据:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1), ('spark', 1)]
分组后的结果:
key value列表
hello [1,1,1]
spark [1,1]
heima [1]
2- 聚合(以hello为例)
lambda agg,curr: agg+curr -> agg表示中间临时value聚合结果,默认取列表中的第一个元素;curr表示当前遍历到的value元素,默认取列表中的第二个元素
最后发现已经遍历到value列表的最后一个元素,因此聚合过程结果。最终的hello的次数,就是3
"""
result = map_rdd.reduceByKey(lambda agg,curr: agg+curr)
# 4- 数据输出
"""
collect():用来收集数据,返回值类型是List列表
"""
print(result.collect())
# 5- 释放资源
sc.stop()###运行结果:

总结
常见面试题
1.spark和mr的区别
Spark和MR(通常指的是Hadoop MapReduce)在多个方面存在显著的区别。
Spark在计算速度、并行度、资源利用率、编程灵活性和资源申请与释放等方面,相较于Hadoop MapReduce具有显著的优势。这使得Spark在处理大规模数据集和分析任务时,成为了一个更加高效和灵活的选择。
以下是它们之间的主要差异:
计算速度与迭代计算:
Spark:除了需要shuffle的计算外,Spark将结果/中间结果持久化到内存中,因此避免了频繁的磁盘I/O操作。这使得Spark在处理需要频繁读写中间结果的迭代计算时,比MR具有更高的效率。
MR:所有的中间结果都需要写入磁盘,并在下一个阶段从磁盘中读取,这导致了较高的磁盘I/O开销和较低的计算速度。
并行度与任务调度:
Spark:将不同的计算环节抽象为Stage,允许多个Stage既可以串行执行,又可以并行执行。这种基于DAG(有向无环图)的任务调度执行机制,提高了任务的并行度和整体执行效率。
MR:任务之间的衔接涉及I/O开销,且下个任务的执行依赖于上个任务的结果,这限制了其并行度和处理复杂、多阶段计算任务的能力。
资源模型:
Spark:基于线程,采用多进程多线程模型。在同一个节点上,多个任务可以共享内存和资源,提高了数据和资源的利用率。
MR:基于进程,采用多进程单线程模型。每个任务都是独立的进程,申请资源和数据都是独立进行的,这导致了较高的资源申请和释放开销。
编程模型与灵活性:
Spark:提供了多种数据集操作类型,包括转换算子、行动算子和持久化算子,使得编程模型比Hadoop MapReduce更灵活。同时,Spark支持使用Scala、Java、Python和R语言进行编程,具有更好的易用性。
MR:只有map和reduce两个类,相当于Spark中的两个算子,其编程模型相对较为简单和固定。
资源申请与释放:
Spark:多个task运行在同一个进程中,这个进程会伴随Spark应用程序的整个生命周期。即使在没有作业进行时,进程也是存在的,这避免了频繁的进程创建和销毁开销。
MR:每个task都是一个独立的进程,当task完成时,进程也会结束。这导致了较高的进程创建和销毁开销。
综上所述,
2.Spark的四大特性:
Speed(高速性):
Spark是一个基于内存计算的分布式计算框架,能够在内存中直接处理数据,减少了磁盘I/O的开销,从而显著提高了计算速度。
官方数据表明,如果数据从内存中读取,Spark的速度可以高达Hadoop MapReduce的100多倍;即使数据从磁盘读取,Spark的速度也是Hadoop MapReduce的10倍以上。
Spark通过DAG(有向无环图)执行引擎支持无环数据流,使得数据处理更加高效。
Ease of Use(易用性):
Spark提供了丰富的API,支持多种编程语言,如Scala、Java、Python和R,使得用户可以轻松地开发复杂的分布式应用程序。
Spark的易用性还体现在其支持的高级功能上,如SQL查询、机器学习和图计算等,这些功能都通过简洁的代码接口提供。
Generality(通用性):
Spark生态圈即BDAS(伯克利数据分析栈)包含了多个组件,如Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等,这些组件能够无缝集成并提供一站式解决平台。
Spark Core提供内存计算框架,Spark SQL支持即席查询,Spark Streaming处理实时数据流,MLlib和MLbase支持机器学习,GraphX则专注于图处理。
Runs Everywhere(随处运行):
