1. 数据库基础知识:
DDL、DML、DQL、DCL的概念与区别?
- DDL(数据定义语言):创建(CREATE)数据库中的各种对象:表、视图、索引等
- DML(数据操纵语言):INSERT、UPDATE、DELETE
- DQL(数据查询语言):SELECT、FROM、WHERE
- DCL(数据控制语言):来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:GRANT(授权)
三大范式:*
- 第一范式(1NF):所有属性都是不可分割的原子值
- 第二范式(2NF):2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖
- 第三范式(3NF):3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖
https://www.zhihu.com/question/24696366
数据库相关语法:
创建数据库: Create Database db_name; # 删除数据库: Drop Database db_name; # 选择数据库: Use db_name; # 显示所有数据库: Show Databases;
建表语句相关语法:
# 创建数据库:
Create Database db_name;
# 删除数据库:
Drop Database db_name;
# 选择数据库:
Use db_name;
# 显示所有数据库:
Show Databases;表数据相关语法:
# 创建表:
Create Table table_name (column_name column_type);
# 删除表:Drop【抓铺】
Drop Table table_name;
# 修改表:
## 添加某列:Alter【奥特儿】
Alter Table table_name Add column_name data_type;
## 删除某列:
Alter Table table_name Drop column_name;
## 修改表名:
Alter Table old_table_name Rename new_table_name;
## 修改表列名:
Alter Table table_name Change old_column_name new_table_name data_type;
## 修改表属性:
Alter Table table_name Modify column_name new_data_type;
# 显示表:
Show tables;2. MySQL基础知识:
Select子句及其执行顺序:
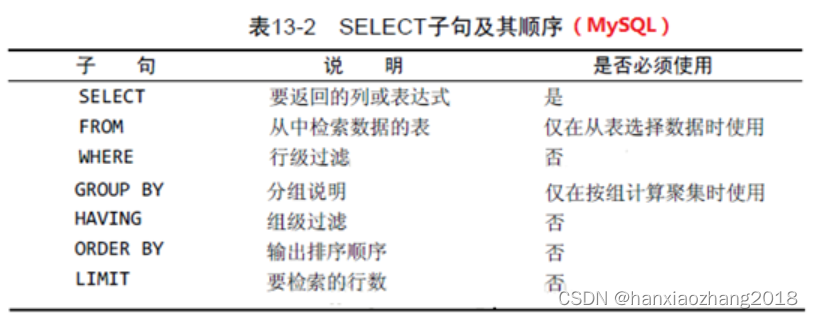
注:使用GROUP BY子句以后,才可以用HAVING。
MySQL单表最大容量:
使用不同的操作系统、数据库的存储引擎以及存储方式都会改变表的容量(InnoDB最大64TB,MyISAM 最大64PB,1PB=2014TB),一般来说MySQL单表是一个千万级的数据库。
MySQL存储超大文件的数据类型:
tinytext(256B)、text(64K)、mediumtex(16M)、longtext(4G)
MySQL怎么进行数据恢复?
第一步,找到最近的一次全量备份,从这个备份恢复到临时库。
第二步,从备份的时间点开始,将备份的binlog依次取出来,重放到中午误删表之前的那个时刻。
Tips:binlog会记录所有的逻辑操作,并且是采用追加写的形式。
left join语句on与where的区别?
在left join语句中,左表(主表)过滤必须放where条件中,右表过滤必须放on条件中
WHERE和HAVING的区别?
- WHERE过滤的是行,HAVING过滤分组(HAVING与GROUP BY联合使用,用来过滤由GROUP BY返回的记录集);
- WHERE在分组前对数据进行过滤,HAVING在分组后对数据进行过滤;
- WHERE后不能接聚合函数,HAVING后面通常都有聚合函数。
MySQL原子性和持久性是怎么保证的?
