增加了redis分布式锁,但是还是生成了重复数据


原因
两个线程
第一个线程先获取锁,然后进行新增,此时第二个线程也进入方法体,尝试获取锁,结果没获取到,继续在5s内尝试,在redis获取锁等待5s的过程中,例如第2s,此时 第一个线程保存结束,释放了锁,但是此时数据还没有保存到数据库中,导致第二个线程获取到锁后,根据code查询数据库并没有查询到数据,也进行了一次保存操作,最终导致生成了两个code相同的数据
解决思路
由于是code重复,分析为什么两个线程生成了同一个code
检查发现生成code的代码逻辑是,通过的查询表中数据量例如有1000条,则code为HY然后➕1,这里就有问题,可以模拟下cas 自旋锁原理 这里是伪代码
思路1
原逻辑
1.查询总条数 例如1000
2.生成客户编码1000+1 code设置为 HY1001
3.保存客户
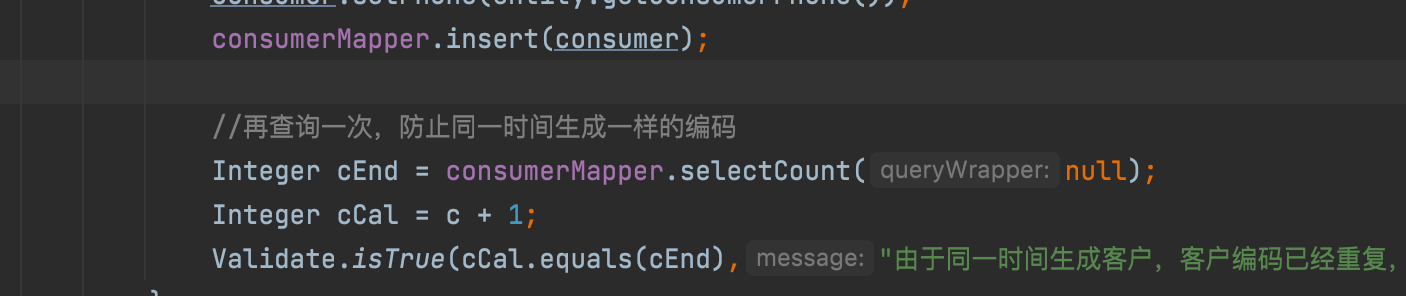
修改后逻辑
1.查询总条数 例如1000
2.生成客户编码1000+1 code设置为 HY1001
3.保存客户
4.再次查询总条数 判断总条数是否为1001,如果不等于1001 则提示报错
思路2
其实也可以改用redis的自增命令
看具体业务自行选择
修改点2
保存时获取redis锁不用tryLock,直接用lock ,或者tryLock的时间修改为1毫秒或者微秒
java
boolean locked = false;
try{
locked = redisMutexService.tryLock(redisKey, TimeUnit.MICROSECONDS, 1);t r ylock
先尝试立即获取锁,没获取到则在指定时间内尝试重新获取,超过等待时间则返回false