0、课前补充

less
jiafa () {
result=$(echo " $1 + $2 " | bc )
print "%.2f\n" "$result"
} ##保留小数点两位 薄弱加强点
a=$(df -h | awk 'NR>1 {print $5}' | tr -d '%')
echo "$a"
一、数组
1.1、定义
数组的定义:在集合种指定多个元素。
1.2、元素类型
元素的类型:整数,字符串,可以是浮点。
1.3、数组的作用
数组的作用:一次性的定义多个元素,可以为变量赋值提供便利。
1.4、数组的定义方法:
1.4.1、数组的格式
数组名= (a b c d)
数组名不能重复
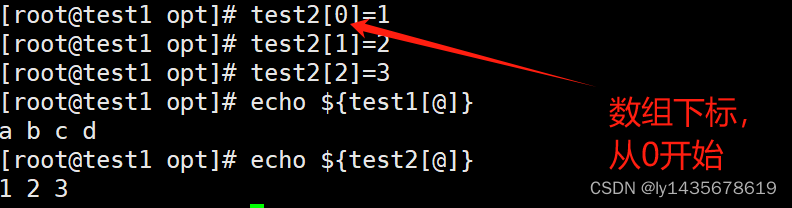
[root@test1 opt]# vim test56.sh
[root@test1 opt]# test1=(a b c d)
[root@test1 opt]# echo ${test1[*]}
a b c d
[root@test1 opt]# echo ${test1[@]}
a b c d
[root@test1 opt]# test2[0]=1
[root@test1 opt]# test2[1]=2
[root@test1 opt]# test2[2]=3
[root@test1 opt]# echo ${test2[@]}
1 2 31.4.2、数组的长度
#数组的长度指的是:数组内包含了几个元素。
打印出数组的长度:
echo ${#数组名[*]} 例子:
echo ${#test[*]} ##打印数组内包含了几个元素
[root@test1 opt]# echo ${#test1[*]}
4
[root@test1 opt]# echo ${#test2[*]}
31.4.3、查看数组指定位置元素---开始为0
echo ${数组名[下标]}例子:
[root@test1 opt]# test3=(abc 123 456 789 dahanqi)
[root@test1 opt]# echo ${test3[0]}
abc
[root@test1 opt]# echo ${test3[2]}
456
[root@test1 opt]# echo ${test3[3]}
7891.4.4、数组遍历
[root@test1 opt]# vim shuzu.sh
#数组遍历
test=(1 2 3 4 5)
for num in ${test[*]}
do
echo -ne "$num\t"
done
[root@test1 opt]# sh shuzu.sh
1 2 3 4 5 1.4.5、数组的切片
echo ${数组名[*]:下标:打印长度}例子:
[root@test1 opt]# test5=(1 2 3 4 5)
[root@test1 opt]# echo ${test5[*]}
1 2 3 4 5
[root@test1 opt]# echo ${test5[*]:0:2}
1 2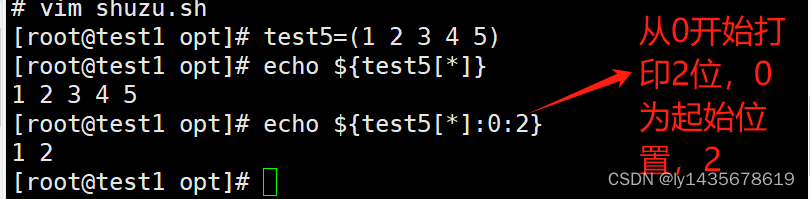

#0表示起始位置,2表示步长,起始位置θ开始,包括0,移2个。
[root@test1 opt]# echo ${test5[*]:1:3}
2 3 41.4.6、数组的替换
#临时替换
echo ${数组名[*]/下标/数值}例子:
[root@test1 opt]# echo ${test5[*]/4/99}
1 2 3 99 5 ##临时替换#永久修改
通过修改元素下标的值可以实现----赋值覆盖。
[root@test1 opt]# echo ${test5[*]}
1 2 3 4 5
[root@test1 opt]# echo ${test5[*]/4/99}
1 2 3 99 5 ##临时替换
[root@test1 opt]# echo ${test5[*]}
1 2 3 4 5
[root@test1 opt]# test5[3]=99 ##重新赋值覆盖替换
[root@test1 opt]# echo ${test5[*]}
1 2 3 99 51.4.7、删除数组
#删除整个数组
unset 数组名例子:
[root@test1 opt]# echo ${test1[*]}
a b c d
[root@test1 opt]# unset test1
[root@test1 opt]# echo ${test1[*]}
[root@test1 opt]# echo ${test1[*]}
[root@test1 opt]#1.4.8、删除元素
#删除数组当中的元素---通过单个下标删除
unset 数组名[下标]例子:
[root@test1 opt]# echo ${test5[*]}
1 2 3 99 5
[root@test1 opt]# unset test5[2]
[root@test1 opt]# echo ${test5[*]}
1 2 99 5
[root@test1 opt]# echo ${test5[3]}
99
[root@test1 opt]# echo ${test5[2]}1.4.9、数组追加,追加元素
数组名[下标]=数值根据下标追加