原子性通过undo log来实现,持久性通过redo log来实现。
3. MySQL中SQL的执行过程:
MYSQL架构分为server层(连接器,查询缓存,分析器,优化器,执行器等)和存储引擎层(负责数据的存储与提取)
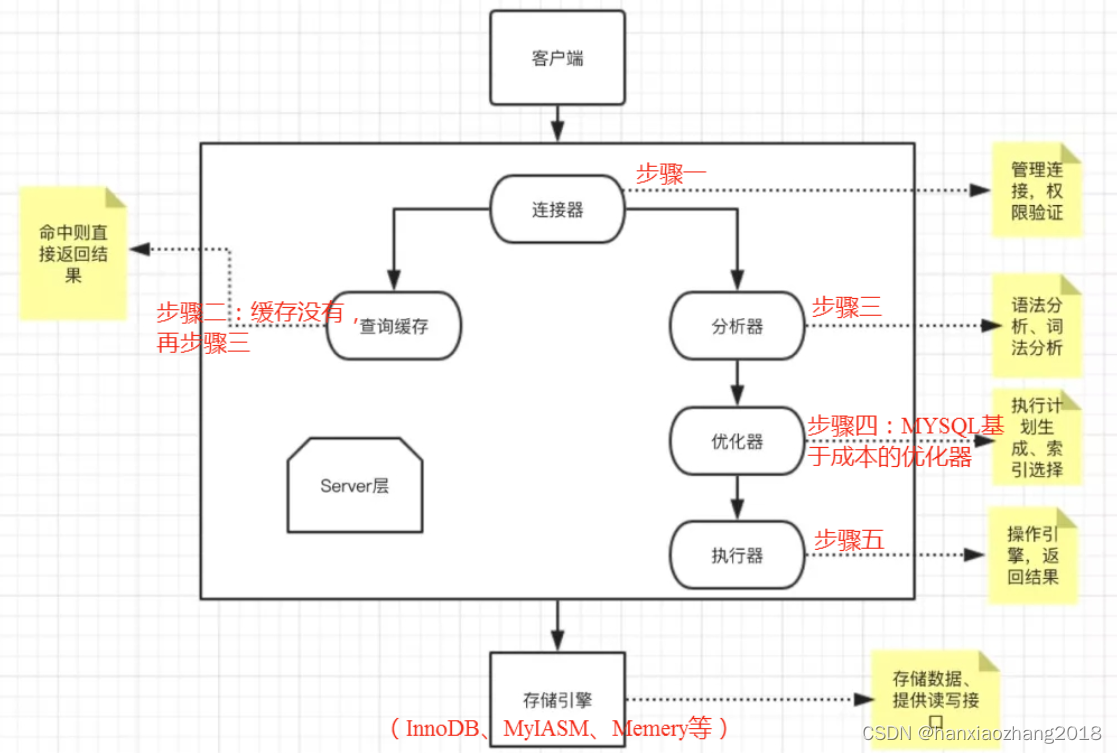

Mysql------Sql查询语句的执行过程_mysql sql语句执行过程-CSDN博客
Tips:需要注意的是,MySQL 8.0版本直接将查询缓存的功能删掉了,因此8.0开始没有这个功能。
(上边的图很全面,理解记下来)
下图建议,看完undo log、redo log 、binlog之后再看。

fsync函数(内存指令):同步内存中所有已修改的文件数据到储存设备。
4. MySQL中in和exists区别?**
- 连表查询原则:
- 在MYSQL的连表查询中,最好是遵循"小表驱动大表的原则"
- 区别:
- in语句是把外表和内表作哈希关联,而exists语句是对外表(主表)作嵌套循环,每次循环再对内表进行查询。
- 如果两个表中一个较小,一个是较大,则子查询表大的用exists,子查询表小的用in。
- 无论哪个表大,用not exists都比not in要快。
- Tips:
- 哈希连接(Hash Join):先扫面一张表,将表中的Key进行哈希,根据哈希结果装进不同的"桶"中,然后再扫描另外一个表,将表中的Key进行哈希。对应之前的"桶"进行查找匹配。
- 嵌套循环(loop):先扫描一个驱动表,然后再拿着扫描出来的记录一条一条去另外一个表中去查找匹配。
5. 存储过程与自定义函数的区别?
