摘要
讯飞星火认知大模型,作为科大讯飞精心打造的一款人工智能模型,在自然语言理解和生成方面展现出了卓越的能力。这款模型通过深度学习技术和大量数据的训练,具备了强大的语言理解、文本生成和对话交互等功能。
一、模型功能概述
讯飞星火认知大模型能够为用户提供个性化的信息服务,包括但不限于语音识别、文本分析、自动翻译以及智能问答等。它在多个应用场景中都能发挥出色,如在智能客服系统中准确理解用户问题,或在内容创作领域协助生成高质量的文章或报告。
讯飞星火提供了三种不同的API模型供用户选择:Spark3.5 Max、Spark Pro、Spark Lite。这些模型均具备不同的性能和功能特点,以满足不同用户的需求。目前,这些模型都提供了免费的调用额度,供用户试用和体验。
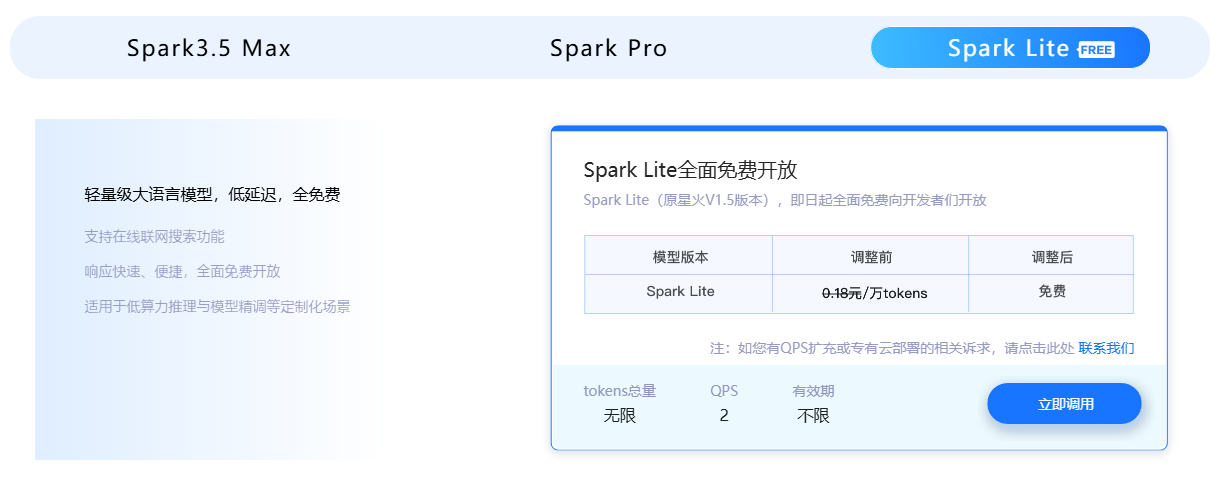
讯飞星火Lite API永久免费开放!

