目录
[3.1 编码器和解码器架构的简要概述:](#3.1 编码器和解码器架构的简要概述:)
[3.2 训练机制:编码器和解码器架构中的前向和后向传播:](#3.2 训练机制:编码器和解码器架构中的前向和后向传播:)
[4.1. 添加嵌入层:](#4.1. 添加嵌入层:)
[4.2. 深度 LSTM 的使用:](#4.2. 深度 LSTM 的使用:)
一、说明
欢迎来到我们进入序列到序列模型世界的旅程!在本博客系列中,我们将深入探讨编码器和解码器架构的迷人领域,揭示它们在理解和生成顺序数据方面的巨大力量。从语言翻译到文本摘要,序列到序列模型通过无缝捕获序列数据中的依赖关系,彻底改变了各个领域。

二、什么是顺序数据?
顺序数据是指以特定顺序或顺序出现的任何数据。这可能包括广泛的信息,例如时间序列数据、文本数据、音频信号,甚至基因序列。以下是一些示例:
- **文本数据:**句子、段落或文档是顺序数据的示例。每个单词都以特定的顺序出现,并有助于文本的整体含义。
- **时间序列数据:**股票价格、温度测量值或传感器读数随时间变化是顺序数据的示例。这些值按特定的时间顺序记录。
- **音频信号:**录音或语音数据本质上是连续的。音频样本的序列表示声音的波形。
三、编码器解码器架构的高级概述:
如果我们将编码器解码器架构视为机器翻译模型,那么编码器-解码器架构的功能如下:编码器逐个标记接收输入数据,处理每个元素以捕获其上下文信息。
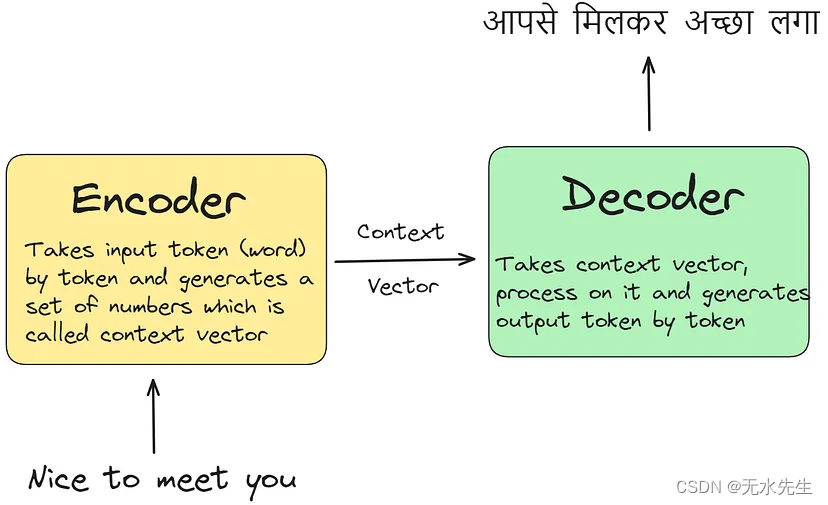
通过这个过程,它生成了一个全面的上下文向量。随后,解码器利用此上下文向量生成输出序列,例如翻译成另一种语言(例如印地语)。
3.1 编码器和解码器架构的简要概述:
在编码器内部,我们通常使用 LSTM 或 GRU 单元而不是简单的 RNN,因为它们能够更好地捕获序列中的长程依赖关系,这要归功于它们能够缓解梯度消失问题并保持长期记忆。在下图中,我们在四个时间戳上展开 LSTM 单元。

编码器详细图