- 存储过程:一组为了完成特定功能的SQL语句集,经编译后存储在数据库中(而SQL语句需要先编译然后执行),用户通过指定存储过程的名字和给定参数来调用执行它。
- 区别:(@&@)
- 存储过程实现的功能要更复杂一些;自定义函数的针对性更强;
- 存储过程可以返回多个值;自定义函数只能有一个值;
- 存储过程一般独立执行;自定义函数可以作为其他SQL语句的组成部分来实现的。
6. 存储过程与触发器的区别?
触发器是一种特殊类型的存储过程。触发器是通过事件触发被执行的,而存储过程是通过存储过程名字调用执行的。
7. 事务ACID实现原理:***
- 原子性:undo log(可以拓展讲MVCC)。
- 一致性:通过原子性、隔离性、持久性三者来保证实现(最核心最本质的要求)。
- 隔离性:锁、 MVCC -> undo log +ReadView 。
- 持久性:redo log。
8. MVCC(多本版并发控制):****
- 作用:提高数据库并发性能,处理写冲突,即使有读写冲突时,也能做到不加锁,非阻塞并发读。
- 相关概念:当前读(最新版的数据;操作:select lock in share mode (共享锁)、select for update、 update、insert、delete)、快照读(不加锁select操作;它实现了MVCC的非阻塞读功能)。
- 实现原理:
- 三个隐藏字段:DB_ROW_ID(隐藏主键)、DB_TRX_ID(事务id)、DB_ROLL_PTR(回滚指针)
- undo log(回滚日志):进行insert、delete、update操作时会产生undo log;它是一个记录链,链首就是最新的旧记录,链尾就是最早的旧记录。
- Read View(读视图):事务进行快照读操作时,生产的读视图;读视图生成时机不同,会产生不同的事务隔离级别;读视图根据可见性规则,去undo log链中寻找需要的数据。
RC、RR隔离级别下,InnoDB快照读有什么不同:
- 在RC隔离级别下,事务每次快照读都会生成一个新的Read View。
- 在RR隔离级别下,在同一个事务中,第一个快照读才会创建Read View,之后的快照读获取的都是同一个Read View。
9. 描述一下数据库事务隔离级别?
相关术语:
- 脏读(无效数据的读出):事务A修改某值,然后事务B读取该值,此后事务A撤销该值的修改,导致事务B读取的数据无效。
- 不可重复读:是指在一个事务范围内多次查询却返回了不同的数据值,这是由于在查询期间,被其它事务修改并提交了。
- 虚读(幻读):是事务非独立执行时发生的一种现象。事务A按照一定条件进行数据读取,期间事务B插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B新插入的数据称之为幻读。(@&@)
- Tips:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除,幻读是不可重复的子类。(@&@)
隔离级别:

Tips:事务隔离级别不是得越高越好,如果级别越高,要加锁来保证事务的正确性,会导致效率降低,因此,实际开发中要在效率和并发正确性之间做一个取舍。
原理:
事务隔离机制的实现基于锁机制和并发调度(MVCC),通过保存修改的旧版本信息,来支持并发一致性读和回滚等特性。
10. MySQL幻读怎么解决的:
概念:
事务A按照一定条件进行数据读取,期间事务B插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B新插入的数据称之为幻读。

解决:
- 一般情况下select * from ... .where ...是快照读,不会加锁;而 for update、lock in share mode、update、delete都属于当前读,会加锁。
- 事务中都是用快照读,那么不会产生幻读的问题,但是快照读和当前读一起使用的时候就会产生幻读。
- 事务在查询中使用select ... for update 加锁避免幻读,其实本质是采用间隙锁的机制解决幻读问题。
11. undo log、redo log、binlog:
undo log :
回滚和MVCC 、redo log和binlog -> 减少IO成本、保证数据一致性、两阶段提交