讯飞星火Pro/Max API免费赠送200万tokens,相当于三百万汉字。
链接:https://xinghuo.xfyun.cn/sparkapi?ch=gjaa
通过本文你能力学到:
- Python调用方式
作为广泛使用的编程语言,Python提供了方便的接口来调用讯飞星火的API。您可以通过官方文档获取Python SDK,并按照指南进行调用。 - 其他调用方式
除了Python,讯飞星火也支持其他编程语言的调用方式。您可以在官方文档中查找对应的SDK或API接口,以适应您的开发需求。
Spark3.5 Max/Spark Pro/Spark Lite的区别
讯飞星火Spark3.5 Max :最强大的星火大模型版本,效果最优支持联网搜索、天气、日期等多个内置插件核心能力全面升级,各场景应用效果普遍提升支持System角色人设与FunctionCall函数调用。讯飞星火Spark3.5 Max所有套餐价格:

讯飞星火Spark Pro:专业级大语言模型,兼顾模型效果与性能。数学、代码、医疗、教育等场景专项优化支持联网搜索、天气、日期等多个内置插件。覆盖大部分知识问答、语言理解、文本创作等多个场景。讯飞星火Spark Pro所有套餐价格:
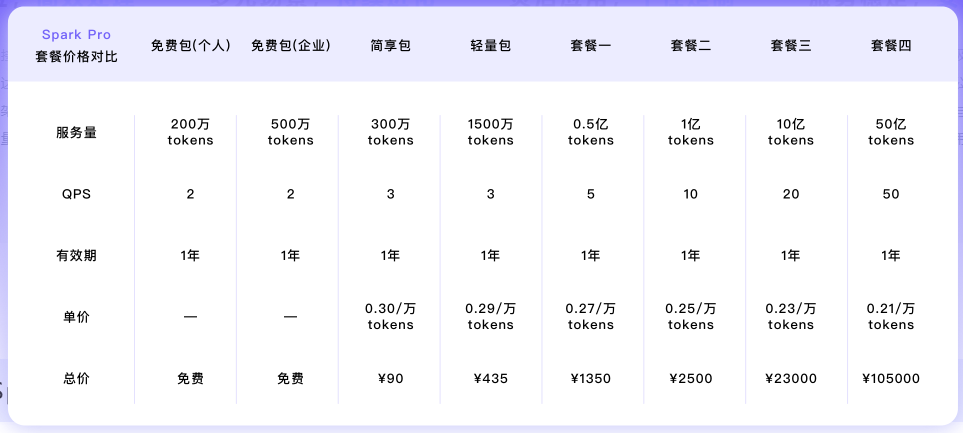
讯飞星火 Spark Lite :轻量级大语言模型,低延迟,全免费。支持在线联网搜索功能,响应快速、便捷,全面免费开放,适用于低算力推理与模型精调等定制化场景。Spark Lite免费向大家开放!

支持的能力
API调用支持的方式
支持的方式有:WebAPI、安卓、IOS、Windows、Linux等多种方式。

注意事项:
关于Web接口的说明:
必须符合 websocket 协议规范(rfc6455)。
websocket握手成功后用户在60秒内没有发送请求数据,服务侧会主动断开。