例如,在 t=0 时,我们通过 LSTM 单元传递单词"Nice",该单元生成隐藏状态和单元状态值。同样,在 t=1 时,传递"to",在 t=2 时传递"meet",在 t=3 时传递"you"。最后,LSTM 单元通过组合隐藏状态和单元状态来生成上下文向量。此过程封装了编码器的操作方式,从而有效地捕获输入序列的上下文信息。
在解码器内部,我们还使用 LSTM 或 GRU 单元。最初,我们从编码器的最后一个时间戳中传递完全相同的隐藏状态 (ht) 和单元状态 (ct) 值。此外,我们还引入了一个特殊符号"<start>",表示 LSTM 输出生成的开始。在下图中,当传递"<start>"时,LSTM 单元开始产生输出"आपसे"。
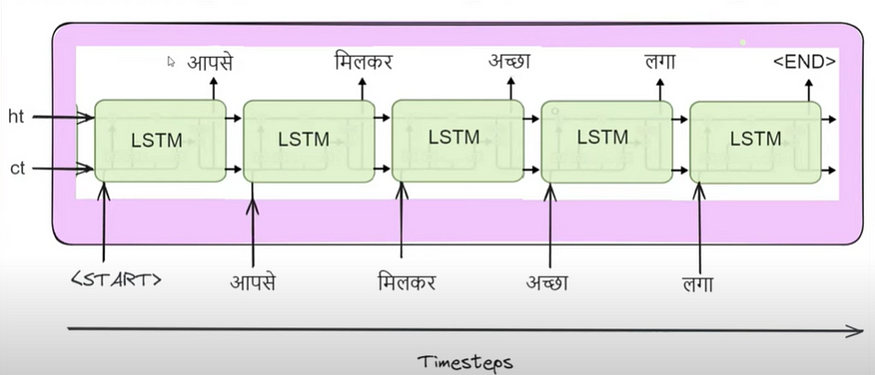
解码器详细示意图
随后,在 t=1 时,该输出被反馈到 LSTM,生成"मिलकर",并且此过程继续进行。例如,在 t=2 时,生成"अच्छा",在 t=3 时生成"लगा"。最后,当 LSTM 遇到特殊符号"<end>"时,它结束了输出生成过程,从而产生机器翻译输出"आपसे मिलकर अच्छा लगा"。这封装了解码器的工作过程。
3.2 训练机制:编码器和解码器架构中的前向和后向传播:
下图说明了编码器-解码器体系结构中的训练机制。首先,我们将数据集转换为启动训练所需的格式。

现在,我们将第一句话"Think it"输入编码器。它遍历 LSTM 层,最终,编码器生成其上下文向量。然后,该向量伴随着一个特殊符号"<start>",然后被转发到解码器。在解码器中,应用 softmax 函数来生成单词的概率。概率最高的单词成为解码器的输出。在下图中,在时间戳 t=0 时,解码器预测"लो",而正确的输出应为"सोच"。随后,我们将正确的输出传递给下一个时间戳 t=1,而不管 softmax 函数生成的输出如何。这个过程一直持续到我们遇到特殊符号"<end>",向解码器发出停止处理的信号。
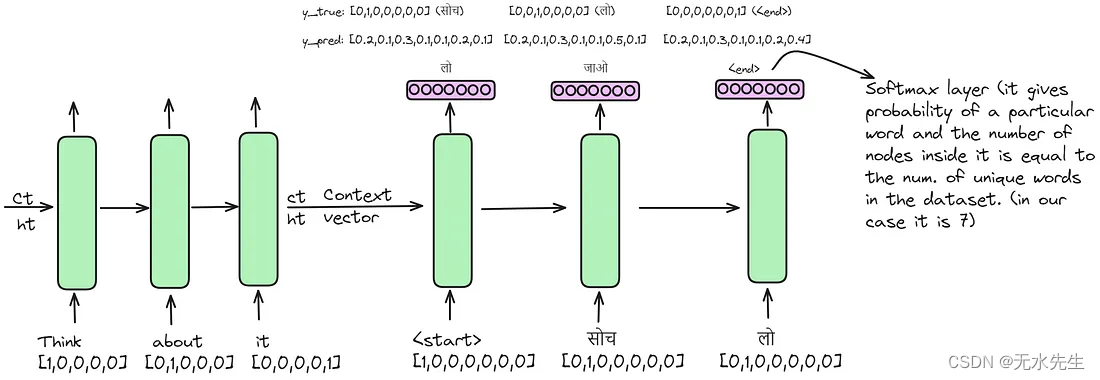
在完成第一句话的前向传播后,我们的下一步是计算损失函数。然后,我们调整梯度值,并相应地更新编码器和解码器的参数。此过程对数据集中的每个句子进行迭代,直到处理完所有句子。一旦完成,我们的训练就完成了,我们的模型也训练好了。