redo log:(@&@)
- 概念:
- 它是InnoDB存储引擎层的日志(又称重做日志文件)。它是循环写的,它不是记录数据页更新之后的状态,而是记录这个页做了什么改动。
- 它是固定大小:比如可以配置为一组4个文件,每个文件的大小是1GB,那么日志总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写。
- 在数据库进行异常重启的时候,可以根据redo log进行恢复,也就达到了 crash-safe。

- 好处:
- redo log 节省随机写磁盘的IO,转换成顺序写 -> InnoDB会先把记录写到redo log里面,并更新内存,这个时就算更新完成。 写redo log是顺序写入,刷脏是随机写,这样可以将随机写磁盘的IO消耗转成顺序写。
- 日志和磁盘配合的整个过程,就是MySQL 里的 WAL(Write-Ahead Logging)技术 ,它的关键点就是先写日志,再写磁盘。
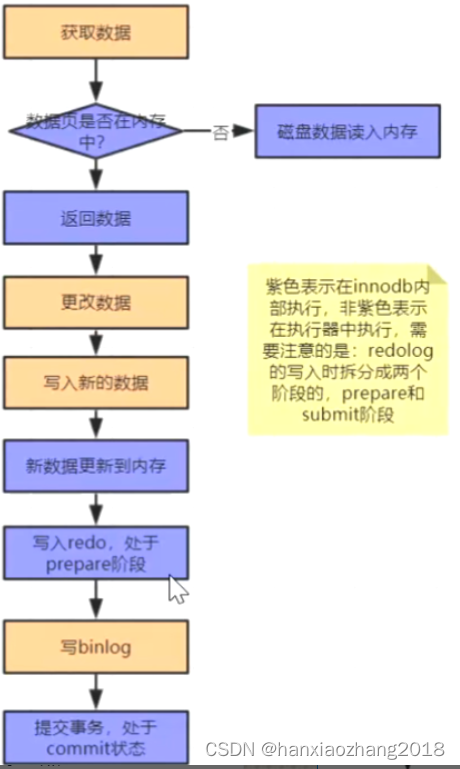
- 流程:**
- 当有一条记录需要更新时,InnoDB就会先把记录写到 redo log(redolog buffer)里面,并更新内存(buffer pool),这个时候更新就算完成了。InnoDB 引擎会在适当时(如系统空闲时),将这个操作记录更新到磁盘里面(刷脏页)。
- Crash-Safe:
- 它指MySQL服务器宕机重启后,能够保证:
- 所有已经提交的事务的数据仍然存在。
- 所有没有提交的事务的数据自动回滚。
- 它指MySQL服务器宕机重启后,能够保证:
binlog(归档日志):
- 概念:
- binlog 属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑,binlog没有crash-safe能力。
- sync_binlog参数设置成1时,表示每次binlog都持久化到磁盘。建议设置成1,这样可以保证MySQL异常重启之后binlog不丢失。
- binlog 有两种模式:statement格式的话是记SQL语句,row格式会记录行的内容。它是记两条,更新前和更新后都有。
- binlog 属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑,binlog没有crash-safe能力。
- 作用:数据恢复、主从复制。
MySQL的两阶段提交(2PC):
将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是MySQL的两阶段提交,它主要解决 binlog和redo log 的数据一致性的问题。 -> 大概步骤:写入redo log,此时处于prepare节点,然后写入binlog成功后,提交redo log。
redo log和binlog区别:*
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是在某个数据页上做了什么修改;binlog 是逻辑日志,记录的是这个语句的原始逻辑。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。追加写是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
redo log和binlog是怎么关联起来的?
- redo log和 binlog有一个共同的数据字段,叫XID。
- 崩溃恢复时,会按顺序扫描 redo log:
- 如果碰到既有prepare、又有commit 的redo log,就直接提交;
- 如果碰到只有parepare、而没有commit 的redo log,就拿着XID去 binlog 找对应的事务,然后根据事务去判断。
MySQL 怎么知道binlog是完整的?
一个事务的 binlog 是有完整格式的:
- statement格式的binlog,最后会有COMMIT。
- row 格式的binlog,最后会有一个XID event。
- 在 MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。
MySQL中已经有了Binlog,为啥还要有Redo Log?
