内容将会持续更新,有错误的地方欢迎指正,谢谢!
python之Bible快速检索器
|-----------------------------------------------------|
| TechX 坚持将创新的科技带给世界! 拥有更好的学习体验 ------ 不断努力,不断进步,不断探索 |
|------------------------------------------------------------|
| TechX ------ 心探索、心进取! 助力快速掌握 python 开发 为初学者节省宝贵的学习时间,避免困惑! |
前言:
最近在看shengjing的时候突发奇想,能不能开发一款可以快速查询shengjing的软件,通过输入书名章:节这样的方式来快速查询,于是就开发了这款能够可以快速查询的软件。
TechX 教程效果:
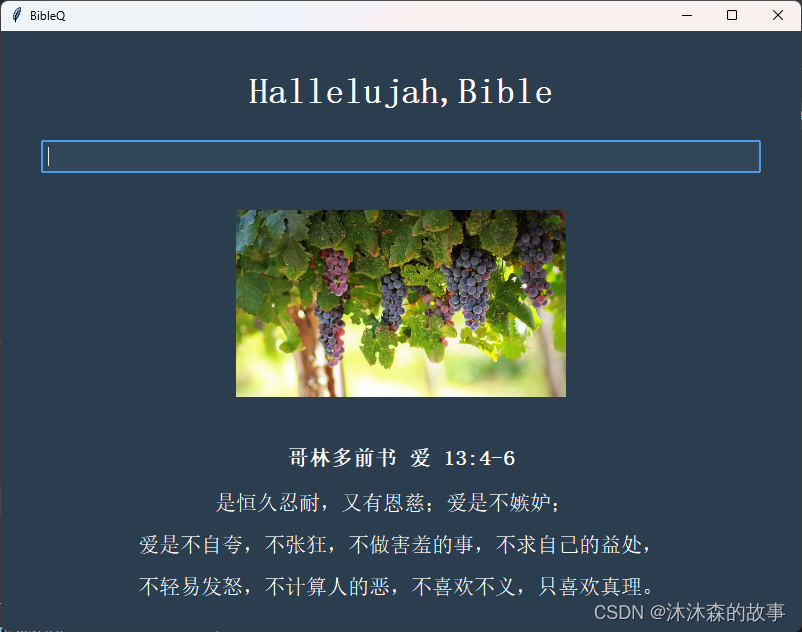
文章目录
一、准备
在做这个软件的时候,首先考虑到要采用什么方式来获取shengjing,当时想了3种获取方式:API、爬虫和本地化文件
首先考虑使用API,就去网上找到了一个相关API,但是发现这个API不支持中文,找到的其他的API很多都不能用,而且不稳定,所以就放弃了这种方式。
后面考虑使用爬虫来爬取,找到一个shengjing的网站,但是只是个国外的网站,可能比较慢,国内可能访问不了,也就放弃了。
然后考虑使用本地化文件,看是否能下载shengjing的Json或者XML文件,于是我在github上查找,找到了xml格式的shengjing。
1、文件准备
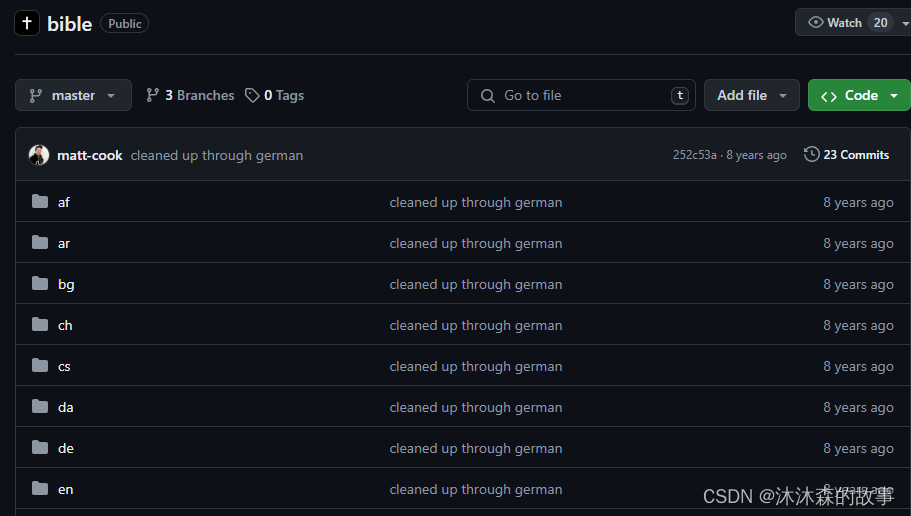
xml格式的shengjing可以自行去下载,地址https://github.com/gratis-bible/bible。
里面包含了各种语言的版本,我这里使用中文版,下载解压后找到zh/cvs.xml文件
2、工程准备
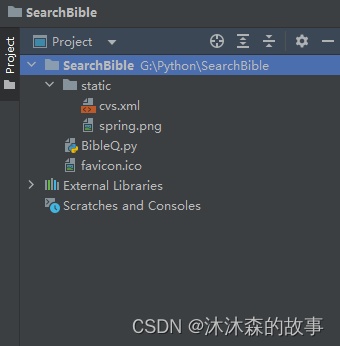
新建一个python工程,目录与下面保持一致,将cvs.xml放在static文件夹中
二、加载本地cvs.xml
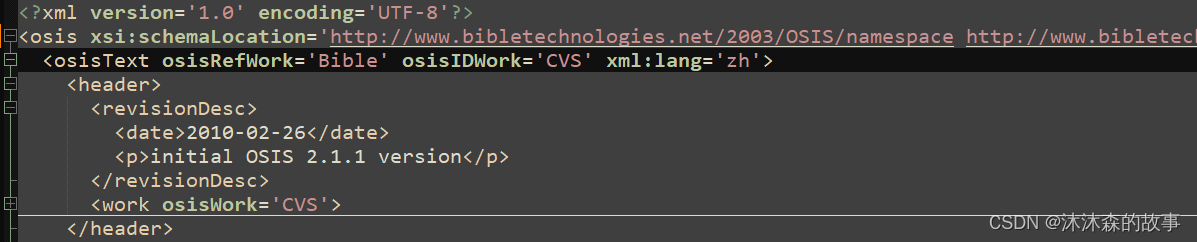
在加载cvs.xml之前还需要对cvs.xml做一些修改,打开cvs.xml,找到节点,将里面的属性全部删除掉
删除完成之后与下面保持一致。
要查询首先需要加载本地xml到内存中
python
# 构建cvs.xml的路径
bible_xml_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "static", "cvs.xml")
tree = ET.parse(file_path)
bible_root = tree.getroot()
三、输入解析
在设计这款软件的时候,考虑了有5中搜索方式:
- 书名(如:创世记 获取整本书内容)
- 书名章 (如:创世记1 获取书的第一章内容)
- 书名章-章 (如:创世记1-4 获取书的第一章到第4章内容)
- 书名章:节 (如:创世记1:1 获取书的第一章第一节内容)
- 书名章:节-节 (如:创世记1:1-10 获取书的第一章第一节到第十节内容)
同时还设计了不同的语言的输入,目前可以通过中文、英文、繁体 进行输入搜索。


这里通过正则表达式来对输入进行匹配,从而从输入种提取到书名、章数和节数,允许通过中文、英文、繁体进行检索。
python
# 匹配书名1:1-10的格式
pattern_range_with_verse = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d+):(\d+)-(\d+)"
# 匹配书名1-4的格式
pattern_range = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d+)-(\d+)"
# 匹配书名加章节格式的正则表达式
pattern = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d*):?(\d*)"四、获取经文
通过解析搜索关键字,我们能够获取到书名ID,章和节,通过这三个参数可以生成不同的xpath,用来从xml中查询数据。
- 情况一:输入关键字包含书、章和节,并且节包含"-"
python
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse"- 情况2:输入关键字包含书、章和节,并且节不包含"-"
python
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse[@osisID='{osis_id}.{chapter}.{verse}']"- 情况3:输入关键字包含书和章,并且章包含"-"
python
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{ch_num}']/verse"- 情况4:输入关键字包含书和章,并且章不包含"-"
python
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse"- 情况5:输入关键字只包含书
python
xpath = f".//div[@osisID='{osis_id}']//verse"五、软件打包
--onefile 打包成单个文件
--noconsole 无控制台
-i favicon.ico 给软件添加图标,要求是.ico格式的文件
--add-data "static;static" 将static文件夹和软件打包在一起
打包命令:
python
pyinstaller --onefile --noconsole -i favicon.ico --add-data "static;static" BibleQ.py七、代码全文