训练完成后,我们进入预测阶段。在下图中,我将演示如何进行预测。与在训练过程中,正确的输出被传递到解码器部分的后续时间戳不同,在预测过程中,我们将一个时间戳的输出馈送到下一个时间戳,而不管其准确性如何。由于我们在预测过程中缺少标签,因此此迭代过程会一直持续到我们遇到特殊符号"<end>",表示生成序列的完成。
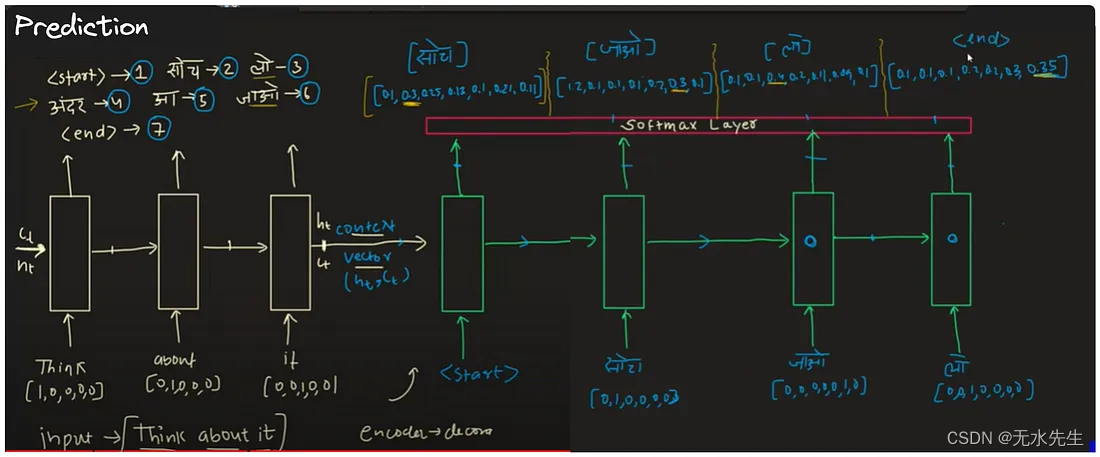

上图说明,即使模型犯了错误,它仍然可以实现高精度。尽管生成的输出中偶尔会出现错误,但模型的整体性能仍然令人满意。
四、编码器解码器架构的改进:
4.1. 添加嵌入层:
嵌入层将输入标记转换为密集向量表示,使模型能够学习输入序列中单词或标记的有意义的表示。
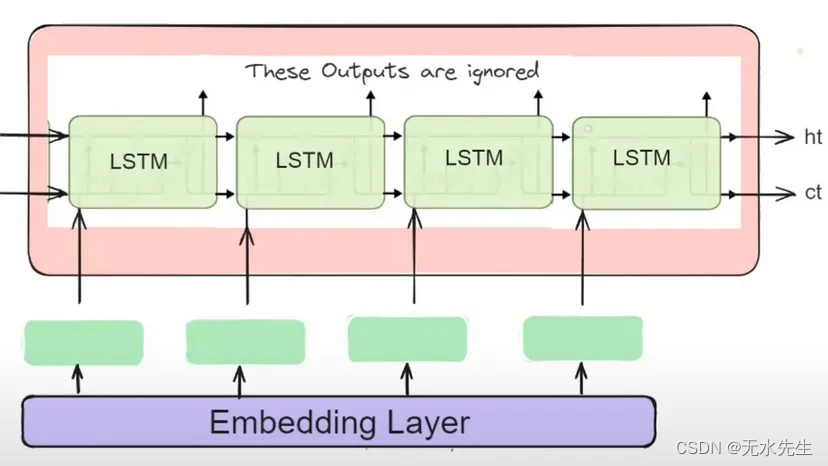
通过使用可训练的嵌入层并探索预训练词嵌入或上下文嵌入等技术,我们可以丰富输入表示,使模型能够更有效地捕获细微的语义和句法信息。此增强功能有助于更好地理解和生成顺序数据。
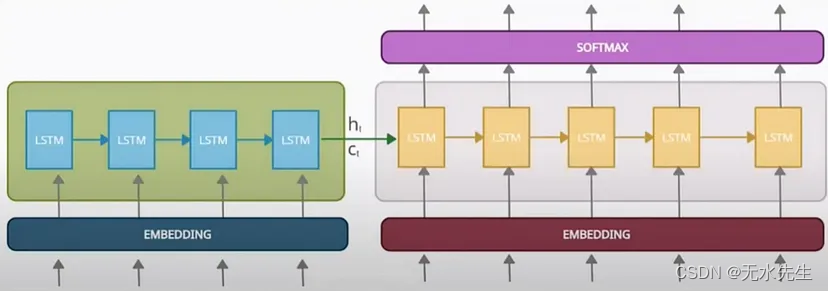
使用嵌入的编码器解码器架构的详细架构
4.2. 深度 LSTM 的使用:
LSTM 是递归神经网络 (RNN) 变体,以其捕获序列数据中长程依赖关系的能力而闻名。深化 LSTM 层使模型能够学习输入和输出序列的分层表示,从而提高性能。
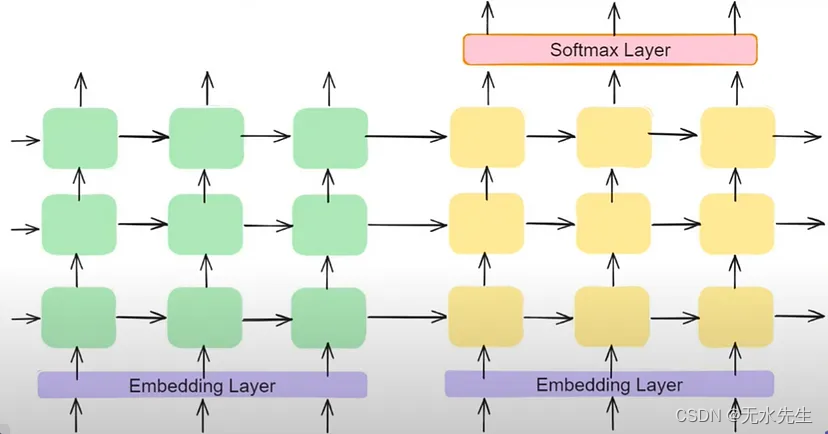
编码器解码器架构的详细架构,使用嵌入和深化 LSTM 来捕获复杂模式
增加 LSTM 层的深度并结合残差连接或层归一化等技术有助于缓解梯度消失等问题,并促进更深层网络的训练。这些增强功能使模型能够学习数据中更复杂的模式和依赖关系,从而更好地生成和理解序列。
4.3.反转输入:
在某些情况下,反转机器翻译中的输入序列(例如英语到印地语或英语到法语的转换)有助于捕获长期依赖关系和缓解梯度消失问题,从而提高模型性能。
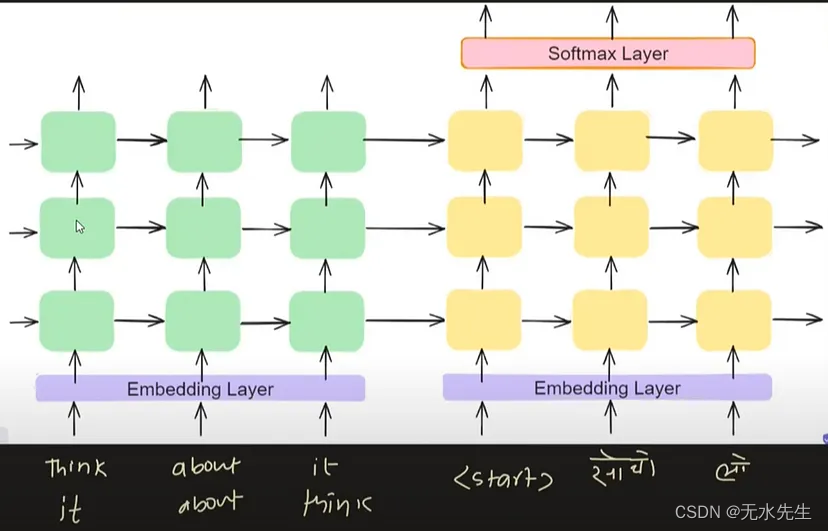