https://blog.csdn.net/qq_41638851/article/details/135156062
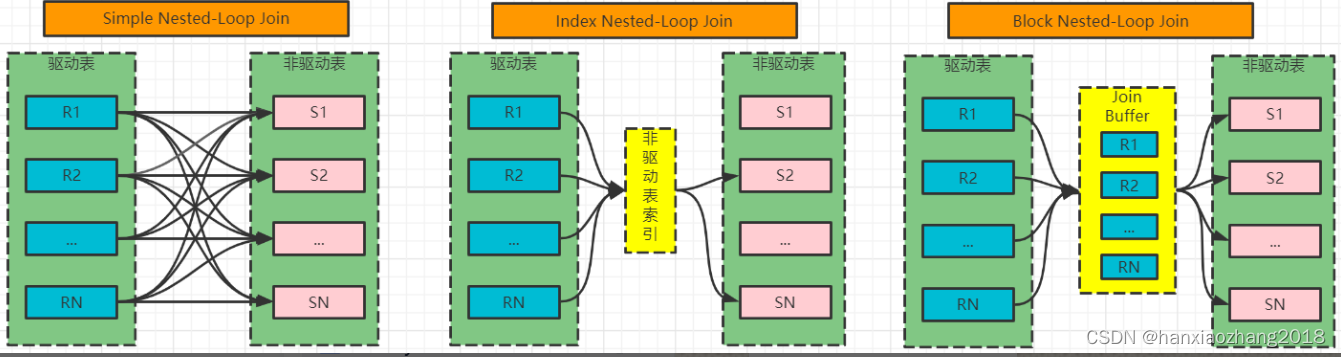
12. SQL Join原理?***
MySQL只支持一种Join算法,它是Nested-Loop Join(嵌套循环连接),并不支持哈希连接和合并连接,不过在MySQL中包含了多种变种,能够帮助MySQL提高Join执行的效率。
Simple Nested-Loop Join(简单嵌套循环连接):
- 从驱动表中取出R1匹配S表所有列,然后R2,R3 ... 直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行RN次访问,虽然简单,但是相对开销太大。
Index Nested-Loop Join(索引嵌套循环连接):
- 非驱动表上有索引,比较的时,不需要一条条记录进行比较,可以通过索引减少比较,从而加速查询。(即工作中关联键一定要建立索引的原因)
- 这种算法在连接查询的时,驱动表会根据关联字段的索引进行查找,只有在索引上找到符合的值,才会回表进行查询。
- 驱动表的选择:MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时,也会出现错误选择。
- 如果非驱动表的关联键是主键,性能就会非常的高,如果不是主键话,关联起来如果返回多行数据,效率就会特别的低,因为要多次的回表操作。
Block Nested-Loop Join:
- 在有索引的情况下,MySQL尝试使用Index Nested-Loop Join,在没有索引的情况下,MySQL会优先使用Block Nested-Loop Join,其次使用simple Nested-Loop Join。
- Block 比Simple 多一个中间处理的过程:Join Buffer。
- 使用Join Buffer将驱动表的查询Join相关列都给缓冲到了Join Buffer中,然后批量与非驱动表进行比较,降低非驱动表的访问频率。
- 在查找的时,MySQL会将所有的需要的列缓存到Join Buffer中,包括select的列,而不是仅只缓存关联列。在一个有N个JOIN关联的SQL中,在执行时候分配N-1个Join Buffer。
- 参数join_buffer_size可以设置join buffer的大小,默认情况下join_buffer_size=256K。
13. 说明一下数据库索引原理、底层索引数据结构,叶子节点存储的是什么,索引失效的情况?