python
import os
import tkinter as tk
from tkinter import messagebox, ttk
import xml.etree.ElementTree as ET
import re
from ttkbootstrap import Style
from tkinter import PhotoImage
# 中文到osisID的映射
chinese_to_osisid_mapping = {
"创世记": "Gen","出埃及记": "Exod","利未记": "Lev","民数记": "Num","申命记": "Deut","约书亚记": "Josh","士师记": "Judg",
"路得记": "Ruth","撒母耳记上": "1Sam","撒母耳记下": "2Sam","列王记上": "1Kgs","列王记下": "2Kgs","历代志上": "1Chr",
"历代志下": "2Chr","以斯拉记": "Ezra","尼希米记": "Neh","以斯帖记": "Esth","约伯记": "Job","诗篇": "Ps","箴言": "Prov",
"传道书": "Eccl","雅歌": "Song","以赛亚书": "Isa","耶利米书": "Jer","耶利米哀歌": "Lam","以西结书": "Ezek","但以理书": "Dan",
"何西阿书": "Hos","约珥书": "Joel","阿摩司书": "Amos","俄巴底亚书": "Obad","约拿书": "Jonah","弥迦书": "Mic","那鸿书": "Nah",
"哈巴谷书": "Hab","西番雅书": "Zeph","哈该书": "Hag","撒迦利亚书": "Zech","玛拉基书": "Mal","马太福音": "Matt","马可福音": "Mark",
"路加福音": "Luke","约翰福音": "John","使徒行传": "Acts","罗马书": "Rom","哥林多前书": "1Cor","哥林多后书": "2Cor",
"加拉太书": "Gal","以弗所书": "Eph","腓立比书": "Phil","歌罗西书": "Col","帖撒罗尼迦前书": "1Thess","帖撒罗尼迦后书": "2Thess",
"提摩太前书": "1Tim","提摩太后书": "2Tim","提多书": "Titus","腓利门书": "Phlm","希伯来书": "Heb","雅各书": "Jas",
"彼得前书": "1Pet","彼得后书": "2Pet","约翰一书": "1John","约翰二书": "2John","约翰三书": "3John","犹大书": "Jude","启示录": "Rev"
}
# 英文到osisID的映射
english_to_osisid_mapping = {
"Genesis": "Gen","Exodus": "Exod","Leviticus": "Lev","Numbers": "Num","Deuteronomy": "Deut","Joshua": "Josh",
"Judges": "Judg","Ruth": "Ruth","1 Samuel": "1Sam","2 Samuel": "2Sam","1 Kings": "1Kgs","2 Kings": "2Kgs",
"1 Chronicles": "1Chr","2 Chronicles": "2Chr","Ezra": "Ezra","Nehemiah": "Neh","Esther": "Esth","Job": "Job",
"Psalms": "Ps","Proverbs": "Prov","Ecclesiastes": "Eccl","Song of Solomon": "Song","Isaiah": "Isa","Jeremiah": "Jer",
"Lamentations": "Lam","Ezekiel": "Ezek","Daniel": "Dan","Hosea": "Hos","Joel": "Joel","Amos": "Amos","Obadiah": "Obad",
"Jonah": "Jonah","Micah": "Mic","Nahum": "Nah","Habakkuk": "Hab","Zephaniah": "Zeph","Haggai": "Hag","Zechariah": "Zech",
"Malachi": "Mal","Matthew": "Matt","Mark": "Mark","Luke": "Luke","John": "John","Acts": "Acts","Romans": "Rom",
"1 Corinthians": "1Cor","2 Corinthians": "2Cor","Galatians": "Gal","Ephesians": "Eph","Philippians": "Phil",
"Colossians": "Col","1 Thessalonians": "1Thess","2 Thessalonians": "2Thess","1 Timothy": "1Tim","2 Timothy": "2Tim",
"Titus": "Titus","Philemon": "Phlm","Hebrews": "Heb","James": "Jas","1 Peter": "1Pet","2 Peter": "2Pet",
"1 John": "1John","2 John": "2John","3 John": "3John","Jude": "Jude","Revelation": "Rev"
}
# 繁体中文到osisID的映射
traditional_to_osisid_mapping = {
"創世記": "Gen","出埃及記": "Exod","利未記": "Lev","民數記": "Num","申命記": "Deut","約書亞記": "Josh","士師記": "Judg",