本接口默认采用短链接的模式,即接口每次将结果完整返回给用户后会主动断开链接,用户在下次发送请求的时候需要重新握手链接。
关于SDK的说明:
高效接入:SDK统一封装鉴权模块,接口简单最快三步完成SDK集成接入
稳定可靠: 统一连接池保障连接时效性,httpDNS保障请求入口高可用性
配套完善:支持多路并发用户回调上下文绑定,交互历史管理及排障日志回传收集
多平台兼容:覆盖Windows,Linux,Android,iOS以及其他交叉编译平台
关于tokens的说明(重要):
接口采用tokens方式计费。
tokens与词表、分词方案相关,没有精确的计算方式,但是接口会返回本次计费的tokens数(详见接口文档响应参数描述)。
接口计费会将请求text字段下所有的content内容均计费,开发者需要酌情考虑保留的历史对话信息数量,避免浪费tokens(最大的输入tokens见接口文档参数描述)。
关于文本审核说明(重要):
接口会对用户输入和AI输出内容进行文本审核,会对包括但不限于:(1) 涉及国家安全的信息;(2) 涉及政治与宗教类的信息;(3) 涉及暴力与恐怖主义的信息;(4) 涉及黄赌毒类的信息;(5) 涉及不文明的信息 的输入输出赋予错误码返回(详见错误码部分10013和10014说明)
在线调试
打开链接:https://xinghuo.xfyun.cn/sparkapi?ch=gjaa,选择在线调试:
然后,注册账号,选择一种方式登录,如下图:
创建一个应用,如下图:
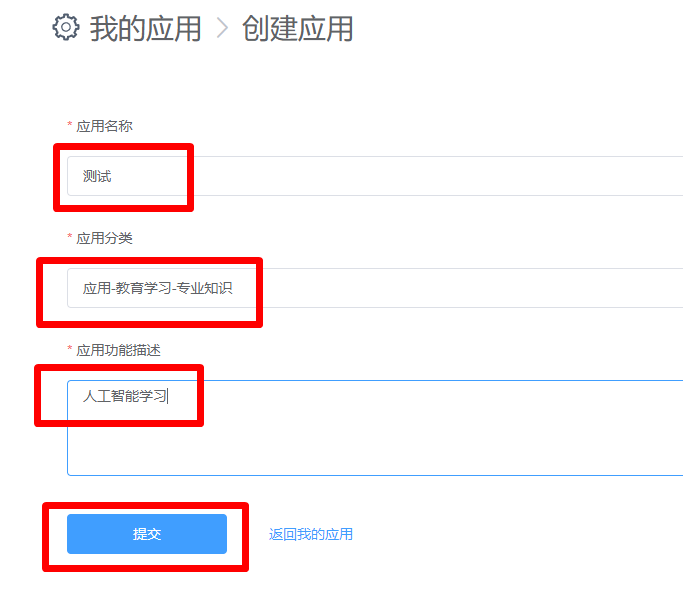
然后,我们填写内容,如下:

发现不能调用,为啥呢?我们还没有领取tokens,所以下一步先领取tokens。链接:https://xinghuo.xfyun.cn/sparkapi?scr=true,

选择我们刚才建立的应用测试,选择免费包,如下图:

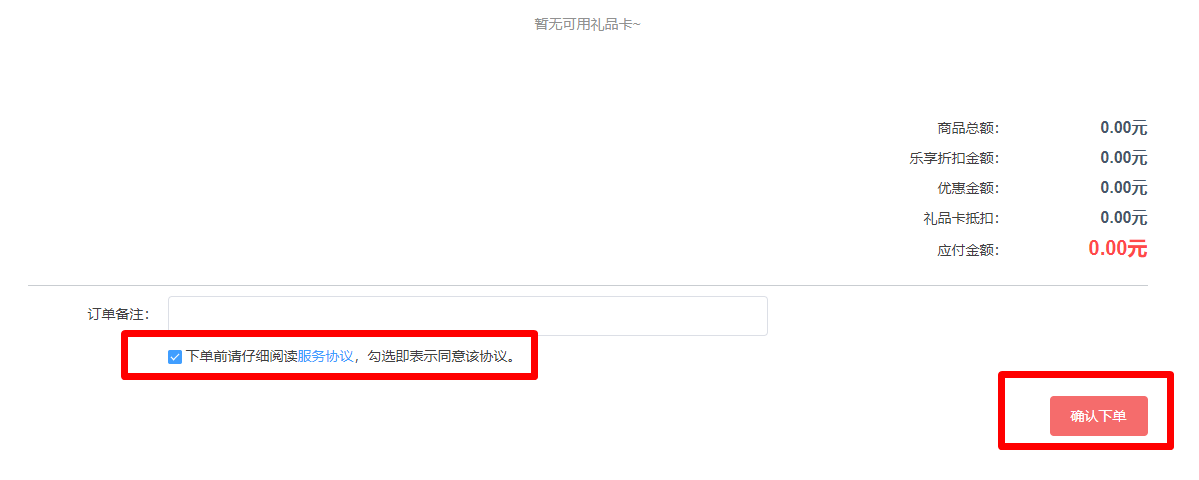
填写好后,下单即可!