[root@test1 opt]# test5[4]=5
[root@test1 opt]# echo ${test5[*]}
1 2 3 99 5
[root@test1 opt]# test5[5]=6
[root@test1 opt]# echo ${test5[*]}
1 2 3 99 5 6在尾部追加
数组名+=(x y)例子:
[root@test1 opt]# test5+=(7 8)
[root@test1 opt]# echo ${test5[*]}
1 2 3 99 5 6 7 8#现在定义一个数组,元素都是整数,实现数组内整数的累加求和

test1=(10 20 30 40 50 60)
b=0
for ((i=0;i<6;i++))
do
a=`echo ${test1[i]}`
b=$(($a+$b))
done
echo $b
[root@test1 opt]# vim shuzu1.sh
[root@test1 opt]# sh shuzu1.sh
210
[root@test1 opt]# vim shuzu1.sh
test1=(10 43 45 47 50 60)
sum1=0
sum2=0
for i in ${test1[*]}
do
if [[ $i%2 -eq 0 ]]
then
sum1=$(($sum1+$i))
else
sum2=$(($sum2+$i))
fi
done
echo $sum1
echo $sum2
[root@test1 opt]# sh shuzu1.sh
120
135
root@test1 opt]# vim shuzu2.sh
test1=(3 5 8 4 56 34 76 53)
max=${test1[0]}
min=${test1[0]}
for i in ${test1[*]}
do
if [ $i -gt $max ]
then
max=$i ##取数组里面大于的话,赋值给max,小于等于不用管
fi
if [ $i -lt $min ]
then
min=$i ##取数组里面小于的话,赋值给min,大于等于不用管
fi
done
echo "$max"
echo "$min"
[root@test1 opt]# sh shuzu2.sh
76
31.5、冒泡排序

#冒泡排序:#类似气泡上涌的工作,会将数组当中的元素按照从小到大,或>者从大道小的顺序进行一个重新排列。test1=(20 10 60 40 50 30)
#从小到大排列。
#思路:对比两个相邻的元素,以从小到大为例。满足交换条件的元素,小的
往左移,大的往右移动。
#数组的位置发生变化(下标对应的元素的值发生变化)
#双层循环,外部循环控制排序的轮次。内循环比较两个元素的大小,决定>时候互换位置
#对比和交换的次数随着排序轮次而减少
[root@test1 opt]# vim shuzu3.sh
test1=(20 10 60 40 50 30)
length=${#test1[*]}
for ((b=1;b<length;b++))
do
for ((a=0;a<=length-b;a++))
do
c=${test1[$a]}
d=${test1[(($a+1))]}
if [ $c -gt $d ]
then
e=$c
test1[$a]=$d
test1[(($a+1))]=$c
fi
done
done
echo "${test1[*]}"
[root@test1 opt]# sh shuzu3.sh
10 20 30 40 50 60总结:取最大值,内循环,第一次循环需要,length-1次内循环,最大值在最后,a++后,b++,外循环第二次,这时候最大值已经在最后一位,那么内循环此时需要进行length-2次,依次类推
详见下:
[root@test1 opt]# bash -x shuzu3.sh
+ test1=(20 10 60 40 50 30)
+ length=6
+ (( b=1 ))
+ (( b<length ))
+ (( a=0 ))
+ (( a<length-b ))
+ c=20
+ d=10
+ [[ 20 -gt 10 ]]
+ e=20
+ test1[$a]=10
+ test1[(($a+1))]=20
+ (( a++ ))
+ (( a<length-b ))
+ c=20
+ d=60
+ [[ 20 -gt 60 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=60
+ d=40
+ [[ 60 -gt 40 ]]
+ e=60
+ test1[$a]=40
+ test1[(($a+1))]=60
+ (( a++ ))
+ (( a<length-b ))
+ c=60
+ d=50
+ [[ 60 -gt 50 ]]
+ e=60
+ test1[$a]=50
+ test1[(($a+1))]=60
+ (( a++ ))
+ (( a<length-b ))
+ c=60
+ d=30
+ [[ 60 -gt 30 ]]
+ e=60
+ test1[$a]=30
+ test1[(($a+1))]=60
+ (( a++ ))
+ (( a<length-b ))