"路得記": "Ruth","撒母耳記上": "1Sam","撒母耳記下": "2Sam","列王記上": "1Kgs","列王記下": "2Kgs","歷代志上": "1Chr",
"歷代志下": "2Chr","以斯拉記": "Ezra","尼希米記": "Neh","以斯帖記": "Esth","約伯記": "Job","詩篇": "Ps","箴言": "Prov",
"傳道書": "Eccl","雅歌": "Song","以賽亞書": "Isa","耶利米書": "Jer","耶利米哀歌": "Lam","以西結書": "Ezek","但以理書": "Dan",
"何西阿書": "Hos","約珥書": "Joel","阿摩司書": "Amos","俄巴底亞書": "Obad","約拿書": "Jonah","彌迦書": "Mic","那鴻書": "Nah",
"哈巴谷書": "Hab","西番雅書": "Zeph","哈該書": "Hag","撒迦利亚書": "Zech","瑪拉基書": "Mal","馬太福音": "Matt","馬可福音": "Mark",
"路加福音": "Luke","約翰福音": "John","使徒行傳": "Acts","羅馬書": "Rom","哥林多前書": "1Cor","哥林多後書": "2Cor",
"加拉太書": "Gal","以弗所書": "Eph","腓立比書": "Phil","歌羅西書": "Col","帖撒羅尼迦前書": "1Thess","帖撒羅尼迦後書": "2Thess",
"提摩太前書": "1Tim","提摩太後書": "2Tim","提多書": "Titus","腓利門書": "Phlm","希伯來書": "Heb","雅各書": "Jas",
"彼得前書": "1Pet","彼得後書": "2Pet","約翰一書": "1John","約翰二書": "2John","約翰三書": "3John","猶大書": "Jude","啟示錄": "Rev"
}
# 统一合并的映射表,用于解析输入时的查找
combined_mapping = {}
combined_mapping.update(chinese_to_osisid_mapping)
combined_mapping.update(english_to_osisid_mapping)
combined_mapping.update(traditional_to_osisid_mapping)
# 全局变量,用于存储加载的圣经XML数据
bible_root = None
# 默认设置
default_theme = 'superhero'
default_font_family = '宋体'
default_font_size = 16
current_theme = default_theme
current_font_family = default_font_family
current_font_size = default_font_size
# 全局变量,用于存储Style对象
style = None
# 加载圣经XML文件的函数
def load_bible_xml(file_path):
global bible_root
try:
tree = ET.parse(file_path)
bible_root = tree.getroot()
if bible_root:
print("圣经加载成功。")
return True
else:
print("圣经加载失败。")
return False
except Exception as e:
print("圣经加载出错。")
return False
# 修改 parse_input 函数,添加支持书名1-4和书名1:1-10的格式
def parse_input(input_text):
# 匹配书名1:1-10的格式
pattern_range_with_verse = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d+):(\d+)-(\d+)"
# 匹配书名1-4的格式
pattern_range = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d+)-(\d+)"
# 匹配书名加章节格式的正则表达式
pattern = r"([\u4e00-\u9fa5A-Za-z]+)\s*(\d*):?(\d*)"
# 尝试匹配书名1:1-10的格式
match_range_with_verse = re.match(pattern_range_with_verse, input_text.strip())
if match_range_with_verse:
book = match_range_with_verse.group(1) # 提取书名
chapter = match_range_with_verse.group(2) # 提取章节号
verse_start = match_range_with_verse.group(3) # 提取起始节号
verse_end = match_range_with_verse.group(4) # 提取结束节号
osis_id = combined_mapping.get(book, None)
if osis_id:
return osis_id, chapter, verse_start + "-" + verse_end
# 尝试匹配书名1-4的格式
match_range = re.match(pattern_range, input_text.strip())
if match_range:
book = match_range.group(1) # 提取书名
chapter_start = match_range.group(2) # 提取起始章节号