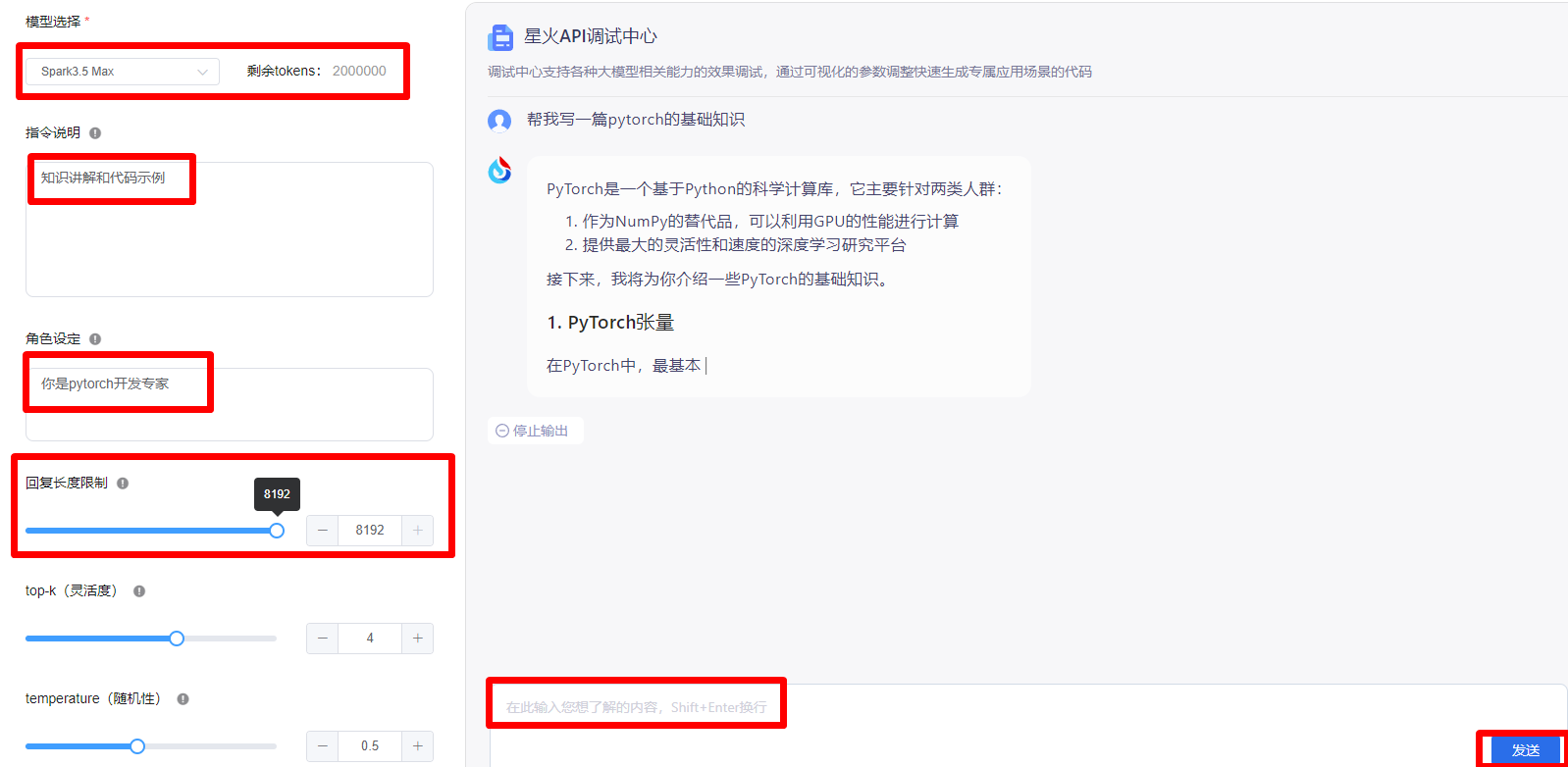
显示交易成功后,就可以调试了!选择模型,设置指令,角色设定,回复长度等。写完之后,就可以在输入框里填写你想要输出的内容。如下图:
星火认知大模型Web API调用文档
在上面完成在线调试后,点击更多服务信息查询,如下图:
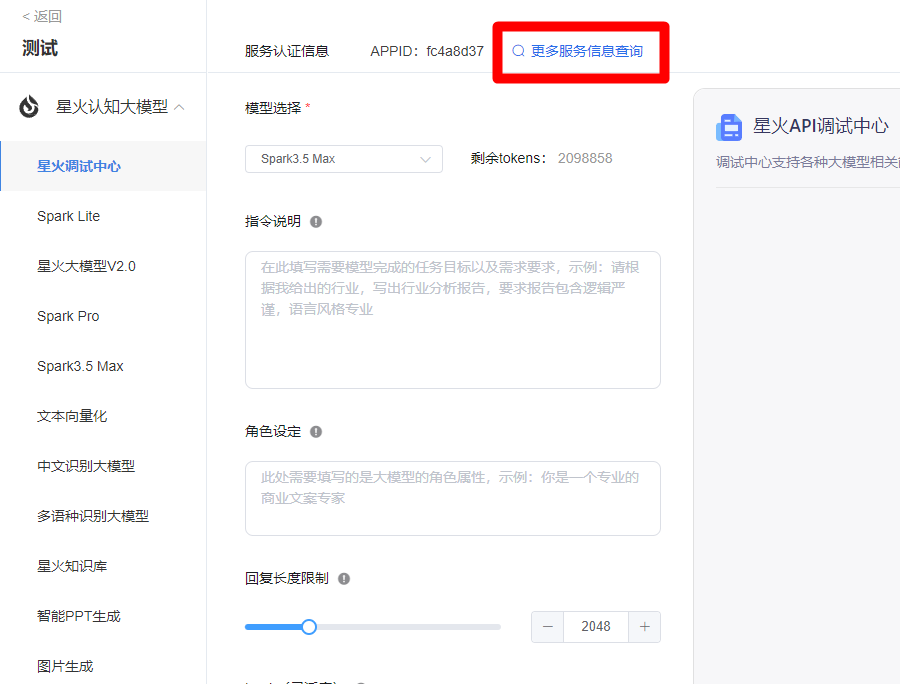
然后找到APP_ID、API_SECRET、API_KEY 等信息,如下图: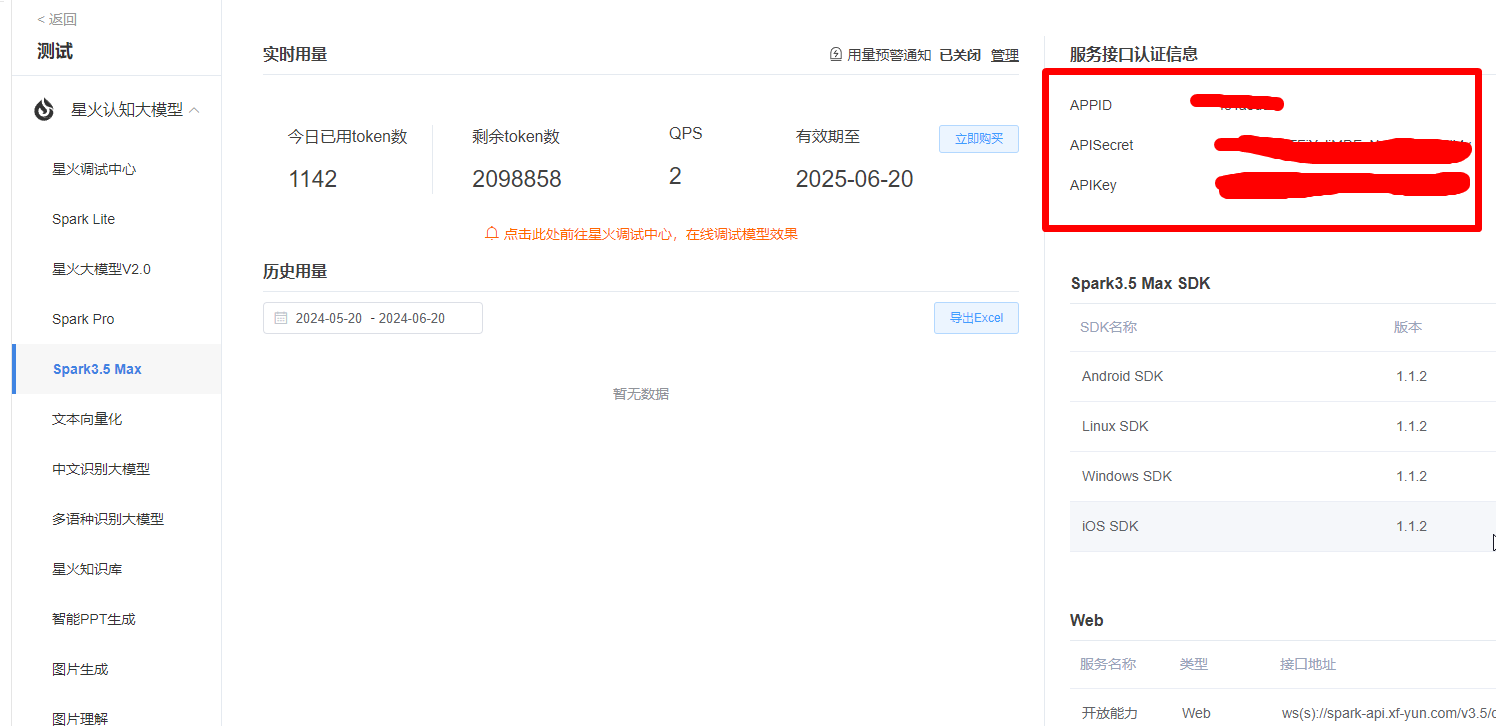
Python集成星火认知大模型示例
首先,安装PyPI上的包,在python环境中执行命令,命令如下:
pip install --upgrade spark_ai_python然后,执行代码:
python
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
#星火认知大模型Spark3.5 Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
#星火认知大模型Spark3.5 Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
if __name__ == '__main__':
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content='你好呀'
)]
handler = ChunkPrintHandler()
a = spark.generate([messages], callbacks=[handler])
print(a)输出结果:
generations=[[ChatGeneration(text="PyTorch是一个基于Python的科学计算库,主要用于深度学习研究和开发。它提供了两个高级功能:张量计算(类似于NumPy)和深度神经网络。以下是一些PyTorch基础知识:\n\n1. 安装PyTorch:\n\n```bash\npip install torch torchvision\n```\n\n2. 导入库:\n\n```python\nimport torch\n```\n\n3. 张量:\n\n张量是PyTorch中的基本数据结构,类似于多维数组。可以使用`torch.Tensor()`创建张量,或者使用`torch.randn()`创建一个随机张量。\n\n```python\n# 创建一个2x3的浮点数张量\nx = torch.Tensor([[1, 2, 3], [4, 5, 6]])\nprint(x)\n\n# 创建一个2x3的随机张量\ny = torch.randn(2, 3)\nprint(y)\n```\n\n4. 张量操作:\n\n张量支持各种操作,如加法、乘法、索引等。\n\n```python\n# 张量加法\nz = torch.add(x, y)\nprint(z)\n\n# 张量乘法\nz = torch.mul(x, y)\nprint(z)\n\n# 张量索引\nprint(x[:, 1])\n```\n\n5. 自动求导:\n\nPyTorch中的张量默认是可自动求导的,这对于训练神经网络非常有用。可以使用`.requires_grad_()`方法将张量设置为可求导。\n\n```python\n# 创建一个可求导的张量\nx = torch.ones(2, 2, requires_grad=True)\nprint(x)\n\n# 计算梯度\ny = x + 2\nz = y * y * 3\nout = z.mean()\nprint(out)\n\n# 反向传播\nout.backward()\nprint(x.grad)\n```\n\n6. 神经网络:\n\n使用`torch.nn`模块可以定义神经网络。首先定义一个继承自`torch.nn.Module`的类,然后实现`__init__()`和`forward()`方法。