索引概念:
对数据库表中一个或多个列的值进行排序的数据结构。索引是一个文件,它是要占据物理空间的。
索引优缺点:
- 优点:加快检索速度;加速表和表之间的连接;创建唯一性索引,保证表中每一行数据的唯一性。
- 缺点:占用物理存储空间;创建索引和维护索引花费时间。
索引类型:*
聚集索引与非聚集索引(又称辅助索引)
使用场景:***
- 使用场景:
- where后面的列;
- 主键和外键的列;
- 经常需要排序、分组和联合操作的字段。
- 不适应场景:-> 关键字"少",查询少、数量少;关键字"不使用",关键字"频繁更新"
- 查询中很少使用的字段;
- 数据量太少的字段;
- 唯一性不太差的字段;
- 更新频繁的字段;
- 不会出现在where后的字段;
- 大字段(text和blob等)不适合建立索引。
索引失效的情况:***
- 组合索引不遵循最左匹配原则时,索引失效;
- 组合索引前面索引列使用范围查询(、ike),会导致后续的索引失效;
- like语句中,以%开头的模糊查询;
- 不要在索引列上做任何操作(计算,函数,类型转换),否则索引失效;
- is null和is not null无法使用索引;
- 字符串不添加引号会导致索引失效;
- 两表关联使用的条件字段中字段的长度、编码不一致会导致索引失效;
- 尽量少使用or操作符,否则连接时索引会失效;
- 如果mysql中使用全表扫描比使用索引快,也会导致索引失效。
如何加快数据访问的原理:***
- 解决方向1:MySQL所有数据都是存在磁盘中,需要减少IO成本 -> 读取的次数少、量少 -> 采用分块读取(局部性原理、磁盘预读)
- 解决方向2:使用索引 -> 索引的数据结构的选择 -> B+树。
- MySQL的索引数据结构有:Hash(仅Memory引擎支持)、B+树。Hash比B+树效率高,但是限制条件多,所以大部分使用B+树。
- InnoDB默认读取16K的数据,是页的正数倍。
- 二叉树、AVL、红黑树特点是树的分支只有两个,数据多时,树的深度深,导致查询次数多(Pass)。
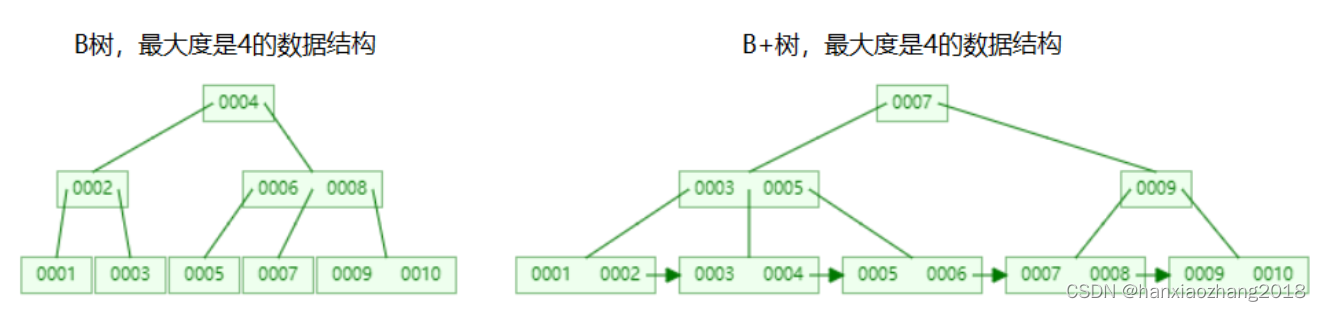
- B树与B+树是多叉有序树,可以降低树的深度;
- B树的每个节点都是存放key、value完整数据,会大量浪费内存。
- 在B+树时,只有叶子节点存放key、value完整数据,非叶子节点只存放key。并且B+叶子节点会包含所有的数据,数据是按照顺序排列的。
其他重要概念:
前导列:就是在创建复合索引语句的第一列或者连续的多列。例如,复合索引(x,y,z)的前导列:x,xy,xyz
具体原理:
《11.5数据库连接池druidhikariCP及索引1_.vep》
《11.6索引原理2mysql基本架构及日志实现1_.vep》
放弃了,有时间看
14. 描述一下聚簇索引和非聚簇索引的区别?