chapter_end = match_range.group(3) # 提取结束章节号
osis_id = combined_mapping.get(book, None)
if osis_id:
print(osis_id)
print(chapter_start)
print(chapter_end)
return osis_id, chapter_start + "-" + chapter_end, None
# 尝试匹配书名格式
match = re.match(pattern, input_text.strip())
print(match)
if match:
book = match.group(1).lower().capitalize() # 提取书名
chapter = match.group(2) # 提取章节号
verse = match.group(3) # 提取节号
osis_id = combined_mapping.get(book, None)
if osis_id:
return osis_id, chapter, verse
# 如果都没有匹配成功,返回None
return None, None, None
def get_bible_text(osis_id, chapter, verse):
global bible_root
if not bible_root:
return "圣经数据尚未加载。"
verses_text = []
previous_chapter = None
# 处理章节和经文的范围查询
if chapter and verse:
if '-' in verse:
verse_start, verse_end = map(int, verse.split('-'))
# 获取指定范围内的经文
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse"
result = bible_root.findall(xpath)
for verse_element in result:
verse_num = int(verse_element.get('osisID').split('.')[-1])
if verse_start <= verse_num <= verse_end:
current_chapter = chapter
if previous_chapter and previous_chapter != current_chapter:
verses_text.append("\n") # 添加空行
verses_text.append(f"[{current_chapter},{verse_num}] {verse_element.text.strip()}")
previous_chapter = current_chapter
else:
# 获取单个经文
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse[@osisID='{osis_id}.{chapter}.{verse}']"
verse_element = bible_root.find(xpath)
if verse_element is not None:
verses_text.append(f"[{chapter},{verse}] {verse_element.text.strip()}")
elif chapter:
# 获取整个章节的经文
if '-' in chapter:
chapter_start, chapter_end = map(int, chapter.split('-'))
# 获取指定范围内的章节
for ch_num in range(chapter_start, chapter_end + 1):
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{ch_num}']/verse"
result = bible_root.findall(xpath)
for verse_element in result:
verse_num = int(verse_element.get('osisID').split('.')[-1])
current_chapter = str(ch_num)
if previous_chapter and previous_chapter != current_chapter:
verses_text.append("\n") # 添加空行
verses_text.append(f"[{current_chapter},{verse_num}] {verse_element.text.strip()}")
previous_chapter = current_chapter
else:
# 获取单个章节的经文
xpath = f".//div[@osisID='{osis_id}']/chapter[@osisID='{osis_id}.{chapter}']/verse"
result = bible_root.findall(xpath)
for verse_element in result:
verse_num = int(verse_element.get('osisID').split('.')[-1])
verses_text.append(f"[{chapter},{verse_num}] {verse_element.text.strip()}")
else:
# 获取整本书的经文
xpath = f".//div[@osisID='{osis_id}']//verse"
result = bible_root.findall(xpath)
for verse_element in result:
book, ch_num, verse_num = verse_element.get('osisID').split('.')
