一、要求
根据用户上网的搜索记录对每天的热点搜索词进行统计,以了解用户所关心的热点话题。
要求完成:统计每天搜索数量前3名的搜索词(同一天中同一用户多次搜索同一个搜索词视为1次)。
二、数据

三、配置scala环境
1.下载scala插件
Scala插件的安装有两种方式:在线与离线。我们学习在线安装方式。
启动IDEA,在欢迎界面中选择Configure→Plugins命令,搜索scala进行下载
2.配置scala环境
下载后的scala进行环境配置
在Project Settings->Libraries中添加下载好的Scala

3.创建scala class

4.编写scala代码
dart
def main(args: Array[String]): Unit = { // 初始化 Spark 会话
val spark = SparkSession.builder.appName("HotSearchWords").master("local[*]").getOrCreate
// 读取文件 key.txt
var df = spark.read.option("header", "false").option("delimiter", ",").csv("data/keywords.txt")
df = df.withColumnRenamed("_c0", "date").withColumnRenamed("_c1", "user").withColumnRenamed("_c2", "search_word")
// 去重:同一用户在同一天内对同一搜索词的多次搜索视为1次
val dfDistinct = df.dropDuplicates("date", "user", "search_word")
// 统计每个日期每个搜索词的搜索次数
val searchCount = dfDistinct.groupBy("date", "search_word").agg(countDistinct("user").alias("search_count"))
// 定义窗口函数,按日期分区并按搜索次数排序
val window = Window.partitionBy("date").orderBy(col("search_count").desc)
// 使用窗口函数添加排名
val rankedSearchCount = searchCount.withColumn("rank", dense_rank.over(window))
// 过滤出每个日期搜索次数排名前3的搜索词
val top3SearchWords = rankedSearchCount.filter(col("rank").leq(3))
// 对结果按日期降序排序
val sortedTop3SearchWords = top3SearchWords.orderBy(col("date").desc)
// 显示结果
sortedTop3SearchWords.show()
// 结束 Spark 会话
spark.stop()
}
}5.结果展示

遇到的问题
- 运行程序时显示找不到主类
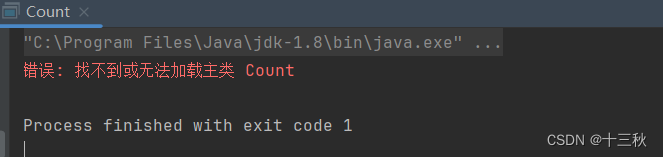
解决方法
- 在Project Structure ->modules中将Language level 改成8 即可解决

小结
-
本次的项目作业是一项富有成效的学术探索,它不仅让我们首次接触并学习了Scala这一现代的多范式编程语言,而且还让我们在实践中深入理解了其面向对象与函数式编程的精妙结合。通过Scala,我们得以高效地编写出既简洁又功能强大的代码,这在统计热点词的项目中表现得尤为明显。我们学会了如何使用Scala的集合操作、模式匹配和高阶函数来处理和分析大量数据,进而识别和统计出那些频繁出现的热点词汇。
-
此外,项目过程中的挑战和问题解决进一步加深了我们对Scala强类型系统和类型推断的理解,这些特性在保证代码安全的同时,也提高了开发效率。我们还体验到了Scala与大数据技术栈的无缝集成,尤其是在与Apache Spark等工具的结合使用中,感受到了Scala在处理大规模数据集时的强大能力。
-
通过这次作业,我们不仅提升了自己的编程技能,还学习了如何使用新的工具和库,这对于我们未来在软件开发和数据分析领域的职业生涯是极其宝贵的。最终,当看到程序成功运行并输出预期结果时,那份成就感和对编程之美的领悟,让我们更加坚定了在技术道路上不断探索和前进的决心。