\n\n```python\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(1, 6, 3)\n self.conv2 = nn.Conv2d(6, 16, 3)\n self.fc1 = nn.Linear(16 * 6 * 6, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n\n def forward(self, x):\n x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))\n x = F.max_pool2d(F.relu(self.conv2(x)), 2)\n x = x.view(-1, self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n def num_flat_features(self, x):\n size = x.size()[1:]\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n\nnet = Net()\nprint(net)\n```\n\n7. 训练神经网络:\n\n使用`torch.optim`模块中的优化器(如SGD、Adam等)来训练神经网络。在每个训练循环中,执行前向传播、计算损失、反向传播和优化器更新权重。\n\n```python\n# 定义超参数\ninput_size = 784\nhidden_size = 500\nnum_classes = 10\nnum_epochs = 5\nbatch_size = 100\nlearning_rate = 0.001\n\n# 加载MNIST数据集\ntrain_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)\ntest_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=torchvision.transforms.ToTensor())\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)\n\n# 定义模型、损失函数和优化器\nmodel = Net()\ncriterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n\n# 训练模型\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n images = images.view(-1, 28*28)\n outputs = model(images)\n loss = criterion(outputs, labels)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n if (i+1) % 100 == 0:\n print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))\n```", message=AIMessage(content="PyTorch是一个基于Python的科学计算库,主要用于深度学习研究和开发。它提供了两个高级功能:张量计算(类似于NumPy)和深度神经网络。以下是一些PyTorch基础知识:\n\n1. 安装PyTorch:\n\n```bash\npip install torch torchvision\n```\n\n2. 导入库:\n\n```python\nimport torch\n```\n\n3. 张量:\n\n张量是PyTorch中的基本数据结构,类似于多维数组。可以使用`torch.Tensor()`创建张量,或者使用`torch.randn()`创建一个随机张量。\n\n```python\n# 创建一个2x3的浮点数张量\nx = torch.Tensor([[1, 2, 3], [4, 5, 6]])\nprint(x)\n\n# 创建一个2x3的随机张量\ny = torch.randn(2, 3)\nprint(y)\n```\n\n4. 张量操作:\n\n张量支持各种操作,如加法、乘法、索引等。\n\n```python\n# 张量加法\nz = torch.add(x, y)\nprint(z)\n\n# 张量乘法\nz = torch.mul(x, y)\nprint(z)\n\n# 张量索引\nprint(x[:, 1])\n```\n\n5. 自动求导:\n\nPyTorch中的张量默认是可自动求导的,这对于训练神经网络非常有用。可以使用`.requires_grad_()`方法将张量设置为可求导。