current_chapter = ch_num
if previous_chapter and previous_chapter != current_chapter:
verses_text.append("\n") # 添加空行
verses_text.append(f"[{ch_num},{verse_num}] {verse_element.text.strip()}")
previous_chapter = current_chapter
if verses_text:
return '\n'.join(verses_text)
else:
return "未找到对应经文。"
# Function to show search result in the GUI
def show_search_result(search_input):
global root_frame
global current_font_size
global current_font_family
clear_frame(root_frame)
search_label = ttk.Label(root_frame, text="Search Results", font=(current_font_family, 18, "bold"))
search_label.grid(row=0, column=0, columnspan=2, pady=10, sticky="ew")
search_label.configure(anchor="center")
# Create search box to show search input and allow new search
search_frame = ttk.Frame(root_frame, padding=10)
search_frame.grid(row=1, column=0, sticky="ew")
search_entry = ttk.Entry(search_frame, font=(current_font_family, 12))
search_entry.insert(0, search_input)
search_entry.grid(row=0, column=0, sticky="ew")
search_frame.columnconfigure(0, weight=1)
# Bind Enter key to perform search
search_entry.bind('<Return>', lambda event: on_search_from_result(search_entry.get().strip()))
# Show search result text area
text_scroll = tk.Scrollbar(root_frame)
text_scroll.grid(row=2, column=1, sticky="ns")
result_text = tk.Text(root_frame, wrap=tk.WORD, yscrollcommand=text_scroll.set, font=(current_font_family, current_font_size))
result_text.grid(row=2, column=0, sticky="nsew", padx=10, pady=10)
text_scroll.config(command=result_text.yview)
osis_id, chapter, verse = parse_input(search_input)
if osis_id:
bible_text = get_bible_text(osis_id, chapter, verse)
result_text.insert(tk.END, bible_text)
else:
result_text.insert(tk.END, "输入格式错误或未找到对应经文。")
# Button to go back to search page
style.configure('Large.TButton', font=(current_font_family, 12))
back_button = ttk.Button(root_frame, text="Return", command=open_search_page, style='Large.TButton', bootstyle="primary-outline")
back_button.grid(row=3, column=0, pady=10)
# Configure grid row and column weights to make search box and results resizeable
root_frame.grid_rowconfigure(2, weight=1)
root_frame.grid_columnconfigure(0, weight=1)
# Function to clear frame content
def clear_frame(frame):
for widget in frame.winfo_children():
widget.destroy()
# Function to handle search action from result page
def on_search_from_result(search_input):
show_search_result(search_input.strip())
# Function to open search page
def open_search_page():
clear_frame(root_frame)
main_window()
# Function to handle search from search page
def on_search():