聚簇索引存储引擎有要求:InnoDB中既有聚簇索引也有非聚簇索引,而MyISAM中只有非聚簇索引。
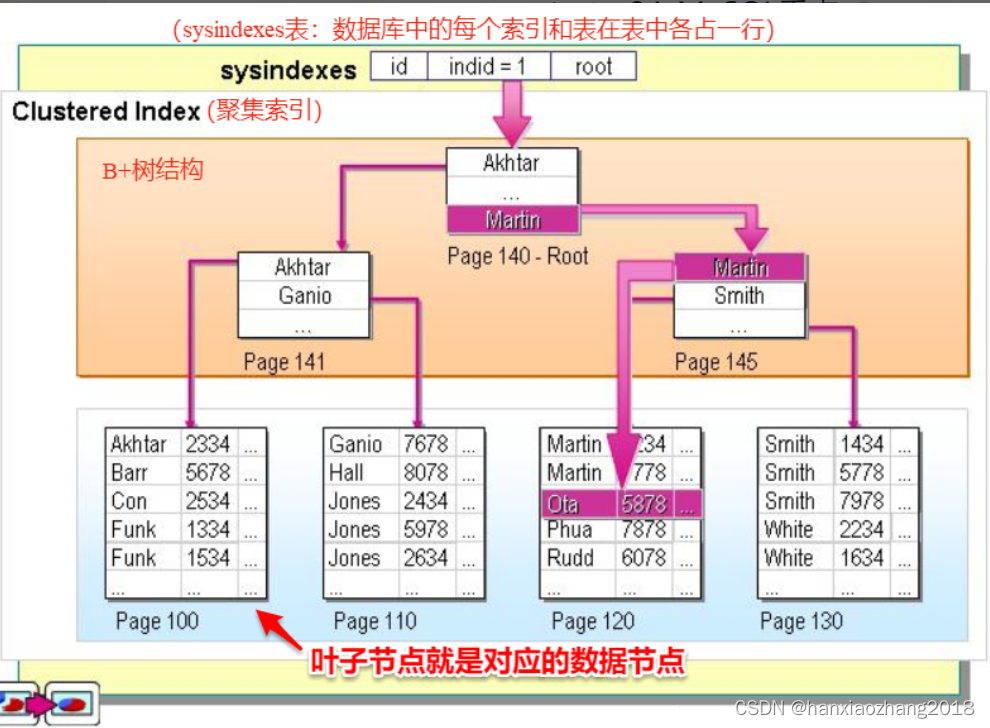
聚集索引(新华字典的拼音字典):
- 概念:
- 索引的逻辑顺序与磁盘上行的物理存储顺序相同。换一种说法是数据跟索引绑定到一起的叫聚集索引。
- 特点:
- 一个表中只能拥有一个聚集索引。索引列,默认是主键,如果没有主键,会选择唯一键,如果没有唯一键,会选择生成6字节的rowid(隐藏字段)。
- 叶子节点就是对应的数据节点,不需要二次查询,查询速度占优势。
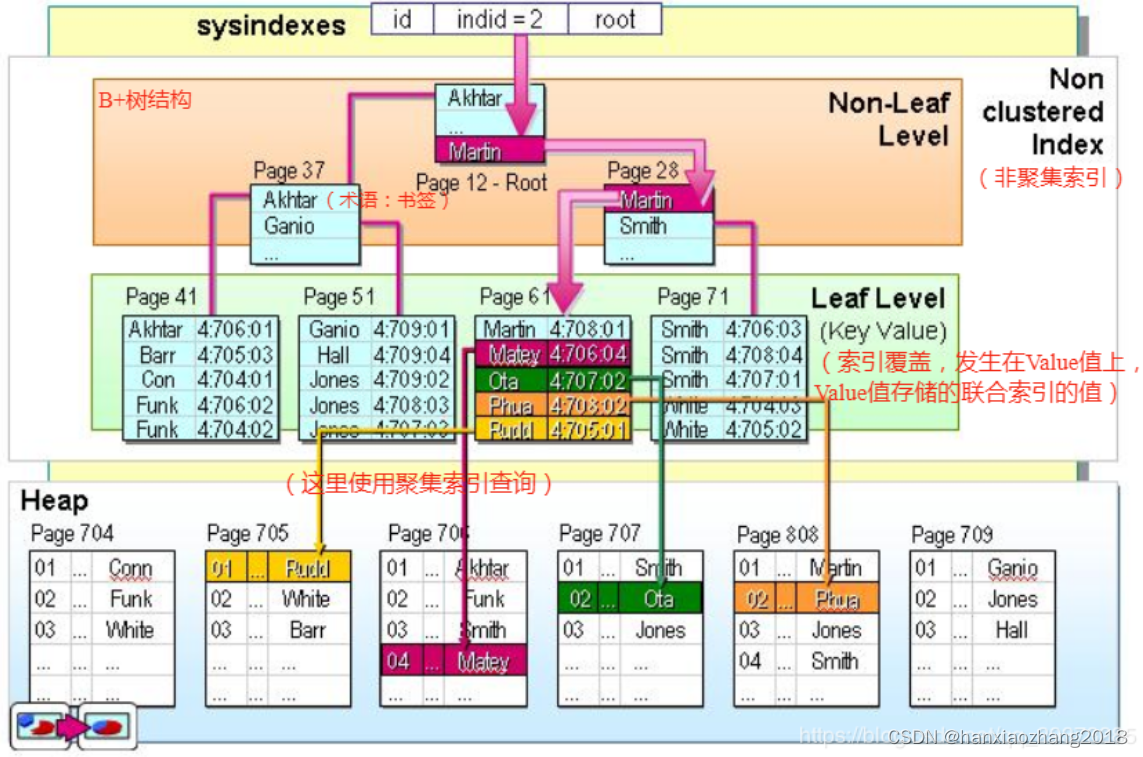
非聚集索引(新华字典的偏旁字典):
- 概念:
- 索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 特点:
- 一个表中可以拥有多个非聚集索引。
- 叶子节点仍然是索引节点(叶子节点存储聚集索引的key),它只是有一个指针指向对应的数据块(指针到物理数据使用聚集索引查询)。查询中包含该索引没有覆盖的列,需要第二次的查询。
- 分类:
- 普通索引(Normal):基本的索引类型,没有任何限制(允许有空值)。
- 唯一索引(Unique):索引列的值唯一,但允许有空值。如果是组合索引,组合列的值要唯一。
- 全文索引(Full Text):主要针对文本的内容进行分词,加快查询速度
15. MySQL如何做分库分表的?
分库分表的依据 -> 单表的数据量经验:
300W:可以轻松抗住;600W:数据开始卡,优化可以解决(表结构,索引设计);800W~ 1000W:优化都会遇到瓶颈。
一般单表1000W以内不考虑分表。但实际需要预估系统半年到一年的业务增长量,也要避免过度设计。
分库分表步骤:
根据数据量增长速度,依次实现:不分库不分表 -> 同库内的分表 -> 分库分表。
Tips:不要过度设计,MVP原则(最小设计原则)