\n\n```python\n# 创建一个可求导的张量\nx = torch.ones(2, 2, requires_grad=True)\nprint(x)\n\n# 计算梯度\ny = x + 2\nz = y * y * 3\nout = z.mean()\nprint(out)\n\n# 反向传播\nout.backward()\nprint(x.grad)\n```\n\n6. 神经网络:\n\n使用`torch.nn`模块可以定义神经网络。首先定义一个继承自`torch.nn.Module`的类,然后实现`__init__()`和`forward()`方法。\n\n```python\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(1, 6, 3)\n self.conv2 = nn.Conv2d(6, 16, 3)\n self.fc1 = nn.Linear(16 * 6 * 6, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n\n def forward(self, x):\n x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))\n x = F.max_pool2d(F.relu(self.conv2(x)), 2)\n x = x.view(-1, self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n def num_flat_features(self, x):\n size = x.size()[1:]\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n\nnet = Net()\nprint(net)\n```\n\n7. 训练神经网络:\n\n使用`torch.optim`模块中的优化器(如SGD、Adam等)来训练神经网络。在每个训练循环中,执行前向传播、计算损失、反向传播和优化器更新权重。\n\n```python\n# 定义超参数\ninput_size = 784\nhidden_size = 500\nnum_classes = 10\nnum_epochs = 5\nbatch_size = 100\nlearning_rate = 0.001\n\n# 加载MNIST数据集\ntrain_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)\ntest_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=torchvision.transforms.ToTensor())\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)\n\n# 定义模型、损失函数和优化器\nmodel = Net()\ncriterion = nn.CrossEntropyLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n\n# 训练模型\nfor epoch in range(num_epochs):\n for i, (images, labels) in enumerate(train_loader):\n images = images.view(-1, 28*28)\n outputs = model(images)\n loss = criterion(outputs, labels)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n if (i+1) % 100 == 0:\n print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))\n```"))]] llm_output={'token_usage': {'question_tokens': 7, 'prompt_tokens': 7, 'completion_tokens': 1359, 'total_tokens': 1366}} run=[RunInfo(run_id=UUID('7ff2abd7-11af-44da-b91d-6650c3ccfa0a'))]接口说明