search_input = entry.get().strip()
if search_input:
show_search_result(search_input)
else:
messagebox.showwarning("警告", "请输入要搜索的经文。")
# Function to create and configure the main window
def create_main_window():
global root_frame
root_window = tk.Tk()
root_window.title("BibleQ")
root_window.geometry("800x600")
global style
style = Style(theme=current_theme)
root_frame = ttk.Frame(root_window, padding="20")
root_frame.pack(fill=tk.BOTH, expand=True)
main_window()
root_window.mainloop()
# 主界面,包含搜索框和设置按钮
def main_window():
global current_font_family
title_label = ttk.Label(root_frame, text="Hallelujah,Bible", font=(current_font_family, 26, "bold"))
title_label.grid(row=0, column=0, columnspan=2, pady=20, sticky="ew")
title_label.configure(anchor="center")
global entry
entry = ttk.Entry(root_frame, font=(current_font_family, 14))
entry.grid(row=1, column=0, padx=20, pady=10, sticky="ew")
entry.focus()
entry.bind('<Return>', lambda event=None: on_search())
# 加载图片(注意:PhotoImage支持的格式主要是PNG和GIF)
image = PhotoImage(file=os.path.join(os.path.dirname(os.path.abspath(__file__)), "static", "spring.png"))
# 调整图片大小
image = image.subsample(3, 3) # 缩小图片
# 创建一个Label,将图片放置在上面
image_label = ttk.Label(root_frame, image=image)
image_label.image = image # 保持对图片的引用
image_label.grid(row=2, column=0, columnspan=2, pady=20, sticky="ew")
image_label.configure(anchor="center")
spring_label = ttk.Label(root_frame, text="哥林多前书 爱 13:4-6", font=(current_font_family, 16, "bold"))
spring_label.grid(row=3, column=0, columnspan=2, pady=20, sticky="ew")
spring_label.configure(anchor="center")
spring_content = ttk.Label(root_frame, text=" 是恒久忍耐,又有恩慈;爱是不嫉妒;\n\n"
"爱是不自夸,不张狂,不做害羞的事,不求自己的益处,\n\n"
"不轻易发怒,不计算人的恶,不喜欢不义,只喜欢真理。",
font=(current_font_family, 16))
spring_content.grid(row=4, column=0, columnspan=2, sticky="ew")
spring_content.configure(anchor="center")
# Configure grid row and column weights to make search box and results resizeable
root_frame.grid_rowconfigure(5, weight=1)
root_frame.grid_columnconfigure(0, weight=1)
if __name__ == "__main__":
# 获取当前文件的目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 构建cvs.xml的路径
bible_xml_path = os.path.join(current_dir, "static", "cvs.xml")
if load_bible_xml(bible_xml_path):
create_main_window()
else:
print("Failed to load Bible XML.")|-----------------------------------------------|
| TechX ------ 心探索、心进取! 每一次跌倒都是一次成长 每一次努力都是一次进步 |
END 感谢您阅读本篇博客!希望这篇内容对您有所帮助。如果您有任何问题或意见,或者想要了解更多关于本主题的信息,欢迎在评论区留言与我交流。我会非常乐意与大家讨论和分享更多有趣的内容。
如果您喜欢本博客,请点赞和分享给更多的朋友,让更多人受益。同时,您也可以关注我的博客,以便及时获取最新的更新和文章。
在未来的写作中,我将继续努力,分享更多有趣、实用的内容。再次感谢大家的支持和鼓励,期待与您在下一篇博客再见!