分库分表策略:
- 水平:按照数据的范围切分数据,减少查询数据量。
- 划分规则:
- 范围划分:从0到10000一个表,10001到20000一个表;
- HASH取模:通过某个ID值 hash取模后,分配到不同的数据库上。
- 地理区域:华东,华南,华北这样来区分业务。
- 时间切分:冷热数据分离,一年前的数据放到一张表里去,现在数据放到一张表。
- 划分规则:
- 垂直:按照数据字段切分数据,把数据分为常用数据与不常用数据。减少返回数据量。
分库分表遵循原则:**
- 能不切分尽量不要切分(一般千万级别数据去切分);
- 如果要切分一定要选择合适的切分规则,提前规划好;
- 数据切分尽量通过数据冗余或表分组来降低跨库Join的可能;
- 业务读取尽量少使用多表Join。
分库分表面临的问题:*
- 事务支持:分布式事务。
- 跨库Join:分两次查询,第一次查询的结果返回关联数据的ID,然后根据ID第二次查询得到关联数据。
- 全局主键:无中心化分布式主键(UUID、雪花等),参考分布式ID。
中间件:
使用Mycat或者ShardingSphere丝菲尔儿(Sharding-JDBC)中间件做分库分表,选择合适的中间件。
小型项目,分片规则简单的项目用 Sharding-JDBC;大型项目,可以用Mycat。
Sharding-JDBC:
Sharding-JDBC是一个在客户端的分库分表工具。它是一个轻量级Java框架,在Java的JDBC层提供的额外服务。
具体使用:
- 对app_user和app_user_record进行了库内分表,并且它两是绑定表关系。
- 使用自定义分片策略,继承PreciseShardingAlgorithm类。
- 使用自定义主键生成策略,利用Redis自增生成id,这里还用的Java SPI 加载自定义类。
- 使用dynamic-datasource-spring-boot-starter配置多数据源,不分表的数据使用非分表数据源。