+ (( b++ ))
+ (( b<length ))
+ (( a=0 ))
+ (( a<length-b ))
+ c=10
+ d=20
+ [[ 10 -gt 20 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=20
+ d=40
+ [[ 20 -gt 40 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=40
+ d=50
+ [[ 40 -gt 50 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=50
+ d=30
+ [[ 50 -gt 30 ]]
+ e=50
+ test1[$a]=30
+ test1[(($a+1))]=50
+ (( a++ ))
+ (( a<length-b ))
+ (( b++ ))
+ (( b<length ))
+ (( a=0 ))
+ (( a<length-b ))
+ c=10
+ d=20
+ [[ 10 -gt 20 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=20
+ d=40
+ [[ 20 -gt 40 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=40
+ d=30
+ [[ 40 -gt 30 ]]
+ e=40
+ test1[$a]=30
+ test1[(($a+1))]=40
+ (( a++ ))
+ (( a<length-b ))
+ (( b++ ))
+ (( b<length ))
+ (( a=0 ))
+ (( a<length-b ))
+ c=10
+ d=20
+ [[ 10 -gt 20 ]]
+ (( a++ ))
+ (( a<length-b ))
+ c=20
+ d=30
+ [[ 20 -gt 30 ]]
+ (( a++ ))
+ (( a<length-b ))
+ (( b++ ))
+ (( b<length ))
+ (( a=0 ))
+ (( a<length-b ))
+ c=10
+ d=20
+ [[ 10 -gt 20 ]]
+ (( a++ ))
+ (( a<length-b ))
+ (( b++ ))
+ (( b<length ))
+ echo '10 20 30 40 50 60'
10 20 30 40 50 60二、正则表达式
正则表达式:匹配的是文本内容,linux的文本三剑客都是针对文本内容。
grep 过滤文本内容
sed 针对文本内容进行增删改查
awk 按行取列
文本三剑客----都是按照行进行匹配。
2.1、grep筛选:
grep的作用就是使用正则表达式来匹配文本内容。
选项:
-m 数字 匹配几次之后停止
[root@test1 opt]# grep -m 1 root /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@test1 opt]# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin-v 取反
grep -v root /etc/passwd ##除了root,筛选所有-n 显示匹配的内容及行号
[root@test1 opt]# grep -n root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
10:operator:x:11:0:operator:/root:/sbin/nologin-c 只统计匹配的行数
[root@test1 opt]# grep -c root /etc/passwd
2-o 仅显示匹配的结果
[root@test1 opt]# grep -o root /etc/passwd
root
root
root
root-q 静默模式。不输出任何信息。
[root@test1 opt]# grep -q root /etc/passwd > /opt/123.txt
[root@test1 opt]# cat /opt/123.txt
[root@test1 opt]# grep -m 1 root /etc/passwd > /opt/123.txt
[root@test1 opt]# cat /opt/123.txt
root:x:0:0:root:/root:/bin/bash-A after 数字,后几行
grep -A 3 root /etc/passwd-B before 数字 ,前几行
grep -B 3 root /etc/passwd-C 数字,前后各几行
grep -C 3 root /etc/passwd-e 或者
grep -e root -e xy102 /etc/passwd-E 匹配扩展正则表达式
-f 匹配两个文件相同的内容,以第一个文件为准
[root@test1 opt]# vim kl1.txt
abc
acv
abf123
234
456
aaa
bbb
ccc
abc
acv
abf123
234