但是,其有效性可能因语言特征和数据集复杂性而异,并且可能无法在所有方案中始终如一地提高性能。必须进行仔细的评估和实验,以确定反转输入序列是否对特定任务和数据集有益。
希望您现在已经了解了编码器解码器的概念。现在,如果你阅读了 Ilya Sutskever 的著名研究论文***"*** Sequence to Sequence Learning with Neural Networks",那么你肯定会很好地理解这篇论文的概念。下面我总结了论文的内容:
- **应用于翻译:**该模型专注于将英语翻译成法语,展示了神经机器翻译中序列到序列学习的有效性。
- **特殊句尾符号:**数据集中的每个句子都以唯一的句子结尾符号 ("<EOS>") 结尾,使模型能够识别序列的结尾。
- **数据:**该模型在1200万个句子的子集上进行了训练,其中包括3.48亿个法语单词和3.04亿个英语单词,这些单词来自一个公开可用的数据集。
- **词汇限制:**为了管理计算复杂性,使用了两种语言的固定词汇表,英语有 160,000 个最常用的单词,法语有 80,000 个。不在这些词汇表中的单词被替换为特殊的"UNK"标记。
- **反转输入序列:**在将输入的句子输入模型之前,将输入的句子颠倒过来,发现这显着提高了模型的学习效率,特别是对于较长的句子。
- **单词嵌入 :**该模型使用 1000 维单词嵌入层来表示输入单词,为每个单词提供密集、有意义的表示。
- **架构细节 :**输入(编码器)和输出(解码器)模型都有 4 层,每层包含 1000 个单元,展示了基于 LSTM 的深度架构。
- **输出层和训练:**输出层采用 SoftMax 函数来生成最大词汇表的概率分布。该模型使用这些设置进行端到端训练。
- **性能 --- BLEU 分数 :**该模型的 BLEU 得分为 34.81,超过了基本文件统计机器翻译系统在同一数据集上的 33.30 分,标志着神经机器翻译的重大进步。
五、后记
我相信这篇博客丰富了您对编码器解码器架构的理解。如果您发现此内容的价值,我邀请您保持联系以获取更有见地的帖子。非常感谢您的时间和兴趣。感谢您的阅读!