请求地址
Tips: 星火大模型API当前有Lite、V2.0、Pro和Max四个版本,四个版本独立计量tokens。
传输协议 :ws(s),为提高安全性,强烈推荐wss
Spark3.5 Max请求地址,对应的domain参数为generalv3.5:
wss://spark-api.xf-yun.com/v3.5/chatSpark Pro请求地址,对应的domain参数为generalv3:
wss://spark-api.xf-yun.com/v3.1/chatSpark V2.0请求地址,对应的domain参数为generalv2:
wss://spark-api.xf-yun.com/v2.1/chatSpark Lite请求地址,对应的domain参数为general:
wss://spark-api.xf-yun.com/v1.1/chat请求参数
# 参数构造示例如下
{
"header": {
"app_id": "12345",
"uid": "12345"
},
"parameter": {
"chat": {
"domain": "generalv3.5",
"temperature": 0.5,
"max_tokens": 1024,
}
},
"payload": {
"message": {
# 如果想获取结合上下文的回答,需要开发者每次将历史问答信息一起传给服务端,如下示例
# 注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息
"text": [
{"role":"system","content":"你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} #设置对话背景或者模型角色
{"role": "user", "content": "你是谁"} # 用户的历史问题
{"role": "assistant", "content": "....."} # AI的历史回答结果
# ....... 省略的历史对话
{"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题
]
}
}
}接口请求字段由三个部分组成:header,parameter, payload。 字段解释如下
header部分

parameter.chat部分

payload.message.text部分
注:text下所有content累计内容 tokens需要控制在8192内

接口响应
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示
{
"header":{
"code":0,
"message":"Success",
"sid":"cht000cb087@dx18793cd421fb894542",
"status":2
},
"payload":{
"choices":{
"status":2,
"seq":0,
"text":[
{
"content":"我可以帮助你的吗?",
"role":"assistant",
"index":0
}
]
},
"usage":{
"text":{
"question_tokens":4,
"prompt_tokens":5,
"completion_tokens":9,
"total_tokens":14
}
}
}
}接口返回字段分为两个部分,header,payload。字段解释如下
header部分

payload.choices部分

payload.usage部分(在最后一次结果返回)

完整调用方式
# coding: utf-8
import _thread as thread
import os
import time
import base64
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket
import openpyxl
from concurrent.futures import ThreadPoolExecutor, as_completed
import os
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, gpt_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(gpt_url).netloc