456
aaa
bbb
ccc
abc
acv
abf
[root@test1 opt]# vim kl1.txt
123
345
qqq
aaa
abf
avg
afh
[root@test1 opt]# grep -f kl.txt kl1.txt
123
aaa
abf-r 递归目录 目录下的文件内容,软连接不包含在内。
[root@test1 opt]# grep -r 123 /opt/
/opt/test41.sh: echo 123 | passwd --stdin $user
/opt/test41.sh: echo 123 | passwd --stdin $user
匹配到二进制文件 /opt/.123.swp-R 递归目录 目录下的文件内容,软连接包含在内。
[root@test1 opt]# grep -R abf /opt/
/opt/nginx-1.22.0/src/core/ngx_crc32.c: 0xedb88320, 0x9abfb3b6, 0x03b6e20c, 0x74b1d29a,
/opt/999.txt:abf1232.2、sort排序:
sort
以行为单位,对文件的内容进行排序
sort 选项 参数
[root@test1 opt]# sort 123.txt
111
112
123
222
333
555
aaa
aaa
aaa
bbb
bbb
cc
ddd
DDD
EEE
nnncat file | sort 选项
-f 忽略大小写,默认会把大写字母排在前面
[root@test1 opt]# sort -f 123.txt
111
112
123
222
333
555
aaa
aaa
aaa
bbb
bbb
cc
DDD
ddd
EEE
nnn-b 忽略每行之前的空格(不是把空格删除,只是按照数字和字母的顺序排列)
[root@test1 opt]# sort -b 123.txt
123
345
345
345
567
987
aaa
bbb
bbb
BD
bfvf
SD
sdfd
sds-n 按照数字进行排序
[root@test1 opt]# sort -n 123.txt
aaa
bbb
bbb
BD
bfvf
SD
sdfd
sds
123
345
345
345
567
987-r 反向排序
[root@test1 opt]# sort -r 123.txt
sds
sdfd
SD
bfvf
BD
bbb
bbb
aaa
987
567
345
345
345
123-u 相同的数据只显示一行
[root@test1 opt]# sort -u 123.txt
123
345
345
567
987
aaa
bbb
BD
bfvf
SD
sdfd
sds-o 把排序后结果转存到指定的文件
[root@test1 opt]# sort -u 123.txt
123
345
345
567
987
aaa
bbb
BD
bfvf
SD
sdfd
sds
[root@test1 opt]# cat 123.txt | sort -rno 234.txt
[root@test1 opt]# cat 234.txt
987
567
345
345
345
123
sds
sdfd
SD
bfvf
BD
bbb
bbb
aaa2.3、uniq 去重
uniq 去除连续重复的行,只显示一行
-c 统计连续行的次数,合并连续重复的行
[root@test1 opt]# uniq -c 123.txt
1 345
1 567
1 987
1 123
2 345
1 bbb
1 bfvf
2
1 sdfd
1 SD
1 BD
2
1
1 sds
2 aaa
1 bbb-u 显示仅出现一次的行(包括不适合连续出现的重复行)
[root@test1 opt]# uniq -u 123.txt
345
567
987
123
bbb
bfvf
sdfd
SD
BD
sds
bbb-d 仅显示连续重复的行(不包括非连续出现的内容)
[root@test1 opt]# uniq -d 123.txt ##显示重复的行
345
aaa作业
[root@test1 ~]# df -h | awk 'NR>1 {print $5}' | tr -d '%'
15
0
0
1
0
100
18
1
0
1#按照从大到小排列
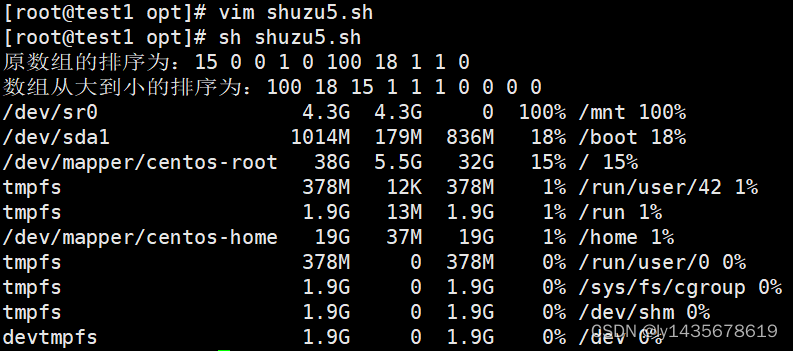
#附加题从小到大,整行排序
test1=($(df -h | awk 'NR>1 {print $5}' | tr -d '%'))
echo "原数组的排序为:${test1[*]}"
length=${#test1[*]}
for ((j=1;j<$length;j++))
do
for ((k=0;k<$length-j;k++))
do
a=${test1[$k]}
b=${test1[$(($k+1))]}
if [ $a -lt $b ]
then
c=$b
test1[$k]=$c
test1[$(($k+1))]=$a
fi
done
done
echo "数组从大到小的排序为:${test1[*]}"
df -h | awk 'NR>1 {print $0, $5}' | sort -k5 -nr