Spark具有很强的适应性,能够读取多种数据源,如HDFS、Cassandra、HBase、S3和Techyon等。
Spark支持多种部署模式,包括Hadoop YARN、Apache Mesos、Standalone(独立部署)以及云环境(如Kubernetes)等,使得用户可以根据自身需求选择合适的部署方式。
综上所述,Spark的四大特性包括高速性、易用性、通用性和随处运行,这些特性使得Spark在处理大规模数据集和分析任务时表现出色,成为大数据处理领域的重要工具。
3.spark为什么执行快
Spark执行速度快的原因:
Spark通过内存计算、DAG执行引擎、RDD、任务调度优化、容错性和分布式计算等特性,实现了高性能的数据处理能力,从而能够在处理大规模数据集和分析任务时表现出色。
内存计算:
Spark采用了内存计算的方式,将数据和中间计算结果存储在内存中,而不是传统的硬盘中。
由于内存的速度远快于硬盘,因此Spark能够避免频繁的磁盘I/O操作,从而显著提高了数据处理的速度。
官方数据表明,如果数据从内存中读取,Spark的速度可以高达Hadoop MapReduce的100多倍;即使数据从磁盘读取,Spark的速度也是Hadoop MapReduce的10倍以上。
DAG执行引擎:
Spark采用了基于有向无环图(DAG)的执行引擎,将作业转化为一系列的有向无环图进行计算。
DAG执行引擎可以优化任务调度和计算,使得多个任务能够并行执行,进一步提高了计算效率。
弹性分布式数据集(RDD):
RDD是Spark的核心数据模型,提供了对数据集的高效分布式处理。
RDD具有不可变性,但可以通过一系列的转换操作生成新的RDD,并支持在内存中缓存RDD,从而提高计算性能。
任务调度优化:
Spark将用户的代码转化为一系列的任务,并以有向无环图(DAG)的形式进行调度执行。
Spark的任务调度器可以根据数据的依赖关系来优化任务的执行顺序,将多个相关的任务合并在一起执行,减少了任务调度的开销。
容错性:
Spark通过将数据划分成多个分区,并在集群中复制多份数据来实现容错性。
当某个计算节点发生故障时,Spark可以自动将计算任务转移到其他节点上,并重新执行失败的任务,确保了计算的完整性和准确性。
分布式计算:
Spark支持分布式计算,能够将数据分成多个分区,并分布到不同的计算节点上进行并行处理。
这种分布式计算的方式能够充分利用集群资源,提高计算效率。
4.Spark词频统计的步骤以及每步涉及到的算子作用:
步骤一:基于文本文件创建RDD
使用sc.textFile("/path/to/file.txt")读取文本文件,并创建一个RDD(弹性分布式数据集)。
涉及到的算子:无。这是数据输入步骤,不涉及Spark的转换或行动算子。
步骤二:按空格拆分作扁平化映射
使用flatMap(_.split(" "))将RDD中的每一行文本按空格拆分成单词,并将所有单词合并成一个新的RDD。
涉及到的算子:flatMap。这是一个转换算子(Transformation),它会对RDD中的每个元素应用一个函数,并返回一个新的RDD,其中包含所有函数输出的元素。
步骤三:将单词数组映射成二元组数组
使用map((_, 1))将每个单词映射为一个二元组(单词,1),表示该单词出现了一次。
涉及到的算子:map。这也是一个转换算子,它将RDD中的每个元素转换成一个新的元素。
步骤四:将二元组数组按键归约
使用reduceByKey(_ + _)对二元组RDD进行归约操作,将具有相同键(即单词)的二元组合并,并将它们的值(即计数)相加。
涉及到的算子:reduceByKey。这是一个转换算子,它会对具有相同键的元素进行归约操作,并返回一个新的RDD。
步骤五:将词频统计结果按次数降序排列
使用sortBy(_._2, false)对词频统计结果进行排序,按照单词出现的次数从高到低排序。
涉及到的算子:sortBy。这是一个转换算子,它会对RDD中的元素进行排序,并返回一个新的RDD。
步骤六(可选):收集并输出结果
使用collect将排序后的词频统计结果收集到驱动程序节点,并使用foreach(println)输出结果。
涉及到的算子:collect和foreach。collect是一个行动算子(Action),它会触发Spark作业的执行,并将RDD中的所有元素收集到驱动程序节点。foreach是一个行动算子,它会对RDD中的每个元素应用一个函数,但该函数不返回任何值。
案例总结:
在上述步骤中,flatMap、map、reduceByKey和sortBy是转换算子,它们用于创建和转换RDD;而collect和foreach是行动算子,它们会触发Spark作业的执行,并返回结果或进行其他操作。这些算子的组合使用,使得Spark能够高效地进行词频统计任务。