self.path = urlparse(gpt_url).path
self.gpt_url = gpt_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.gpt_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, query=ws.query, domain=ws.domain))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
# print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
print(content,end='')
if status == 2:
print("#### 关闭会话")
ws.close()
def gen_params(appid, query, domain):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234",
# "patch_id": [] #接入微调模型,对应服务发布后的resourceid
},
"parameter": {
"chat": {
"domain": domain,
"temperature": 0.5,
"max_tokens": 4096,
"auditing": "default",
}
},
"payload": {
"message": {
"text": [{"role": "user", "content": query}]
}
}
}
return data
def main(appid, api_secret, api_key, gpt_url, domain, query):
wsParam = Ws_Param(appid, api_key, api_secret, gpt_url)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open)
ws.appid = appid
ws.query = query
ws.domain = domain
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
# SPARKAI_APP_ID = 'fc4a8d37'
# SPARKAI_API_SECRET = 'OTFlMjI1OTFjYzljMDEyNzk5ODA2NjMy'
# SPARKAI_API_KEY = '359cb64d9bbe50b44e4a7cb376685246'
if __name__ == "__main__":
main(
appid="fc4a8d37",
api_secret="OTFlMjI1OTFjYzljMDEyNzk5ODA2NjMy",
api_key="359cb64d9bbe50b44e4a7cb376685246",
#appid、api_secret、api_key三个服务认证信息请前往开放平台控制台查看(https://console.xfyun.cn/services/bm35)
gpt_url="wss://spark-api.xf-yun.com/v3.5/chat", # Max环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v3.1/chat" # Pro环境的地址
# Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # Lite环境的地址
domain="generalv3.5", # Max版本
# domain = "generalv3" # Pro版本
# domain = "general" # Lite版本址
query="帮我写一篇pytoch基础知识,输出的格式是markdown的,要求有详细的知识讲解和示例,字数不低于5000字"
)输出结果:
# PyTorch基础知识
## 1. PyTorch简介
PyTorch是一个基于Python的科学计算库,它主要针对两类人群:
1. 作为NumPy的替代品,可以利用GPU的性能进行计算
2. 提供最大的灵活性和速度的深度学习研究平台
.........................................